 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization Exploiting Spatial Variations in the Magnetic Field: Principles and Challenges
Feb 15, 2026Signal processing has played, and continues to play, a fundamental role in the evolution of modern localization technologies. Localization using spatial variations in the Earth's magnetic field is no exception. It relies on signal-processing methods for statistical state inference, magnetic-field modeling, and sensor calibration. Contemporary localization techniques based on spatial variations in the magnetic field can provide decimeter-level indoor localization accuracy and outdoor localization accuracy on par with strategic-grade inertial navigation systems. This article provides a broad, high-level overview of current signal-processing principles and open research challenges in localization using spatial variations in the Earth's magnetic field. The aim is to provide the reader with an understanding of the similarities and differences among existing key technologies from a statistical signal-processing perspective. To that end, existing key technologies will be presented within a common parametric signal-model framework compatible with well-established statistical inference methods.
A Unified Representation of Neural Networks Architectures
Dec 22, 2025In this paper we consider the limiting case of neural networks (NNs) architectures when the number of neurons in each hidden layer and the number of hidden layers tend to infinity thus forming a continuum, and we derive approximation errors as a function of the number of neurons and/or hidden layers. Firstly, we consider the case of neural networks with a single hidden layer and we derive an integral infinite width neural representation that generalizes existing continuous neural networks (CNNs) representations. Then we extend this to deep residual CNNs that have a finite number of integral hidden layers and residual connections. Secondly, we revisit the relation between neural ODEs and deep residual NNs and we formalize approximation errors via discretization techniques. Then, we merge these two approaches into a unified homogeneous representation of NNs as a Distributed Parameter neural Network (DiPaNet) and we show that most of the existing finite and infinite-dimensional NNs architectures are related via homogenization/discretization with the DiPaNet representation. Our approach is purely deterministic and applies to general, uniformly continuous matrix weight functions. Relations with neural fields and other neural integro-differential equations are discussed along with further possible generalizations and applications of the DiPaNet framework.
Revisiting Split Covariance Intersection: Correlated Components and Optimality
Jan 14, 2025Linear fusion is a cornerstone of estimation theory. Implementing optimal linear fusion requires knowledge of the covariance of the vector of errors associated with all the estimators. In distributed or cooperative systems, the cross-covariance terms cannot be computed, and to avoid underestimating the estimation error, conservative fusions must be performed. A conservative fusion provides a fused estimator with a covariance bound that is guaranteed to be larger than the true, but computationally intractable, covariance of the error. Previous research by Reinhardt \textit{et al.} proved that, if no additional assumption is made about the errors of the estimators, the minimal bound for fusing two estimators is given by a fusion called Covariance Intersection (CI). In distributed systems, the estimation errors contain independent and correlated terms induced by the measurement noises and the process noise. In this case, CI is no longer the optimal method. Split Covariance Intersection (SCI) has been developed to take advantage of the uncorrelated components. This paper extends SCI to also take advantage of the correlated components. Then, it is proved that the new fusion provides the optimal conservative fusion bounds for two estimators, generalizing the optimality of CI to a wider class of fusion schemes. The benefits of this extension are demonstrated in simulations.
Split Covariance Intersection with Correlated Components for Distributed Estimation
Mar 06, 2024This paper introduces a new conservative fusion method to exploit the correlated components within the estimation errors. Fusion is the process of combining multiple estimates of a given state to produce a new estimate with a smaller MSE. To perform the optimal linear fusion, the (centralized) covariance associated with the errors of all estimates is required. If it is partially unknown, the optimal fusion cannot be computed. Instead, a solution is to perform a conservative fusion. A conservative fusion provides a gain and a bound on the resulting MSE matrix which guarantees that the error is not underestimated. A well-known conservative fusion is the Covariance Intersection fusion. It has been modified to exploit the uncorrelated components within the errors. In this paper, it is further extended to exploit the correlated components as well. The resulting fusion is integrated into standard distributed algorithms where it allows exploiting the process noise observed by all agents. The improvement is confirmed by simulations.
Enhancing Reinforcement Learning Agents with Local Guides
Feb 21, 2024



This paper addresses the problem of integrating local guide policies into a Reinforcement Learning agent. For this, we show how to adapt existing algorithms to this setting before introducing a novel algorithm based on a noisy policy-switching procedure. This approach builds on a proper Approximate Policy Evaluation (APE) scheme to provide a perturbation that carefully leads the local guides towards better actions. We evaluated our method on a set of classical Reinforcement Learning problems, including safety-critical systems where the agent cannot enter some areas at the risk of triggering catastrophic consequences. In all the proposed environments, our agent proved to be efficient at leveraging those policies to improve the performance of any APE-based Reinforcement Learning algorithm, especially in its first learning stages.
Improving a Proportional Integral Controller with Reinforcement Learning on a Throttle Valve Benchmark
Feb 21, 2024
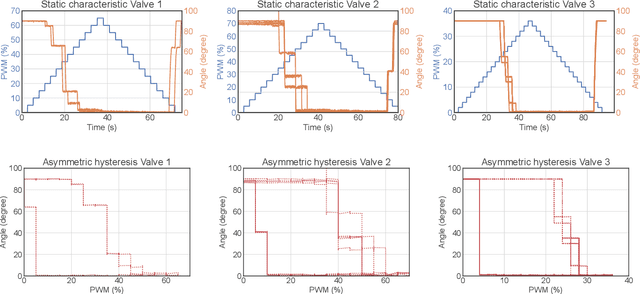
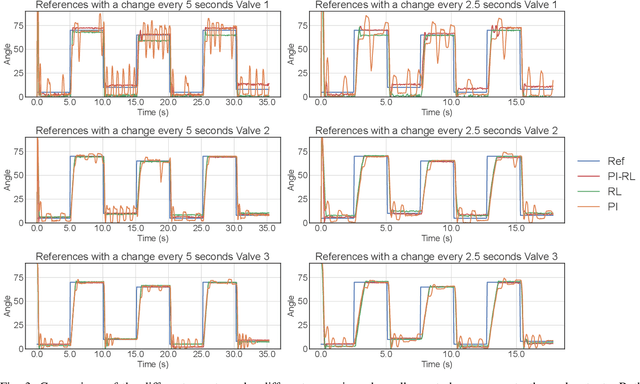
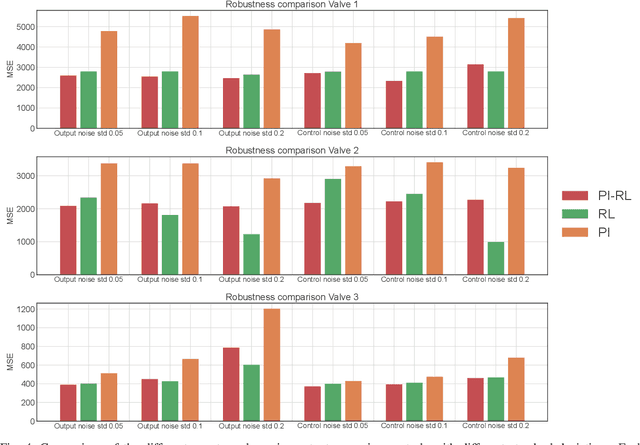
This paper presents a learning-based control strategy for non-linear throttle valves with an asymmetric hysteresis, leading to a near-optimal controller without requiring any prior knowledge about the environment. We start with a carefully tuned Proportional Integrator (PI) controller and exploit the recent advances in Reinforcement Learning (RL) with Guides to improve the closed-loop behavior by learning from the additional interactions with the valve. We test the proposed control method in various scenarios on three different valves, all highlighting the benefits of combining both PI and RL frameworks to improve control performance in non-linear stochastic systems. In all the experimental test cases, the resulting agent has a better sample efficiency than traditional RL agents and outperforms the PI controller.
Pseudorange Rigidity and Solvability of Cooperative GNSS Positioning
Jan 10, 2024Global Navigation Satellite Systems (GNSS) are a widely used technology for positioning and navigation. GNSS positioning relies on pseudorange measurements from satellites to receivers. A pseudorange is the apparent distance between two agents deduced from the time-of-flight of a signal sent from one agent to the other. Because of the lack of synchronization between the agents' clocks, it is a biased version of their distance. This paper introduces a new rigidity theory adapted to pseudorange measurements. The peculiarity of pseudoranges is that they are asymmetrical measurements. Therefore, unlike other usual rigidities, the graphs of pseudorange frameworks are directed. In this paper, pseudorange rigidity is proved to be a generic property of the underlying undirected graph of constraints. The main result is a characterization of rigid pseudorange graphs as combinations of rigid distance graphs and connected graphs. This new theory is adapted for GNSS. It provides new insights into the minimum number of satellites needed to locate a receiver, and is applied to the localization of GNSS cooperative networks of receivers. The interests of asymmetrical constraints in the context of formation control are also discussed.
A Trust Region Approach for Few-Shot Sim-to-Real Reinforcement Learning
Dec 24, 2023



Simulation-to-Reality Reinforcement Learning (Sim-to-Real RL) seeks to use simulations to minimize the need for extensive real-world interactions. Specifically, in the few-shot off-dynamics setting, the goal is to acquire a simulator-based policy despite a dynamics mismatch that can be effectively transferred to the real-world using only a handful of real-world transitions. In this context, conventional RL agents tend to exploit simulation inaccuracies resulting in policies that excel in the simulator but underperform in the real environment. To address this challenge, we introduce a novel approach that incorporates a penalty to constrain the trajectories induced by the simulator-trained policy inspired by recent advances in Imitation Learning and Trust Region based RL algorithms. We evaluate our method across various environments representing diverse Sim-to-Real conditions, where access to the real environment is extremely limited. These experiments include high-dimensional systems relevant to real-world applications. Across most tested scenarios, our proposed method demonstrates performance improvements compared to existing baselines.
MAINS: A Magnetic Field Aided Inertial Navigation System for Indoor Positioning
Dec 05, 2023



A Magnetic field Aided Inertial Navigation System (MAINS) for indoor navigation is proposed in this paper. MAINS leverages an array of magnetometers to measure spatial variations in the magnetic field, which are then used to estimate the displacement and orientation changes of the system, thereby aiding the inertial navigation system (INS). Experiments show that MAINS significantly outperforms the stand-alone INS, demonstrating a remarkable two orders of magnitude reduction in position error. Furthermore, when compared to the state-of-the-art magnetic-field-aided navigation approach, the proposed method exhibits slightly improved horizontal position accuracy. On the other hand, it has noticeably larger vertical error on datasets with large magnetic field variations. However, one of the main advantages of MAINS compared to the state-of-the-art is that it enables flexible sensor configurations. The experimental results show that the position error after 2 minutes of navigation in most cases is less than 3 meters when using an array of 30 magnetometers. Thus, the proposed navigation solution has the potential to solve one of the key challenges faced with current magnetic-field simultaneous localization and mapping (SLAM) solutions: the very limited allowable length of the exploration phase during which unvisited areas are mapped.
Fusion of Distance Measurements between Agents with Unknown Correlations
Jun 09, 2023
Cooperative localization is a promising solution to improve the accuracy and overcome the shortcomings of GNSS. Cooperation is often achieved by measuring the distance between users. To optimally integrate a distance measurement between two users into a navigation filter, the correlation between the errors of their estimates must be known. Unfortunately, in large scale networks the agents cannot compute these correlations and must use consistent filters. A consistent filter provides an upper bound on the covariance of the error of the estimator taking into account all the possible correlations. In this paper, a consistent linear filter for integrating a distance measurement is derived using Split Covariance Intersection. Its analysis shows that a distance measurement between two agents can only benefit one of them, i.e., only one of the two can use the distance measurement to improve its estimator. Furthermore, in some cases, none can. A necessary condition for an agent to benefit from the measurement is given for a general class of objective functions. When the objective function is the trace or the determinant, necessary and sufficient conditions are given.