 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJob Shop Scheduling via Deep Reinforcement Learning: a Sequence to Sequence approach
Aug 03, 2023



Job scheduling is a well-known Combinatorial Optimization problem with endless applications. Well planned schedules bring many benefits in the context of automated systems: among others, they limit production costs and waste. Nevertheless, the NP-hardness of this problem makes it essential to use heuristics whose design is difficult, requires specialized knowledge and often produces methods tailored to the specific task. This paper presents an original end-to-end Deep Reinforcement Learning approach to scheduling that automatically learns dispatching rules. Our technique is inspired by natural language encoder-decoder models for sequence processing and has never been used, to the best of our knowledge, for scheduling purposes. We applied and tested our method in particular to some benchmark instances of Job Shop Problem, but this technique is general enough to be potentially used to tackle other different optimal job scheduling tasks with minimal intervention. Results demonstrate that we outperform many classical approaches exploiting priority dispatching rules and show competitive results on state-of-the-art Deep Reinforcement Learning ones.
Regularization-based Pruning of Irrelevant Weights in Deep Neural Architectures
Apr 11, 2022


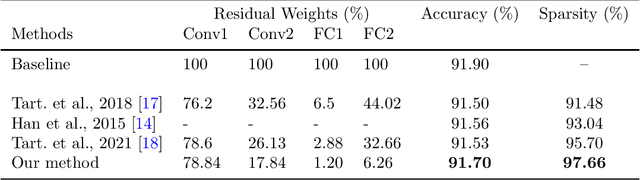
Deep neural networks exploiting millions of parameters are nowadays the norm in deep learning applications. This is a potential issue because of the great amount of computational resources needed for training, and of the possible loss of generalization performance of overparametrized networks. We propose in this paper a method for learning sparse neural topologies via a regularization technique which identifies non relevant weights and selectively shrinks their norm, while performing a classic update for relevant ones. This technique, which is an improvement of classical weight decay, is based on the definition of a regularization term which can be added to any loss functional regardless of its form, resulting in a unified general framework exploitable in many different contexts. The actual elimination of parameters identified as irrelevant is handled by an iterative pruning algorithm. We tested the proposed technique on different image classification and Natural language generation tasks, obtaining results on par or better then competitors in terms of sparsity and metrics, while achieving strong models compression.
Retrieval-Augmented Transformer-XL for Close-Domain Dialog Generation
May 19, 2021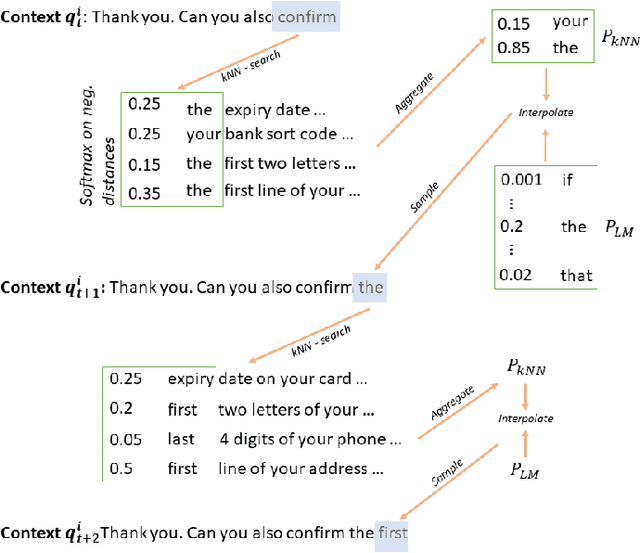

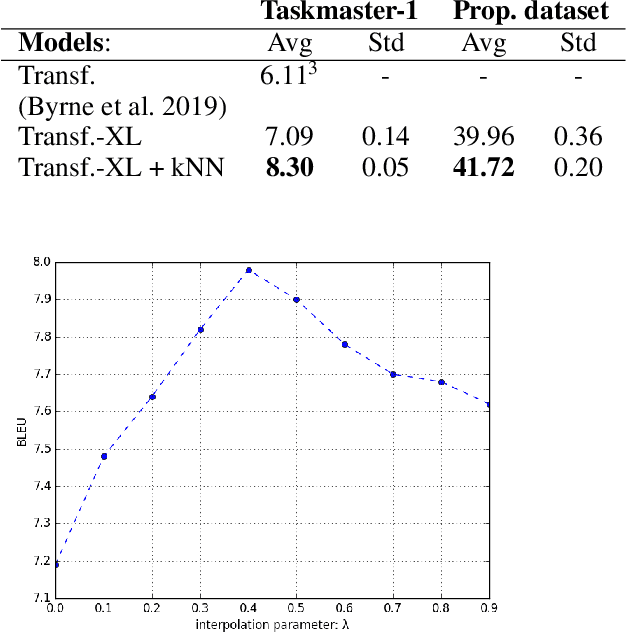
Transformer-based models have demonstrated excellent capabilities of capturing patterns and structures in natural language generation and achieved state-of-the-art results in many tasks. In this paper we present a transformer-based model for multi-turn dialog response generation. Our solution is based on a hybrid approach which augments a transformer-based generative model with a novel retrieval mechanism, which leverages the memorized information in the training data via k-Nearest Neighbor search. Our system is evaluated on two datasets made by customer/assistant dialogs: the Taskmaster-1, released by Google and holding high quality, goal-oriented conversational data and a proprietary dataset collected from a real customer service call center. Both achieve better BLEU scores over strong baselines.
Controlling Hallucinations at Word Level in Data-to-Text Generation
Feb 04, 2021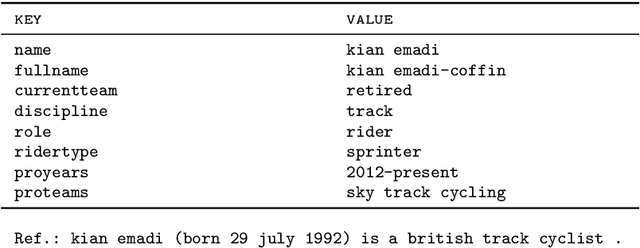
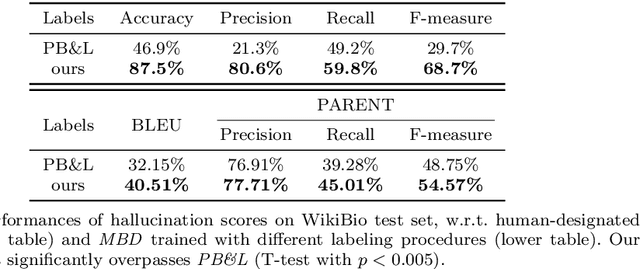
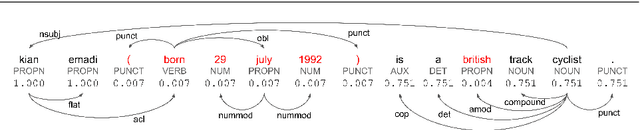
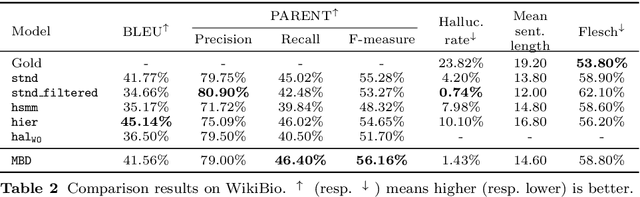
Data-to-Text Generation (DTG) is a subfield of Natural Language Generation aiming at transcribing structured data in natural language descriptions. The field has been recently boosted by the use of neural-based generators which exhibit on one side great syntactic skills without the need of hand-crafted pipelines; on the other side, the quality of the generated text reflects the quality of the training data, which in realistic settings only offer imperfectly aligned structure-text pairs. Consequently, state-of-art neural models include misleading statements - usually called hallucinations - in their outputs. The control of this phenomenon is today a major challenge for DTG, and is the problem addressed in the paper. Previous work deal with this issue at the instance level: using an alignment score for each table-reference pair. In contrast, we propose a finer-grained approach, arguing that hallucinations should rather be treated at the word level. Specifically, we propose a Multi-Branch Decoder which is able to leverage word-level labels to learn the relevant parts of each training instance. These labels are obtained following a simple and efficient scoring procedure based on co-occurrence analysis and dependency parsing. Extensive evaluations, via automated metrics and human judgment on the standard WikiBio benchmark, show the accuracy of our alignment labels and the effectiveness of the proposed Multi-Branch Decoder. Our model is able to reduce and control hallucinations, while keeping fluency and coherence in generated texts. Further experiments on a degraded version of ToTTo show that our model could be successfully used on very noisy settings.
Copy mechanism and tailored training for character-based data-to-text generation
Apr 26, 2019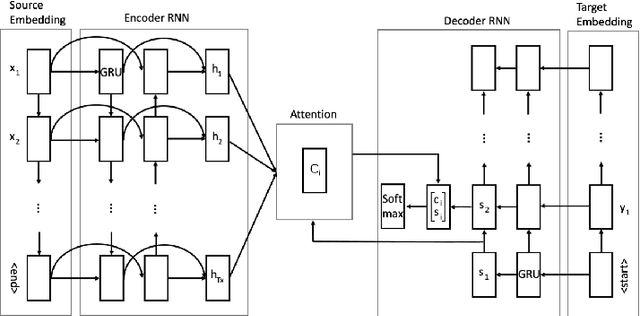
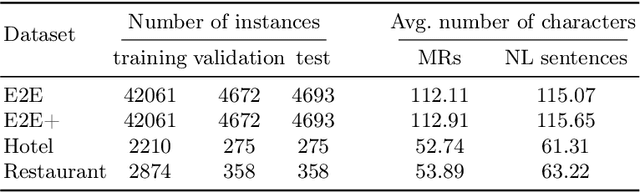
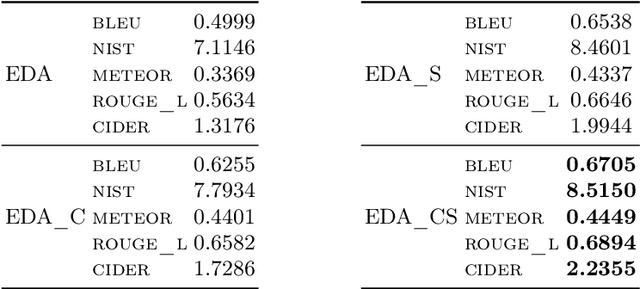
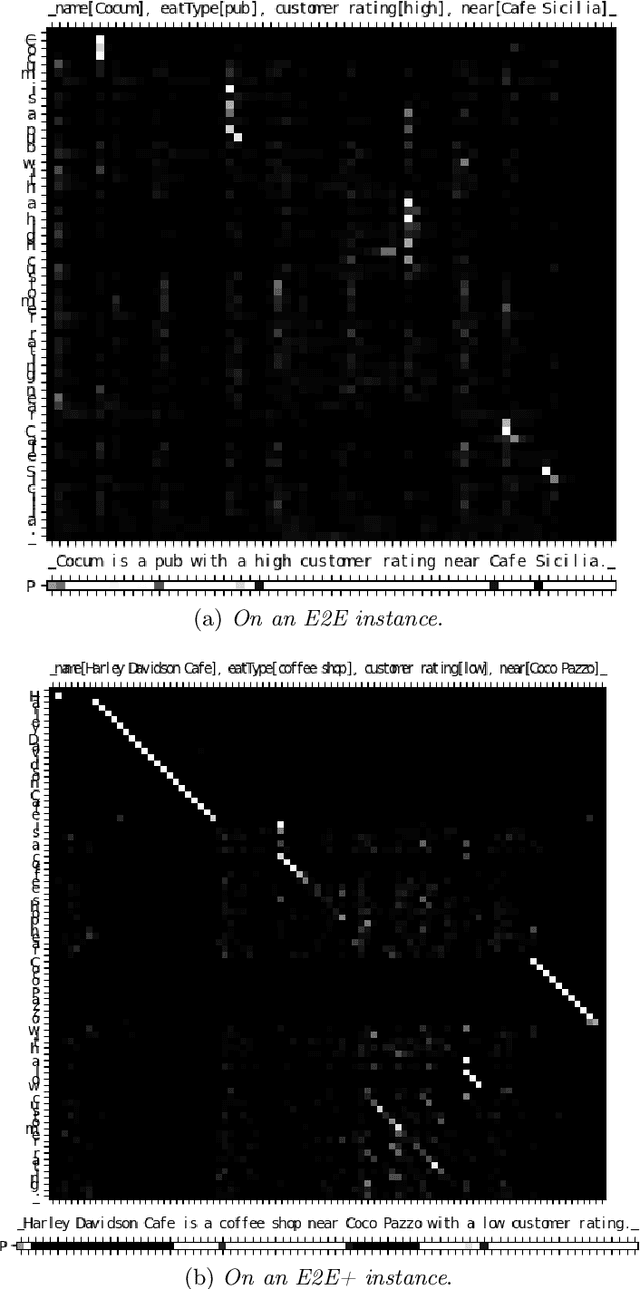
In the last few years, many different methods have been focusing on using deep recurrent neural networks for natural language generation. The most widely used sequence-to-sequence neural methods are word-based: as such, they need a pre-processing step called delexicalization (conversely, relexicalization) to deal with uncommon or unknown words. These forms of processing, however, give rise to models that depend on the vocabulary used and are not completely neural. In this work, we present an end-to-end sequence-to-sequence model with attention mechanism which reads and generates at a character level, no longer requiring delexicalization, tokenization, nor even lowercasing. Moreover, since characters constitute the common "building blocks" of every text, it also allows a more general approach to text generation, enabling the possibility to exploit transfer learning for training. These skills are obtained thanks to two major features: (i) the possibility to alternate between the standard generation mechanism and a copy one, which allows to directly copy input facts to produce outputs, and (ii) the use of an original training pipeline that further improves the quality of the generated texts. We also introduce a new dataset called E2E+, designed to highlight the copying capabilities of character-based models, that is a modified version of the well-known E2E dataset used in the E2E Challenge. We tested our model according to five broadly accepted metrics (including the widely used bleu), showing that it yields competitive performance with respect to both character-based and word-based approaches.
OCReP: An Optimally Conditioned Regularization for Pseudoinversion Based Neural Training
Aug 25, 2015
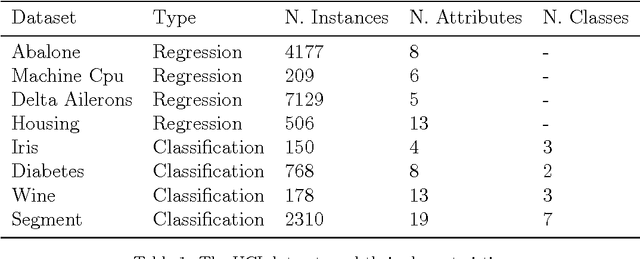
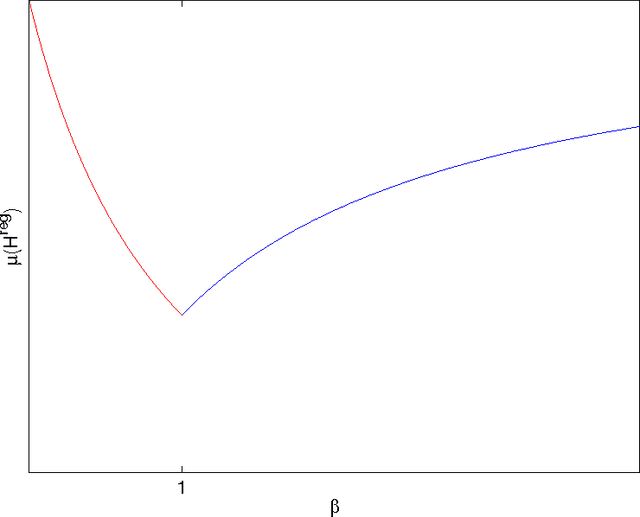
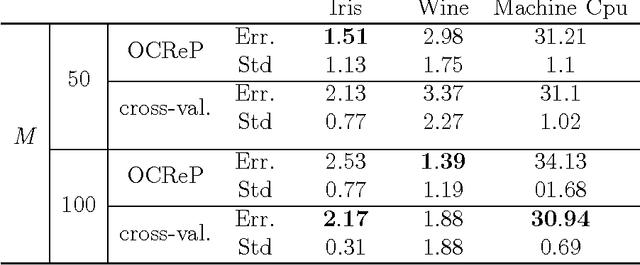
In this paper we consider the training of single hidden layer neural networks by pseudoinversion, which, in spite of its popularity, is sometimes affected by numerical instability issues. Regularization is known to be effective in such cases, so that we introduce, in the framework of Tikhonov regularization, a matricial reformulation of the problem which allows us to use the condition number as a diagnostic tool for identification of instability. By imposing well-conditioning requirements on the relevant matrices, our theoretical analysis allows the identification of an optimal value for the regularization parameter from the standpoint of stability. We compare with the value derived by cross-validation for overfitting control and optimisation of the generalization performance. We test our method for both regression and classification tasks. The proposed method is quite effective in terms of predictivity, often with some improvement on performance with respect to the reference cases considered. This approach, due to analytical determination of the regularization parameter, dramatically reduces the computational load required by many other techniques.