 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Consistency Models with Generator-Induced Coupling
Jun 13, 2024



Consistency models are promising generative models as they distill the multi-step sampling of score-based diffusion in a single forward pass of a neural network. Without access to sampling trajectories of a pre-trained diffusion model, consistency training relies on proxy trajectories built on an independent coupling between the noise and data distributions. Refining this coupling is a key area of improvement to make it more adapted to the task and reduce the resulting randomness in the training process. In this work, we introduce a novel coupling associating the input noisy data with their generated output from the consistency model itself, as a proxy to the inaccessible diffusion flow output. Our affordable approach exploits the inherent capacity of consistency models to compute the transport map in a single step. We provide intuition and empirical evidence of the relevance of our generator-induced coupling (GC), which brings consistency training closer to score distillation. Consequently, our method not only accelerates consistency training convergence by significant amounts but also enhances the resulting performance. The code is available at: https://github.com/thibautissenhuth/consistency_GC.
Improving a Proportional Integral Controller with Reinforcement Learning on a Throttle Valve Benchmark
Feb 21, 2024
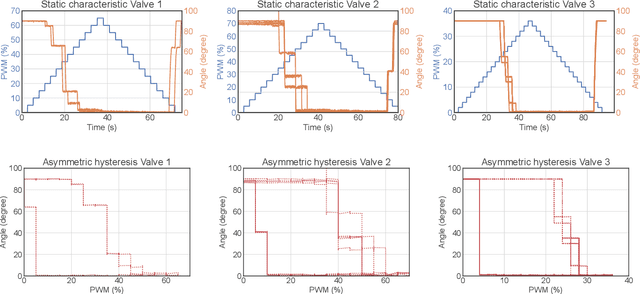
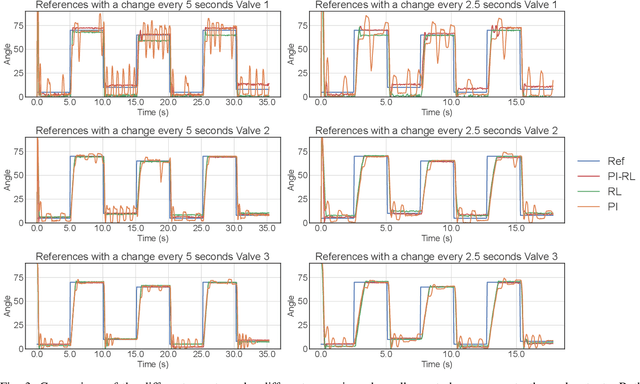
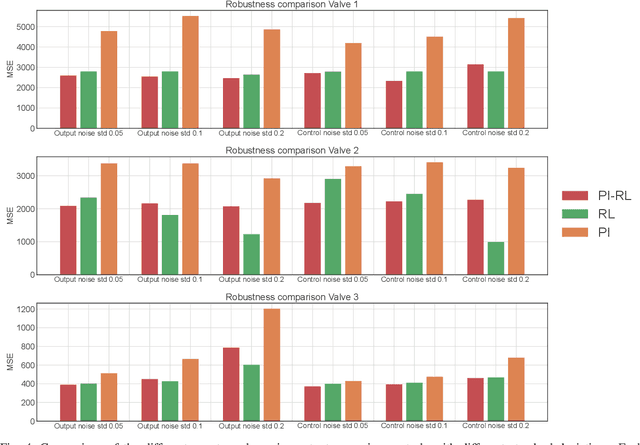
This paper presents a learning-based control strategy for non-linear throttle valves with an asymmetric hysteresis, leading to a near-optimal controller without requiring any prior knowledge about the environment. We start with a carefully tuned Proportional Integrator (PI) controller and exploit the recent advances in Reinforcement Learning (RL) with Guides to improve the closed-loop behavior by learning from the additional interactions with the valve. We test the proposed control method in various scenarios on three different valves, all highlighting the benefits of combining both PI and RL frameworks to improve control performance in non-linear stochastic systems. In all the experimental test cases, the resulting agent has a better sample efficiency than traditional RL agents and outperforms the PI controller.
Enhancing Reinforcement Learning Agents with Local Guides
Feb 21, 2024



This paper addresses the problem of integrating local guide policies into a Reinforcement Learning agent. For this, we show how to adapt existing algorithms to this setting before introducing a novel algorithm based on a noisy policy-switching procedure. This approach builds on a proper Approximate Policy Evaluation (APE) scheme to provide a perturbation that carefully leads the local guides towards better actions. We evaluated our method on a set of classical Reinforcement Learning problems, including safety-critical systems where the agent cannot enter some areas at the risk of triggering catastrophic consequences. In all the proposed environments, our agent proved to be efficient at leveraging those policies to improve the performance of any APE-based Reinforcement Learning algorithm, especially in its first learning stages.
A Trust Region Approach for Few-Shot Sim-to-Real Reinforcement Learning
Dec 24, 2023



Simulation-to-Reality Reinforcement Learning (Sim-to-Real RL) seeks to use simulations to minimize the need for extensive real-world interactions. Specifically, in the few-shot off-dynamics setting, the goal is to acquire a simulator-based policy despite a dynamics mismatch that can be effectively transferred to the real-world using only a handful of real-world transitions. In this context, conventional RL agents tend to exploit simulation inaccuracies resulting in policies that excel in the simulator but underperform in the real environment. To address this challenge, we introduce a novel approach that incorporates a penalty to constrain the trajectories induced by the simulator-trained policy inspired by recent advances in Imitation Learning and Trust Region based RL algorithms. We evaluate our method across various environments representing diverse Sim-to-Real conditions, where access to the real environment is extremely limited. These experiments include high-dimensional systems relevant to real-world applications. Across most tested scenarios, our proposed method demonstrates performance improvements compared to existing baselines.
AdBooster: Personalized Ad Creative Generation using Stable Diffusion Outpainting
Sep 08, 2023

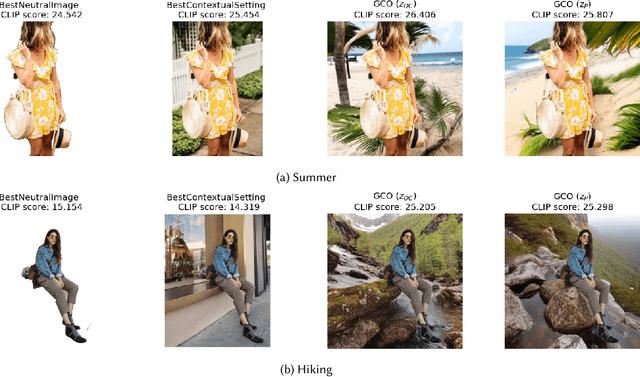
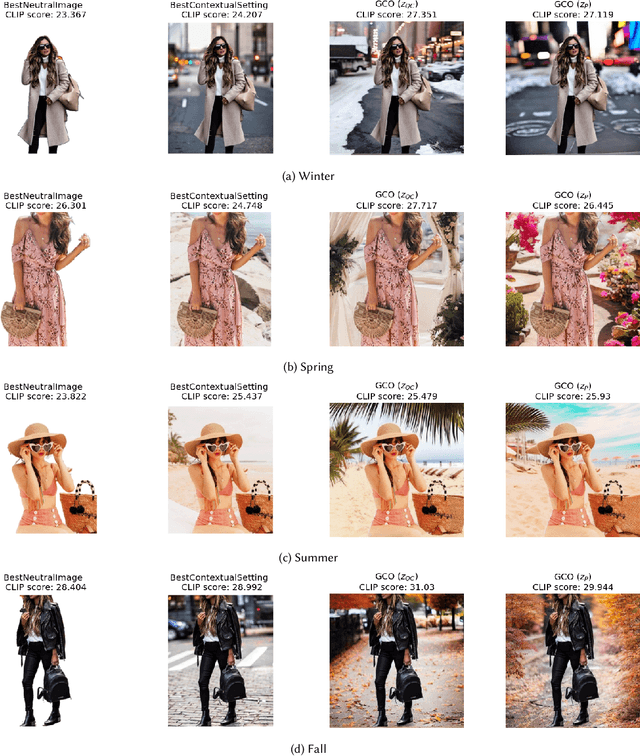
In digital advertising, the selection of the optimal item (recommendation) and its best creative presentation (creative optimization) have traditionally been considered separate disciplines. However, both contribute significantly to user satisfaction, underpinning our assumption that it relies on both an item's relevance and its presentation, particularly in the case of visual creatives. In response, we introduce the task of {\itshape Generative Creative Optimization (GCO)}, which proposes the use of generative models for creative generation that incorporate user interests, and {\itshape AdBooster}, a model for personalized ad creatives based on the Stable Diffusion outpainting architecture. This model uniquely incorporates user interests both during fine-tuning and at generation time. To further improve AdBooster's performance, we also introduce an automated data augmentation pipeline. Through our experiments on simulated data, we validate AdBooster's effectiveness in generating more relevant creatives than default product images, showing its potential of enhancing user engagement.
Unifying GANs and Score-Based Diffusion as Generative Particle Models
May 25, 2023Particle-based deep generative models, such as gradient flows and score-based diffusion models, have recently gained traction thanks to their striking performance. Their principle of displacing particle distributions by differential equations is conventionally seen as opposed to the previously widespread generative adversarial networks (GANs), which involve training a pushforward generator network. In this paper, we challenge this interpretation and propose a novel framework that unifies particle and adversarial generative models by framing generator training as a generalization of particle models. This suggests that a generator is an optional addition to any such generative model. Consequently, integrating a generator into a score-based diffusion model and training a GAN without a generator naturally emerge from our framework. We empirically test the viability of these original models as proofs of concepts of potential applications of our framework.
Coloring graph neural networks for node disambiguation
Dec 12, 2019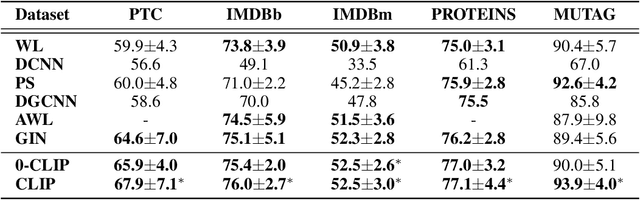
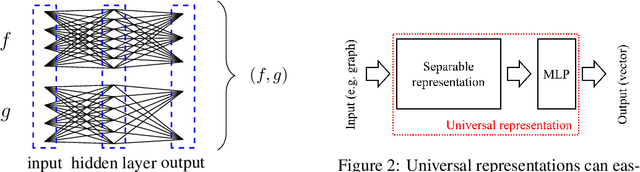
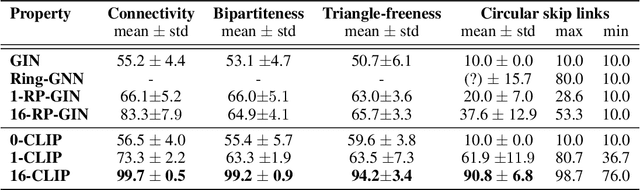
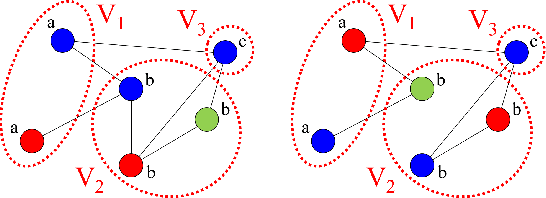
In this paper, we show that a simple coloring scheme can improve, both theoretically and empirically, the expressive power of Message Passing Neural Networks(MPNNs). More specifically, we introduce a graph neural network called Colored Local Iterative Procedure (CLIP) that uses colors to disambiguate identical node attributes, and show that this representation is a universal approximator of continuous functions on graphs with node attributes. Our method relies on separability , a key topological characteristic that allows to extend well-chosen neural networks into universal representations. Finally, we show experimentally that CLIP is capable of capturing structural characteristics that traditional MPNNs fail to distinguish,while being state-of-the-art on benchmark graph classification datasets.
Theoretical Limits of Pipeline Parallel Optimization and Application to Distributed Deep Learning
Oct 11, 2019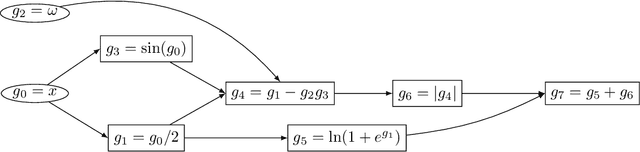
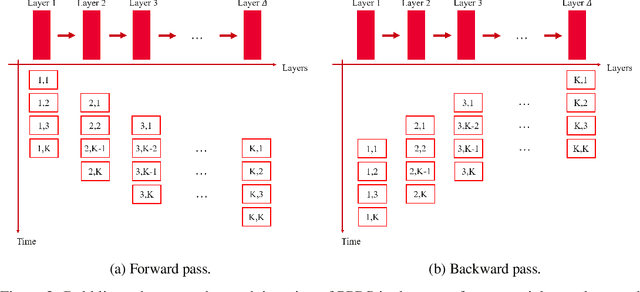
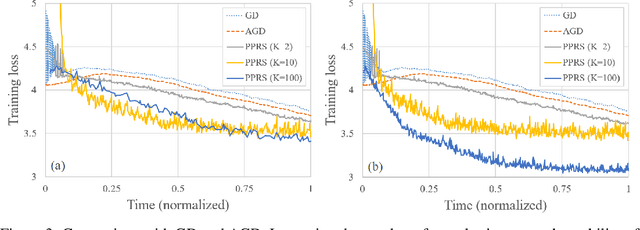
We investigate the theoretical limits of pipeline parallel learning of deep learning architectures, a distributed setup in which the computation is distributed per layer instead of per example. For smooth convex and non-convex objective functions, we provide matching lower and upper complexity bounds and show that a naive pipeline parallelization of Nesterov's accelerated gradient descent is optimal. For non-smooth convex functions, we provide a novel algorithm coined Pipeline Parallel Random Smoothing (PPRS) that is within a $d^{1/4}$ multiplicative factor of the optimal convergence rate, where $d$ is the underlying dimension. While the convergence rate still obeys a slow $\varepsilon^{-2}$ convergence rate, the depth-dependent part is accelerated, resulting in a near-linear speed-up and convergence time that only slightly depends on the depth of the deep learning architecture. Finally, we perform an empirical analysis of the non-smooth non-convex case and show that, for difficult and highly non-smooth problems, PPRS outperforms more traditional optimization algorithms such as gradient descent and Nesterov's accelerated gradient descent for problems where the sample size is limited, such as few-shot or adversarial learning.