 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViPlan: A Benchmark for Visual Planning with Symbolic Predicates and Vision-Language Models
May 19, 2025Integrating Large Language Models with symbolic planners is a promising direction for obtaining verifiable and grounded plans compared to planning in natural language, with recent works extending this idea to visual domains using Vision-Language Models (VLMs). However, rigorous comparison between VLM-grounded symbolic approaches and methods that plan directly with a VLM has been hindered by a lack of common environments, evaluation protocols and model coverage. We introduce ViPlan, the first open-source benchmark for Visual Planning with symbolic predicates and VLMs. ViPlan features a series of increasingly challenging tasks in two domains: a visual variant of the classic Blocksworld planning problem and a simulated household robotics environment. We benchmark nine open-source VLM families across multiple sizes, along with selected closed models, evaluating both VLM-grounded symbolic planning and using the models directly to propose actions. We find symbolic planning to outperform direct VLM planning in Blocksworld, where accurate image grounding is crucial, whereas the opposite is true in the household robotics tasks, where commonsense knowledge and the ability to recover from errors are beneficial. Finally, we show that across most models and methods, there is no significant benefit to using Chain-of-Thought prompting, suggesting that current VLMs still struggle with visual reasoning.
All-in-one: Understanding and Generation in Multimodal Reasoning with the MAIA Benchmark
Feb 24, 2025We introduce MAIA (Multimodal AI Assessment), a native-Italian benchmark designed for fine-grained investigation of the reasoning abilities of visual language models on videos. MAIA differs from other available video benchmarks for its design, its reasoning categories, the metric it uses and the language and culture of the videos. It evaluates Vision Language Models (VLMs) on two aligned tasks: a visual statement verification task, and an open-ended visual question-answering task, both on the same set of video-related questions. It considers twelve reasoning categories that aim to disentangle language and vision relations by highlight when one of two alone encodes sufficient information to solve the tasks, when they are both needed and when the full richness of the short video is essential instead of just a part of it. Thanks to its carefully taught design, it evaluates VLMs' consistency and visually grounded natural language comprehension and generation simultaneously through an aggregated metric. Last but not least, the video collection has been carefully selected to reflect the Italian culture and the language data are produced by native-speakers.
Job Shop Scheduling via Deep Reinforcement Learning: a Sequence to Sequence approach
Aug 03, 2023



Job scheduling is a well-known Combinatorial Optimization problem with endless applications. Well planned schedules bring many benefits in the context of automated systems: among others, they limit production costs and waste. Nevertheless, the NP-hardness of this problem makes it essential to use heuristics whose design is difficult, requires specialized knowledge and often produces methods tailored to the specific task. This paper presents an original end-to-end Deep Reinforcement Learning approach to scheduling that automatically learns dispatching rules. Our technique is inspired by natural language encoder-decoder models for sequence processing and has never been used, to the best of our knowledge, for scheduling purposes. We applied and tested our method in particular to some benchmark instances of Job Shop Problem, but this technique is general enough to be potentially used to tackle other different optimal job scheduling tasks with minimal intervention. Results demonstrate that we outperform many classical approaches exploiting priority dispatching rules and show competitive results on state-of-the-art Deep Reinforcement Learning ones.
Regularization-based Pruning of Irrelevant Weights in Deep Neural Architectures
Apr 11, 2022


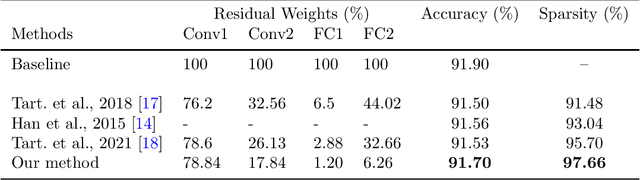
Deep neural networks exploiting millions of parameters are nowadays the norm in deep learning applications. This is a potential issue because of the great amount of computational resources needed for training, and of the possible loss of generalization performance of overparametrized networks. We propose in this paper a method for learning sparse neural topologies via a regularization technique which identifies non relevant weights and selectively shrinks their norm, while performing a classic update for relevant ones. This technique, which is an improvement of classical weight decay, is based on the definition of a regularization term which can be added to any loss functional regardless of its form, resulting in a unified general framework exploitable in many different contexts. The actual elimination of parameters identified as irrelevant is handled by an iterative pruning algorithm. We tested the proposed technique on different image classification and Natural language generation tasks, obtaining results on par or better then competitors in terms of sparsity and metrics, while achieving strong models compression.
Retrieval-Augmented Transformer-XL for Close-Domain Dialog Generation
May 19, 2021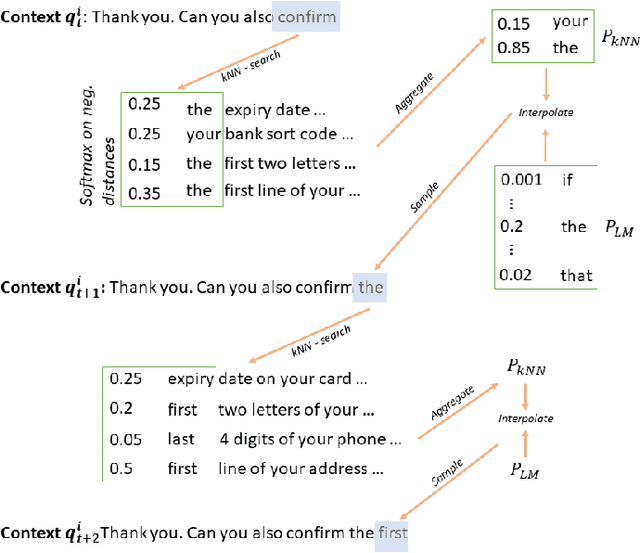

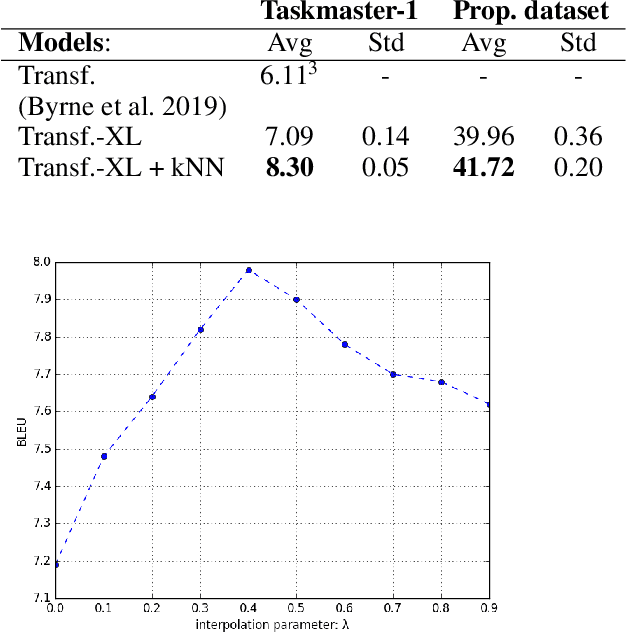
Transformer-based models have demonstrated excellent capabilities of capturing patterns and structures in natural language generation and achieved state-of-the-art results in many tasks. In this paper we present a transformer-based model for multi-turn dialog response generation. Our solution is based on a hybrid approach which augments a transformer-based generative model with a novel retrieval mechanism, which leverages the memorized information in the training data via k-Nearest Neighbor search. Our system is evaluated on two datasets made by customer/assistant dialogs: the Taskmaster-1, released by Google and holding high quality, goal-oriented conversational data and a proprietary dataset collected from a real customer service call center. Both achieve better BLEU scores over strong baselines.
Copy mechanism and tailored training for character-based data-to-text generation
Apr 26, 2019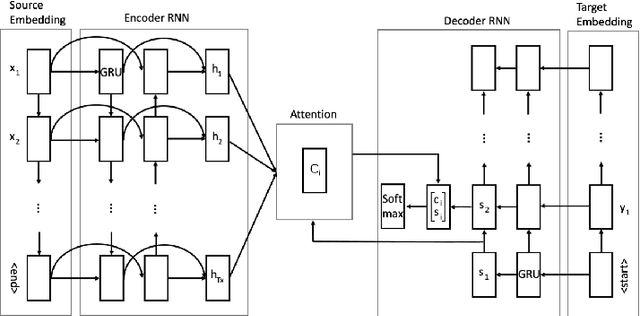
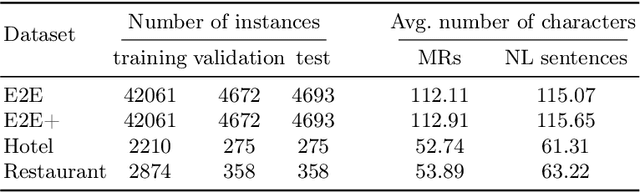
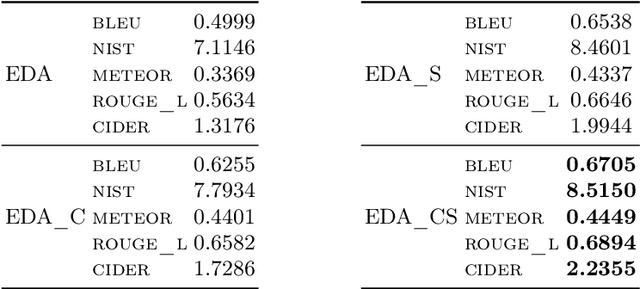
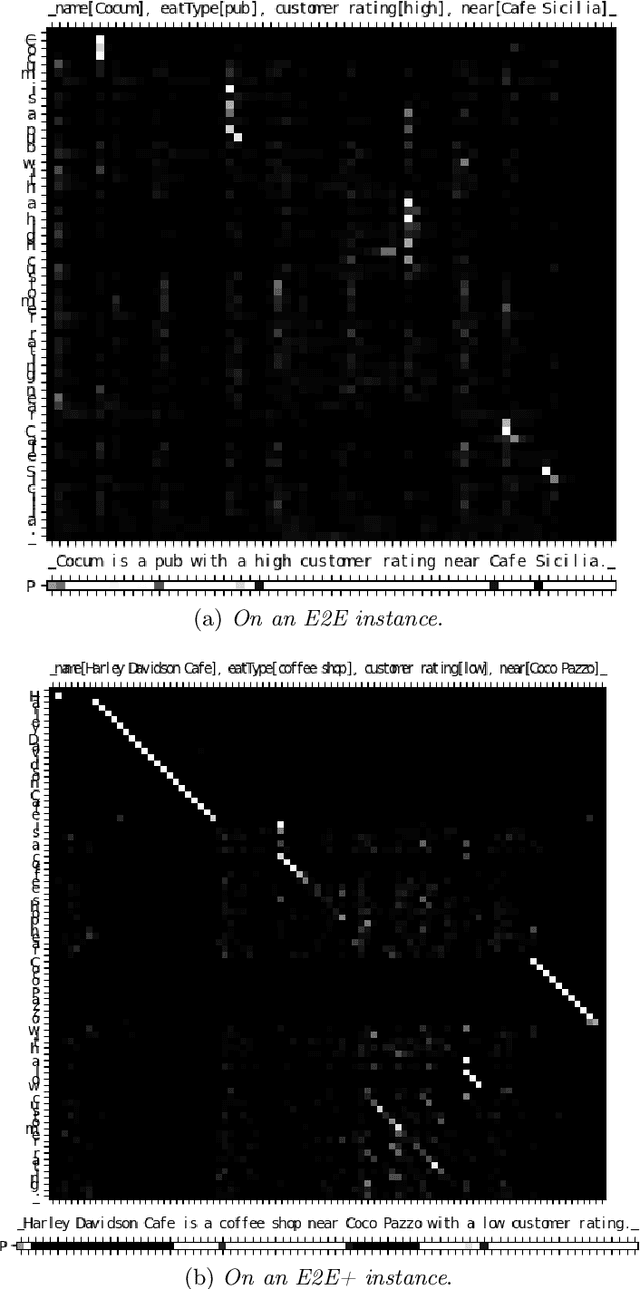
In the last few years, many different methods have been focusing on using deep recurrent neural networks for natural language generation. The most widely used sequence-to-sequence neural methods are word-based: as such, they need a pre-processing step called delexicalization (conversely, relexicalization) to deal with uncommon or unknown words. These forms of processing, however, give rise to models that depend on the vocabulary used and are not completely neural. In this work, we present an end-to-end sequence-to-sequence model with attention mechanism which reads and generates at a character level, no longer requiring delexicalization, tokenization, nor even lowercasing. Moreover, since characters constitute the common "building blocks" of every text, it also allows a more general approach to text generation, enabling the possibility to exploit transfer learning for training. These skills are obtained thanks to two major features: (i) the possibility to alternate between the standard generation mechanism and a copy one, which allows to directly copy input facts to produce outputs, and (ii) the use of an original training pipeline that further improves the quality of the generated texts. We also introduce a new dataset called E2E+, designed to highlight the copying capabilities of character-based models, that is a modified version of the well-known E2E dataset used in the E2E Challenge. We tested our model according to five broadly accepted metrics (including the widely used bleu), showing that it yields competitive performance with respect to both character-based and word-based approaches.