 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVRPAgent: LLM-Driven Discovery of Heuristic Operators for Vehicle Routing Problems
Oct 08, 2025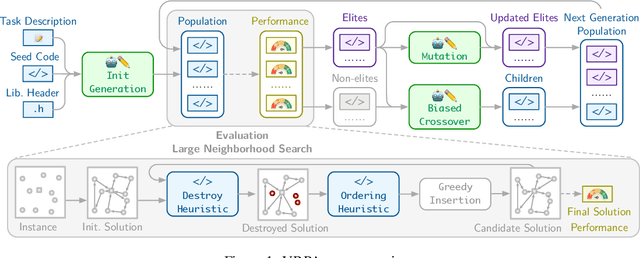
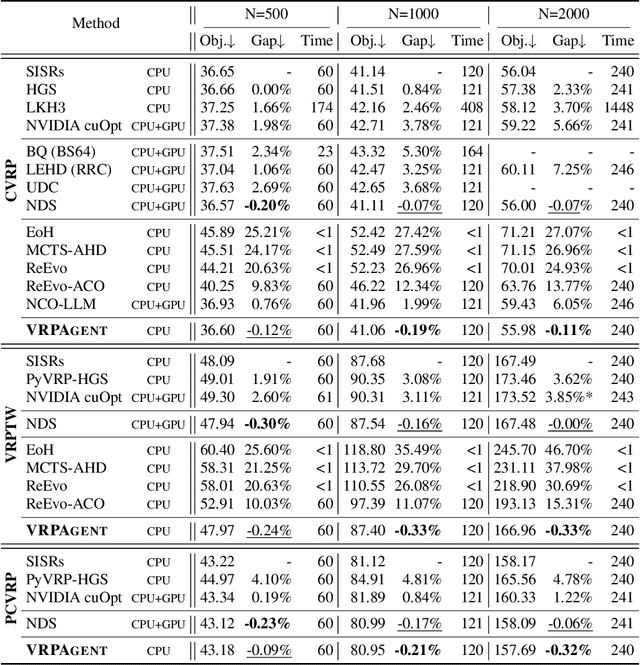
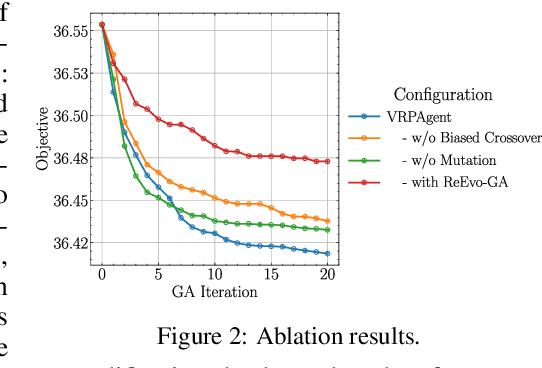
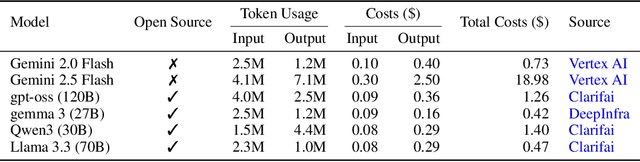
Designing high-performing heuristics for vehicle routing problems (VRPs) is a complex task that requires both intuition and deep domain knowledge. Large language model (LLM)-based code generation has recently shown promise across many domains, but it still falls short of producing heuristics that rival those crafted by human experts. In this paper, we propose VRPAgent, a framework that integrates LLM-generated components into a metaheuristic and refines them through a novel genetic search. By using the LLM to generate problem-specific operators, embedded within a generic metaheuristic framework, VRPAgent keeps tasks manageable, guarantees correctness, and still enables the discovery of novel and powerful strategies. Across multiple problems, including the capacitated VRP, the VRP with time windows, and the prize-collecting VRP, our method discovers heuristic operators that outperform handcrafted methods and recent learning-based approaches while requiring only a single CPU core. To our knowledge, \VRPAgent is the first LLM-based paradigm to advance the state-of-the-art in VRPs, highlighting a promising future for automated heuristics discovery.
Leveraging Large Language Models to Geolocate Linguistic Variations in Social Media Posts
Jul 22, 2024Geolocalization of social media content is the task of determining the geographical location of a user based on textual data, that may show linguistic variations and informal language. In this project, we address the GeoLingIt challenge of geolocalizing tweets written in Italian by leveraging large language models (LLMs). GeoLingIt requires the prediction of both the region and the precise coordinates of the tweet. Our approach involves fine-tuning pre-trained LLMs to simultaneously predict these geolocalization aspects. By integrating innovative methodologies, we enhance the models' ability to understand the nuances of Italian social media text to improve the state-of-the-art in this domain. This work is conducted as part of the Large Language Models course at the Bertinoro International Spring School 2024. We make our code publicly available on GitHub https://github.com/dawoz/geolingit-biss2024.
Job Shop Scheduling via Deep Reinforcement Learning: a Sequence to Sequence approach
Aug 03, 2023



Job scheduling is a well-known Combinatorial Optimization problem with endless applications. Well planned schedules bring many benefits in the context of automated systems: among others, they limit production costs and waste. Nevertheless, the NP-hardness of this problem makes it essential to use heuristics whose design is difficult, requires specialized knowledge and often produces methods tailored to the specific task. This paper presents an original end-to-end Deep Reinforcement Learning approach to scheduling that automatically learns dispatching rules. Our technique is inspired by natural language encoder-decoder models for sequence processing and has never been used, to the best of our knowledge, for scheduling purposes. We applied and tested our method in particular to some benchmark instances of Job Shop Problem, but this technique is general enough to be potentially used to tackle other different optimal job scheduling tasks with minimal intervention. Results demonstrate that we outperform many classical approaches exploiting priority dispatching rules and show competitive results on state-of-the-art Deep Reinforcement Learning ones.