 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the MIA Vulnerability Gap Between Private GANs and Diffusion Models
Sep 03, 2025Generative Adversarial Networks (GANs) and diffusion models have emerged as leading approaches for high-quality image synthesis. While both can be trained under differential privacy (DP) to protect sensitive data, their sensitivity to membership inference attacks (MIAs), a key threat to data confidentiality, remains poorly understood. In this work, we present the first unified theoretical and empirical analysis of the privacy risks faced by differentially private generative models. We begin by showing, through a stability-based analysis, that GANs exhibit fundamentally lower sensitivity to data perturbations than diffusion models, suggesting a structural advantage in resisting MIAs. We then validate this insight with a comprehensive empirical study using a standardized MIA pipeline to evaluate privacy leakage across datasets and privacy budgets. Our results consistently reveal a marked privacy robustness gap in favor of GANs, even in strong DP regimes, highlighting that model type alone can critically shape privacy leakage.
Scaled Inverse Graphics: Efficiently Learning Large Sets of 3D Scenes
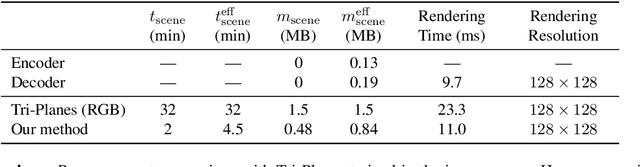
Oct 31, 2024While the field of inverse graphics has been witnessing continuous growth, techniques devised thus far predominantly focus on learning individual scene representations. In contrast, learning large sets of scenes has been a considerable bottleneck in NeRF developments, as repeatedly applying inverse graphics on a sequence of scenes, though essential for various applications, remains largely prohibitive in terms of resource costs. We introduce a framework termed "scaled inverse graphics", aimed at efficiently learning large sets of scene representations, and propose a novel method to this end. It operates in two stages: (i) training a compression model on a subset of scenes, then (ii) training NeRF models on the resulting smaller representations, thereby reducing the optimization space per new scene. In practice, we compact the representation of scenes by learning NeRFs in a latent space to reduce the image resolution, and sharing information across scenes to reduce NeRF representation complexity. We experimentally show that our method presents both the lowest training time and memory footprint in scaled inverse graphics compared to other methods applied independently on each scene. Our codebase is publicly available as open-source. Our project page can be found at https://scaled-ig.github.io .
Bringing NeRFs to the Latent Space: Inverse Graphics Autoencoder
Oct 30, 2024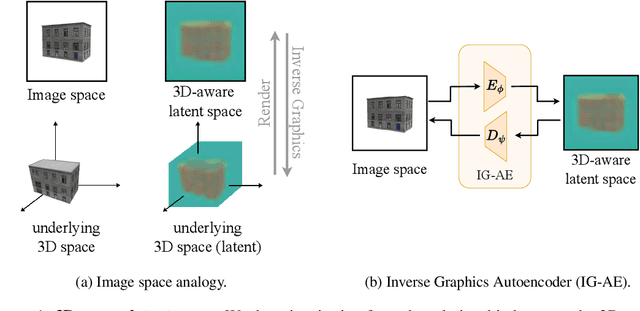
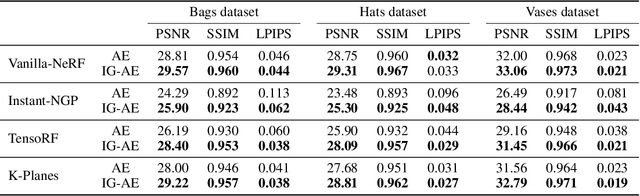


While pre-trained image autoencoders are increasingly utilized in computer vision, the application of inverse graphics in 2D latent spaces has been under-explored. Yet, besides reducing the training and rendering complexity, applying inverse graphics in the latent space enables a valuable interoperability with other latent-based 2D methods. The major challenge is that inverse graphics cannot be directly applied to such image latent spaces because they lack an underlying 3D geometry. In this paper, we propose an Inverse Graphics Autoencoder (IG-AE) that specifically addresses this issue. To this end, we regularize an image autoencoder with 3D-geometry by aligning its latent space with jointly trained latent 3D scenes. We utilize the trained IG-AE to bring NeRFs to the latent space with a latent NeRF training pipeline, which we implement in an open-source extension of the Nerfstudio framework, thereby unlocking latent scene learning for its supported methods. We experimentally confirm that Latent NeRFs trained with IG-AE present an improved quality compared to a standard autoencoder, all while exhibiting training and rendering accelerations with respect to NeRFs trained in the image space. Our project page can be found at https://ig-ae.github.io .
Improving Consistency Models with Generator-Induced Coupling
Jun 13, 2024



Consistency models are promising generative models as they distill the multi-step sampling of score-based diffusion in a single forward pass of a neural network. Without access to sampling trajectories of a pre-trained diffusion model, consistency training relies on proxy trajectories built on an independent coupling between the noise and data distributions. Refining this coupling is a key area of improvement to make it more adapted to the task and reduce the resulting randomness in the training process. In this work, we introduce a novel coupling associating the input noisy data with their generated output from the consistency model itself, as a proxy to the inaccessible diffusion flow output. Our affordable approach exploits the inherent capacity of consistency models to compute the transport map in a single step. We provide intuition and empirical evidence of the relevance of our generator-induced coupling (GC), which brings consistency training closer to score distillation. Consequently, our method not only accelerates consistency training convergence by significant amounts but also enhances the resulting performance. The code is available at: https://github.com/thibautissenhuth/consistency_GC.
Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes
Mar 18, 2024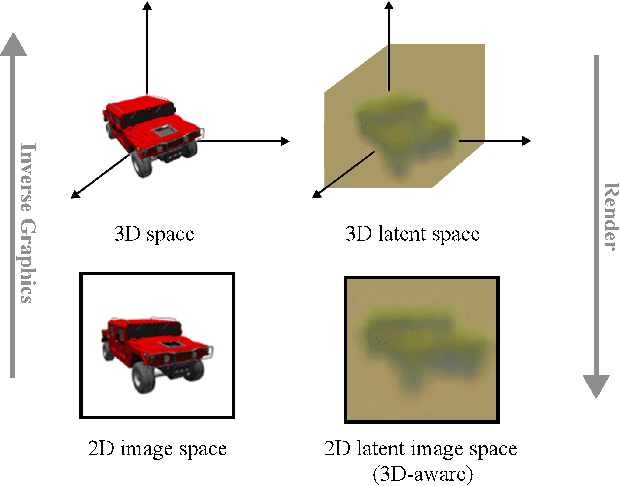
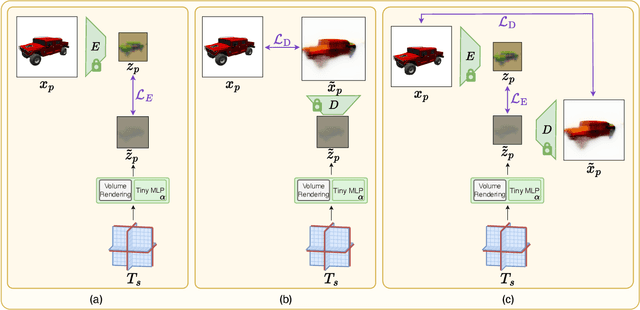

We present a method enabling the scaling of NeRFs to learn a large number of semantically-similar scenes. We combine two techniques to improve the required training time and memory cost per scene. First, we learn a 3D-aware latent space in which we train Tri-Plane scene representations, hence reducing the resolution at which scenes are learned. Moreover, we present a way to share common information across scenes, hence allowing for a reduction of model complexity to learn a particular scene. Our method reduces effective per-scene memory costs by 44% and per-scene time costs by 86% when training 1000 scenes. Our project page can be found at https://3da-ae.github.io .
Differentially Private Gradient Flow based on the Sliced Wasserstein Distance for Non-Parametric Generative Modeling
Dec 13, 2023
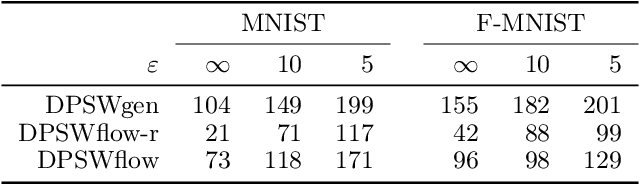

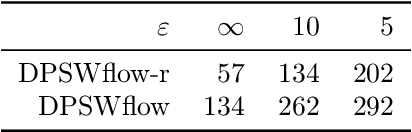
Safeguarding privacy in sensitive training data is paramount, particularly in the context of generative modeling. This is done through either differentially private stochastic gradient descent, or with a differentially private metric for training models or generators. In this paper, we introduce a novel differentially private generative modeling approach based on parameter-free gradient flows in the space of probability measures. The proposed algorithm is a new discretized flow which operates through a particle scheme, utilizing drift derived from the sliced Wasserstein distance and computed in a private manner. Our experiments show that compared to a generator-based model, our proposed model can generate higher-fidelity data at a low privacy budget, offering a viable alternative to generator-based approaches.
EvE: Exploiting Generative Priors for Radiance Field Enrichment
Dec 01, 2023



Modeling large-scale scenes from unconstrained image collections in-the-wild has proven to be a major challenge in computer vision. Existing methods tackling in-the-wild neural rendering operate in a closed-world setting, where knowledge is limited to a scene's captured images within a training set. We propose EvE, which is, to the best of our knowledge, the first method leveraging generative priors to improve in-the-wild scene modeling. We employ pre-trained generative networks to enrich K-Planes representations with extrinsic knowledge. To this end, we define an alternating training procedure to conduct optimization guidance of K-Planes trained on the training set. We carry out extensive experiments and verify the merit of our method on synthetic data as well as real tourism photo collections. EvE enhances rendered scenes with richer details and outperforms the state of the art on the task of novel view synthesis in-the-wild. Our project page can be found at https://eve-nvs.github.io .
Unifying GANs and Score-Based Diffusion as Generative Particle Models
May 25, 2023Particle-based deep generative models, such as gradient flows and score-based diffusion models, have recently gained traction thanks to their striking performance. Their principle of displacing particle distributions by differential equations is conventionally seen as opposed to the previously widespread generative adversarial networks (GANs), which involve training a pushforward generator network. In this paper, we challenge this interpretation and propose a novel framework that unifies particle and adversarial generative models by framing generator training as a generalization of particle models. This suggests that a generator is an optional addition to any such generative model. Consequently, integrating a generator into a score-based diffusion model and training a GAN without a generator naturally emerge from our framework. We empirically test the viability of these original models as proofs of concepts of potential applications of our framework.
Continuous PDE Dynamics Forecasting with Implicit Neural Representations
Sep 29, 2022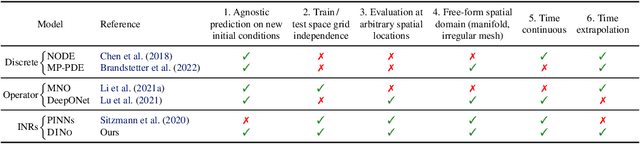
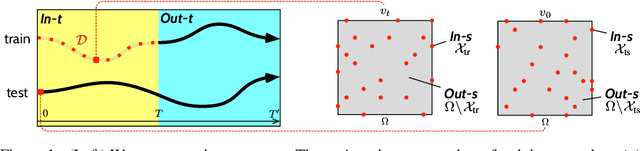
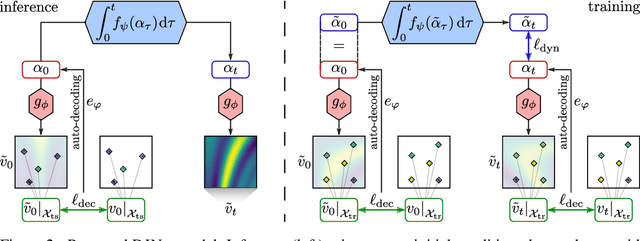
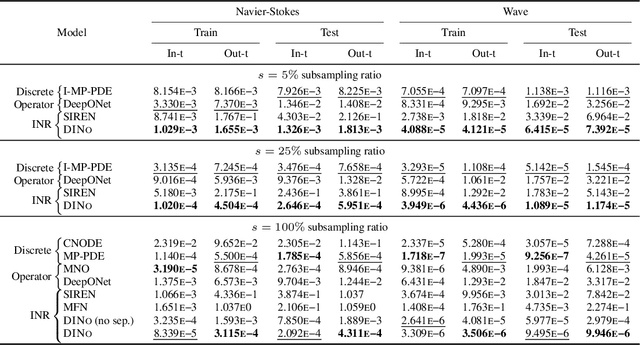
Effective data-driven PDE forecasting methods often rely on fixed spatial and / or temporal discretizations. This raises limitations in real-world applications like weather prediction where flexible extrapolation at arbitrary spatiotemporal locations is required. We address this problem by introducing a new data-driven approach, DINo, that models a PDE's flow with continuous-time dynamics of spatially continuous functions. This is achieved by embedding spatial observations independently of their discretization via Implicit Neural Representations in a small latent space temporally driven by a learned ODE. This separate and flexible treatment of time and space makes DINo the first data-driven model to combine the following advantages. It extrapolates at arbitrary spatial and temporal locations; it can learn from sparse irregular grids or manifolds; at test time, it generalizes to new grids or resolutions. DINo outperforms alternative neural PDE forecasters in a variety of challenging generalization scenarios on representative PDE systems.
A Neural Tangent Kernel Perspective of GANs
Jun 10, 2021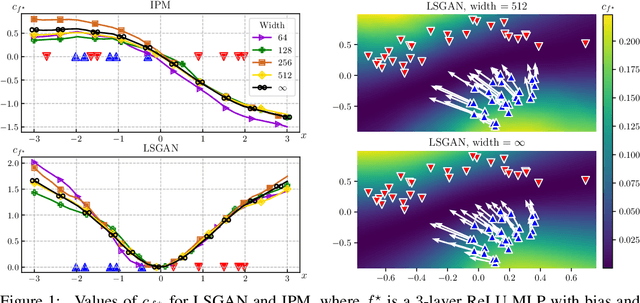

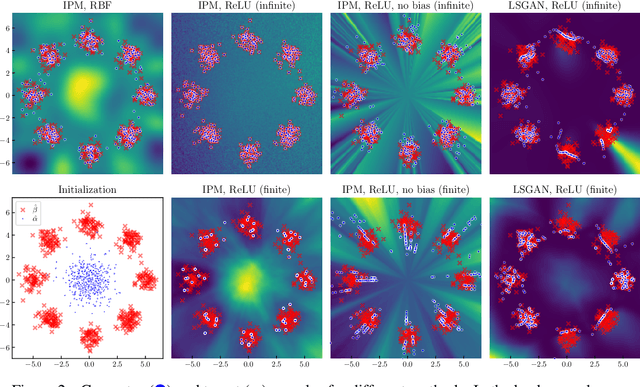

Theoretical analyses for Generative Adversarial Networks (GANs) generally assume an arbitrarily large family of discriminators and do not consider the characteristics of the architectures used in practice. We show that this framework of analysis is too simplistic to properly analyze GAN training. To tackle this issue, we leverage the theory of infinite-width neural networks to model neural discriminator training for a wide range of adversarial losses via its Neural Tangent Kernel (NTK). Our analytical results show that GAN trainability primarily depends on the discriminator's architecture. We further study the discriminator for specific architectures and losses, and highlight properties providing a new understanding of GAN training. For example, we find that GANs trained with the integral probability metric loss minimize the maximum mean discrepancy with the NTK as kernel. Our conclusions demonstrate the analysis opportunities provided by the proposed framework, which paves the way for better and more principled GAN models. We release a generic GAN analysis toolkit based on our framework that supports the empirical part of our study.