 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tokens to Concepts: Leveraging SAE for SPLADE
Apr 23, 2026Learned Sparse IR models, such as SPLADE, offer an excellent efficiency-effectiveness tradeoff. However, they rely on the underlying backbone vocabulary, which might hinder performance (polysemicity and synonymy) and pose a challenge for multi-lingual and multi-modal usages. To solve this limitation, we propose to replace the backbone vocabulary with a latent space of semantic concepts learned using Sparse Auto-Encoders (SAE). Throughout this paper, we study the compatibility of these 2 concepts, explore training approaches, and analyze the differences between our SAE-SPLADE model and traditional SPLADE models. Our experiments demonstrate that SAE-SPLADE achieves retrieval performance comparable to SPLADE on both in-domain and out-of-domain tasks while offering improved efficiency.
Reproducing and Comparing Distillation Techniques for Cross-Encoders
Mar 03, 2026Recent advances in Information Retrieval have established transformer-based cross-encoders as a keystone in IR. Recent studies have focused on knowledge distillation and showed that, with the right strategy, traditional cross-encoders could reach the level of effectiveness of LLM re-rankers. Yet, comparisons with previous training strategies, including distillation from strong cross-encoder teachers, remain unclear. In addition, few studies cover a similar range of backbone encoders, while substantial improvements have been made in this area since BERT. This lack of comprehensive studies in controlled environments makes it difficult to identify robust design choices. In this work, we reproduce \citet{schlattRankDistiLLMClosingEffectiveness2025} LLM-based distillation strategy and compare it to \citet{hofstatterImprovingEfficientNeural2020} approach based on an ensemble of cross-encoder teachers, as well as other supervised objectives, to fine-tune a large range of cross-encoders, from the original BERT and its follow-ups RoBERTa, ELECTRA and DeBERTa-v3, to the more recent ModernBERT. We evaluate all models on both in-domain (TREC-DL and MS~MARCO dev) and out-of-domain datasets (BEIR, LoTTE, and Robust04). Our results show that objectives emphasizing relative comparisons -- pairwise MarginMSE and listwise InfoNCE -- consistently outperform pointwise baselines across all backbones and evaluation settings, and that objective choice can yield gains comparable to scaling the backbone architecture.
MICE: Minimal Interaction Cross-Encoders for efficient Re-ranking
Feb 18, 2026Cross-encoders deliver state-of-the-art ranking effectiveness in information retrieval, but have a high inference cost. This prevents them from being used as first-stage rankers, but also incurs a cost when re-ranking documents. Prior work has addressed this bottleneck from two largely separate directions: accelerating cross-encoder inference by sparsifying the attention process or improving first-stage retrieval effectiveness using more complex models, e.g. late-interaction ones. In this work, we propose to bridge these two approaches, based on an in-depth understanding of the internal mechanisms of cross-encoders. Starting from cross-encoders, we show that it is possible to derive a new late-interaction-like architecture by carefully removing detrimental or unnecessary interactions. We name this architecture MICE (Minimal Interaction Cross-Encoders). We extensively evaluate MICE across both in-domain (ID) and out-of-domain (OOD) datasets. MICE decreases fourfold the inference latency compared to standard cross-encoders, matching late-interaction models like ColBERT while retaining most of cross-encoder ID effectiveness and demonstrating superior generalization abilities in OOD.
RAC: Retrieval-Augmented Clarification for Faithful Conversational Search
Jan 16, 2026Clarification questions help conversational search systems resolve ambiguous or underspecified user queries. While prior work has focused on fluency and alignment with user intent, especially through facet extraction, much less attention has been paid to grounding clarifications in the underlying corpus. Without such grounding, systems risk asking questions that cannot be answered from the available documents. We introduce RAC (Retrieval-Augmented Clarification), a framework for generating corpus-faithful clarification questions. After comparing several indexing strategies for retrieval, we fine-tune a large language model to make optimal use of research context and to encourage the generation of evidence-based question. We then apply contrastive preference optimization to favor questions supported by retrieved passages over ungrounded alternatives. Evaluated on four benchmarks, RAC demonstrate significant improvements over baselines. In addition to LLM-as-Judge assessments, we introduce novel metrics derived from NLI and data-to-text to assess how well questions are anchored in the context, and we demonstrate that our approach consistently enhances faithfulness.
Clarifying Ambiguities: on the Role of Ambiguity Types in Prompting Methods for Clarification Generation
Apr 16, 2025



In information retrieval (IR), providing appropriate clarifications to better understand users' information needs is crucial for building a proactive search-oriented dialogue system. Due to the strong in-context learning ability of large language models (LLMs), recent studies investigate prompting methods to generate clarifications using few-shot or Chain of Thought (CoT) prompts. However, vanilla CoT prompting does not distinguish the characteristics of different information needs, making it difficult to understand how LLMs resolve ambiguities in user queries. In this work, we focus on the concept of ambiguity for clarification, seeking to model and integrate ambiguities in the clarification process. To this end, we comprehensively study the impact of prompting schemes based on reasoning and ambiguity for clarification. The idea is to enhance the reasoning abilities of LLMs by limiting CoT to predict first ambiguity types that can be interpreted as instructions to clarify, then correspondingly generate clarifications. We name this new prompting scheme Ambiguity Type-Chain of Thought (AT-CoT). Experiments are conducted on various datasets containing human-annotated clarifying questions to compare AT-CoT with multiple baselines. We also perform user simulations to implicitly measure the quality of generated clarifications under various IR scenarios.
VIPER: Visual Perception and Explainable Reasoning for Sequential Decision-Making
Mar 19, 2025While Large Language Models (LLMs) excel at reasoning on text and Vision-Language Models (VLMs) are highly effective for visual perception, applying those models for visual instruction-based planning remains a widely open problem. In this paper, we introduce VIPER, a novel framework for multimodal instruction-based planning that integrates VLM-based perception with LLM-based reasoning. Our approach uses a modular pipeline where a frozen VLM generates textual descriptions of image observations, which are then processed by an LLM policy to predict actions based on the task goal. We fine-tune the reasoning module using behavioral cloning and reinforcement learning, improving our agent's decision-making capabilities. Experiments on the ALFWorld benchmark show that VIPER significantly outperforms state-of-the-art visual instruction-based planners while narrowing the gap with purely text-based oracles. By leveraging text as an intermediate representation, VIPER also enhances explainability, paving the way for a fine-grained analysis of perception and reasoning components.
SCOPE: A Self-supervised Framework for Improving Faithfulness in Conditional Text Generation
Feb 19, 2025Large Language Models (LLMs), when used for conditional text generation, often produce hallucinations, i.e., information that is unfaithful or not grounded in the input context. This issue arises in typical conditional text generation tasks, such as text summarization and data-to-text generation, where the goal is to produce fluent text based on contextual input. When fine-tuned on specific domains, LLMs struggle to provide faithful answers to a given context, often adding information or generating errors. One underlying cause of this issue is that LLMs rely on statistical patterns learned from their training data. This reliance can interfere with the model's ability to stay faithful to a provided context, leading to the generation of ungrounded information. We build upon this observation and introduce a novel self-supervised method for generating a training set of unfaithful samples. We then refine the model using a training process that encourages the generation of grounded outputs over unfaithful ones, drawing on preference-based training. Our approach leads to significantly more grounded text generation, outperforming existing self-supervised techniques in faithfulness, as evaluated through automatic metrics, LLM-based assessments, and human evaluations.
Reinforcement Learning for Aligning Large Language Models Agents with Interactive Environments: Quantifying and Mitigating Prompt Overfitting
Oct 29, 2024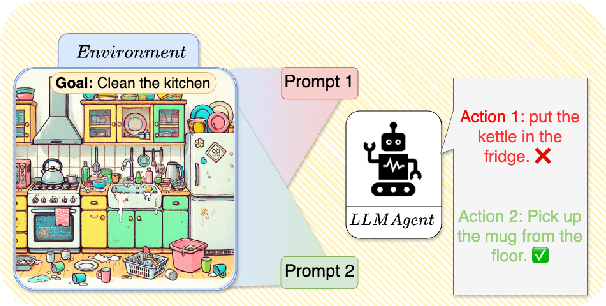
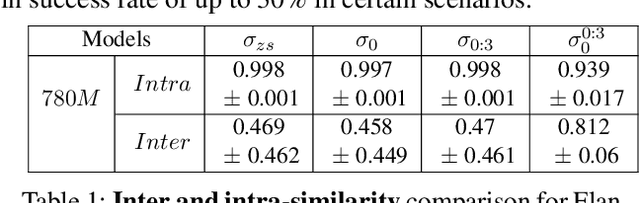
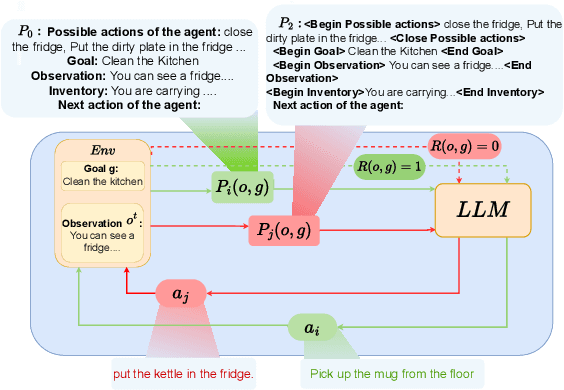
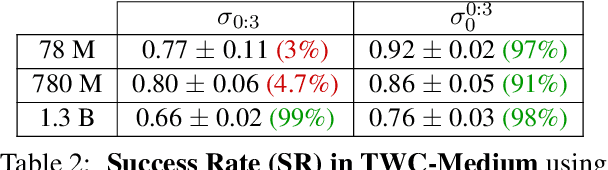
Reinforcement learning (RL) is a promising approach for aligning large language models (LLMs) knowledge with sequential decision-making tasks. However, few studies have thoroughly investigated the impact on LLM agents capabilities of fine-tuning them with RL in a specific environment. In this paper, we propose a novel framework to analyze the sensitivity of LLMs to prompt formulations following RL training in a textual environment. Our findings reveal that the performance of LLMs degrades when faced with prompt formulations different from those used during the RL training phase. Besides, we analyze the source of this sensitivity by examining the model's internal representations and salient tokens. Finally, we propose to use a contrastive loss to mitigate this sensitivity and improve the robustness and generalization capabilities of LLMs.
2D or not 2D: How Does the Dimensionality of Gesture Representation Affect 3D Co-Speech Gesture Generation?
Sep 16, 2024Co-speech gestures are fundamental for communication. The advent of recent deep learning techniques has facilitated the creation of lifelike, synchronous co-speech gestures for Embodied Conversational Agents. "In-the-wild" datasets, aggregating video content from platforms like YouTube via human pose detection technologies, provide a feasible solution by offering 2D skeletal sequences aligned with speech. Concurrent developments in lifting models enable the conversion of these 2D sequences into 3D gesture databases. However, it is important to note that the 3D poses estimated from the 2D extracted poses are, in essence, approximations of the ground-truth, which remains in the 2D domain. This distinction raises questions about the impact of gesture representation dimensionality on the quality of generated motions - a topic that, to our knowledge, remains largely unexplored. Our study examines the effect of using either 2D or 3D joint coordinates as training data on the performance of speech-to-gesture deep generative models. We employ a lifting model for converting generated 2D pose sequences into 3D and assess how gestures created directly in 3D stack up against those initially generated in 2D and then converted to 3D. We perform an objective evaluation using widely used metrics in the gesture generation field as well as a user study to qualitatively evaluate the different approaches.
An Evaluation Framework for Attributed Information Retrieval using Large Language Models
Sep 12, 2024With the growing success of Large Language models (LLMs) in information-seeking scenarios, search engines are now adopting generative approaches to provide answers along with in-line citations as attribution. While existing work focuses mainly on attributed question answering, in this paper, we target information-seeking scenarios which are often more challenging due to the open-ended nature of the queries and the size of the label space in terms of the diversity of candidate-attributed answers per query. We propose a reproducible framework to evaluate and benchmark attributed information seeking, using any backbone LLM, and different architectural designs: (1) Generate (2) Retrieve then Generate, and (3) Generate then Retrieve. Experiments using HAGRID, an attributed information-seeking dataset, show the impact of different scenarios on both the correctness and attributability of answers.