 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and typifying demographic unfairness in phoneme-level embeddings of self-supervised speech recognition models
Apr 24, 2026Modern automatic speech recognition (ASR) systems have been observed to function better for certain speaker groups (SGs) than others, despite recent gains in overall performance. One potential impediment to progress towards fairer ASR is a more nuanced understanding of the types of modeling errors that speech encoder models make, and in particular the difference between the structure of embeddings for high-performance and low-performance SGs. This paper proposes a framework typifying two types of error that can occur in modeling phonemes in ASR systems: random error/high variance in phoneme embedding, vs systematic error/embedding bias. We find that training phoneme classification probes only on a single, typically disadvantaged SG, sometimes improves performance for that SG, which is evidence for the existence of SG-level bias in phoneme embeddings. On the other hand, we find that speakers and SGs with higher levels of phoneme variance are the same as those with worse phoneme prediction accuracy. We conclude that both types of error are present in phoneme embeddings and both are candidate causes for SG-level unfairness in ASR, though random error is likely a greater hindrance to fairness than systematic error. Furthermore, we find that finetuning encoder models using a fairness-enhancing algorithm (domain enhancing and adversarial training) changes neither the benefits of in-domain phoneme classification probe training, nor measured levels of random embedding error.
Where Do Self-Supervised Speech Models Become Unfair?
Apr 20, 2026Speech encoder models are known to model members of some speaker groups (SGs) better than others. However, there has been little work in establishing why this occurs on a technological level. To our knowledge, we present the first layerwise fairness analysis of pretrained self-supervised speech encoder models (S3Ms), probing each embedding layer for speaker identification (SID) automatic speech recognition (ASR). We find S3Ms produce embeddings biased against certain SGs for both tasks, starting at the very first latent layers. Furthermore, we find opposite patterns of layerwise bias for SID vs ASR for all models in our study: SID bias is minimized in layers that minimize overall SID error; on the other hand, ASR bias is maximized in layers that minimize overall ASR error. The inverse bias/error relationship for ASR is unaffected when probing S3Ms that are finetuned for ASR, suggesting SG-level bias is established during pretraining and is difficult to remove.
Polynomial Mixing for Efficient Self-supervised Speech Encoders
Feb 28, 2026State-of-the-art speech-to-text models typically employ Transformer-based encoders that model token dependencies via self-attention mechanisms. However, the quadratic complexity of self-attention in both memory and computation imposes significant constraints on scalability. In this work, we propose a novel token-mixing mechanism, the Polynomial Mixer (PoM), as a drop-in replacement for multi-head self-attention. PoM computes a polynomial representation of the input with linear complexity with respect to the input sequence length. We integrate PoM into a self-supervised speech representation learning framework based on BEST-RQ and evaluate its performance on downstream speech recognition tasks. Experimental results demonstrate that PoM achieves a competitive word error rate compared to full self-attention and other linear-complexity alternatives, offering an improved trade-off between performance and efficiency in time and memory.
Forward Only Learning for Orthogonal Neural Networks of any Depth
Dec 19, 2025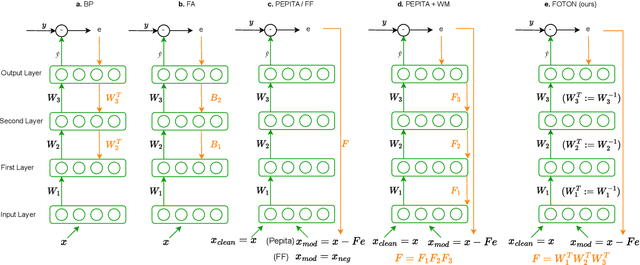
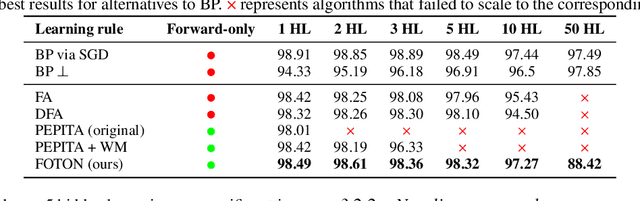

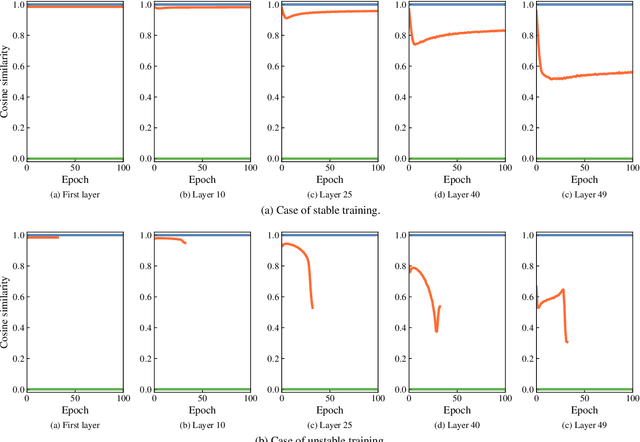
Backpropagation is still the de facto algorithm used today to train neural networks. With the exponential growth of recent architectures, the computational cost of this algorithm also becomes a burden. The recent PEPITA and forward-only frameworks have proposed promising alternatives, but they failed to scale up to a handful of hidden layers, yet limiting their use. In this paper, we first analyze theoretically the main limitations of these approaches. It allows us the design of a forward-only algorithm, which is equivalent to backpropagation under the linear and orthogonal assumptions. By relaxing the linear assumption, we then introduce FOTON (Forward-Only Training of Orthogonal Networks) that bridges the gap with the backpropagation algorithm. Experimental results show that it outperforms PEPITA, enabling us to train neural networks of any depth, without the need for a backward pass. Moreover its performance on convolutional networks clearly opens up avenues for its application to more advanced architectures. The code is open-sourced at https://github.com/p0lcAi/FOTON .
On the MIA Vulnerability Gap Between Private GANs and Diffusion Models
Sep 03, 2025Generative Adversarial Networks (GANs) and diffusion models have emerged as leading approaches for high-quality image synthesis. While both can be trained under differential privacy (DP) to protect sensitive data, their sensitivity to membership inference attacks (MIAs), a key threat to data confidentiality, remains poorly understood. In this work, we present the first unified theoretical and empirical analysis of the privacy risks faced by differentially private generative models. We begin by showing, through a stability-based analysis, that GANs exhibit fundamentally lower sensitivity to data perturbations than diffusion models, suggesting a structural advantage in resisting MIAs. We then validate this insight with a comprehensive empirical study using a standardized MIA pipeline to evaluate privacy leakage across datasets and privacy budgets. Our results consistently reveal a marked privacy robustness gap in favor of GANs, even in strong DP regimes, highlighting that model type alone can critically shape privacy leakage.
Linear Attention with Global Context: A Multipole Attention Mechanism for Vision and Physics
Jul 03, 2025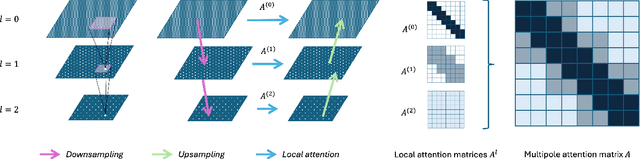


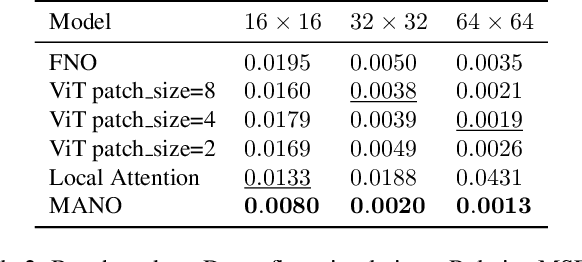
Transformers have become the de facto standard for a wide range of tasks, from image classification to physics simulations. Despite their impressive performance, the quadratic complexity of standard Transformers in both memory and time with respect to the input length makes them impractical for processing high-resolution inputs. Therefore, several variants have been proposed, the most successful relying on patchification, downsampling, or coarsening techniques, often at the cost of losing the finest-scale details. In this work, we take a different approach. Inspired by state-of-the-art techniques in $n$-body numerical simulations, we cast attention as an interaction problem between grid points. We introduce the Multipole Attention Neural Operator (MANO), which computes attention in a distance-based multiscale fashion. MANO maintains, in each attention head, a global receptive field and achieves linear time and memory complexity with respect to the number of grid points. Empirical results on image classification and Darcy flows demonstrate that MANO rivals state-of-the-art models such as ViT and Swin Transformer, while reducing runtime and peak memory usage by orders of magnitude. We open source our code for reproducibility at https://github.com/AlexColagrande/MANO.
Bridging the Theoretical Gap in Randomized Smoothing
Apr 03, 2025Randomized smoothing has become a leading approach for certifying adversarial robustness in machine learning models. However, a persistent gap remains between theoretical certified robustness and empirical robustness accuracy. This paper introduces a new framework that bridges this gap by leveraging Lipschitz continuity for certification and proposing a novel, less conservative method for computing confidence intervals in randomized smoothing. Our approach tightens the bounds of certified robustness, offering a more accurate reflection of model robustness in practice. Through rigorous experimentation we show that our method improves the robust accuracy, compressing the gap between empirical findings and previous theoretical results. We argue that investigating local Lipschitz constants and designing ad-hoc confidence intervals can further enhance the performance of randomized smoothing. These results pave the way for a deeper understanding of the relationship between Lipschitz continuity and certified robustness.
Fast Training of Recurrent Neural Networks with Stationary State Feedbacks
Mar 29, 2025



Recurrent neural networks (RNNs) have recently demonstrated strong performance and faster inference than Transformers at comparable parameter budgets. However, the recursive gradient computation with the backpropagation through time (or BPTT) algorithm remains the major computational bottleneck. In this work, we propose a novel method that replaces BPTT with a fixed gradient feedback mechanism, yielding an efficient approximation of the exact gradient propagation based on the assumption of time stationarity. Our approach leverages state-space model (SSM) principles to define a structured feedback matrix that directly propagates gradients from future time steps. This formulation bypasses the need for recursive gradient backpropagation, significantly reducing training overhead while preserving the network's ability to capture long-term dependencies. The experiments on language modeling benchmarks exhibit competitive perplexity scores, while significantly reducing the training costs. These promising results suggest that designing a feedback method like an SSM can fully exploit the efficiency advantages of RNNs for many practical applications.
SCOPE: A Self-supervised Framework for Improving Faithfulness in Conditional Text Generation
Feb 19, 2025Large Language Models (LLMs), when used for conditional text generation, often produce hallucinations, i.e., information that is unfaithful or not grounded in the input context. This issue arises in typical conditional text generation tasks, such as text summarization and data-to-text generation, where the goal is to produce fluent text based on contextual input. When fine-tuned on specific domains, LLMs struggle to provide faithful answers to a given context, often adding information or generating errors. One underlying cause of this issue is that LLMs rely on statistical patterns learned from their training data. This reliance can interfere with the model's ability to stay faithful to a provided context, leading to the generation of ungrounded information. We build upon this observation and introduce a novel self-supervised method for generating a training set of unfaithful samples. We then refine the model using a training process that encourages the generation of grounded outputs over unfaithful ones, drawing on preference-based training. Our approach leads to significantly more grounded text generation, outperforming existing self-supervised techniques in faithfulness, as evaluated through automatic metrics, LLM-based assessments, and human evaluations.
Conditional Distribution Quantization in Machine Learning
Feb 11, 2025



Conditional expectation \mathbb{E}(Y \mid X) often fails to capture the complexity of multimodal conditional distributions \mathcal{L}(Y \mid X). To address this, we propose using n-point conditional quantizations--functional mappings of X that are learnable via gradient descent--to approximate \mathcal{L}(Y \mid X). This approach adapts Competitive Learning Vector Quantization (CLVQ), tailored for conditional distributions. It goes beyond single-valued predictions by providing multiple representative points that better reflect multimodal structures. It enables the approximation of the true conditional law in the Wasserstein distance. The resulting framework is theoretically grounded and useful for uncertainty quantification and multimodal data generation tasks. For example, in computer vision inpainting tasks, multiple plausible reconstructions may exist for the same partially observed input image X. We demonstrate the effectiveness of our approach through experiments on synthetic and real-world datasets.