 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Policy Gradient
Jan 31, 2025Motivated by the increasing deployment of reinforcement learning in the real world, involving a large consumption of personal data, we introduce a differentially private (DP) policy gradient algorithm. We show that, in this setting, the introduction of Differential Privacy can be reduced to the computation of appropriate trust regions, thus avoiding the sacrifice of theoretical properties of the DP-less methods. Therefore, we show that it is possible to find the right trade-off between privacy noise and trust-region size to obtain a performant differentially private policy gradient algorithm. We then outline its performance empirically on various benchmarks. Our results and the complexity of the tasks addressed represent a significant improvement over existing DP algorithms in online RL.
Enhancing Reinforcement Learning Agents with Local Guides
Feb 21, 2024This paper addresses the problem of integrating local guide policies into a Reinforcement Learning agent. For this, we show how to adapt existing algorithms to this setting before introducing a novel algorithm based on a noisy policy-switching procedure. This approach builds on a proper Approximate Policy Evaluation (APE) scheme to provide a perturbation that carefully leads the local guides towards better actions. We evaluated our method on a set of classical Reinforcement Learning problems, including safety-critical systems where the agent cannot enter some areas at the risk of triggering catastrophic consequences. In all the proposed environments, our agent proved to be efficient at leveraging those policies to improve the performance of any APE-based Reinforcement Learning algorithm, especially in its first learning stages.
Improving a Proportional Integral Controller with Reinforcement Learning on a Throttle Valve Benchmark
Feb 21, 2024
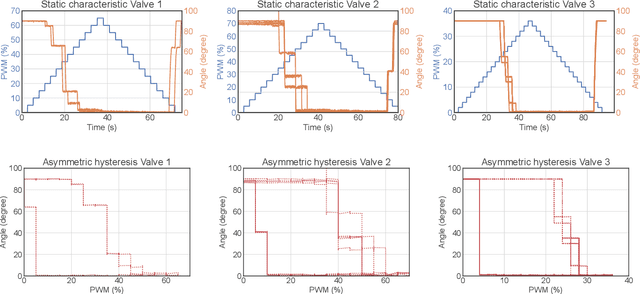
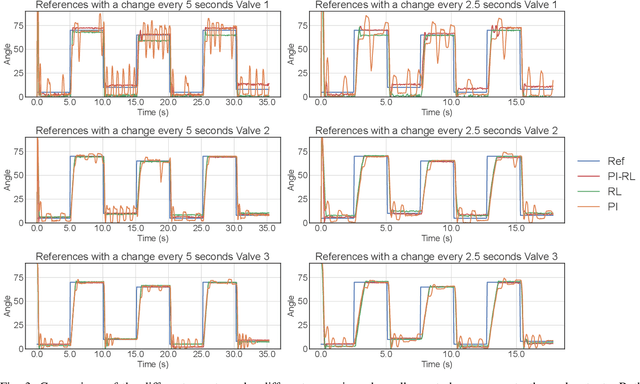
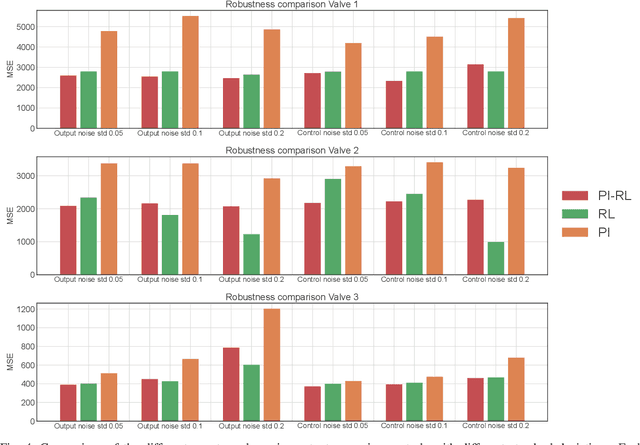
This paper presents a learning-based control strategy for non-linear throttle valves with an asymmetric hysteresis, leading to a near-optimal controller without requiring any prior knowledge about the environment. We start with a carefully tuned Proportional Integrator (PI) controller and exploit the recent advances in Reinforcement Learning (RL) with Guides to improve the closed-loop behavior by learning from the additional interactions with the valve. We test the proposed control method in various scenarios on three different valves, all highlighting the benefits of combining both PI and RL frameworks to improve control performance in non-linear stochastic systems. In all the experimental test cases, the resulting agent has a better sample efficiency than traditional RL agents and outperforms the PI controller.
Differentially Private Model-Based Offline Reinforcement Learning
Feb 08, 2024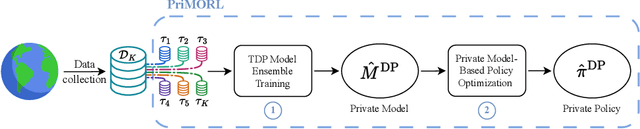



We address offline reinforcement learning with privacy guarantees, where the goal is to train a policy that is differentially private with respect to individual trajectories in the dataset. To achieve this, we introduce DP-MORL, an MBRL algorithm coming with differential privacy guarantees. A private model of the environment is first learned from offline data using DP-FedAvg, a training method for neural networks that provides differential privacy guarantees at the trajectory level. Then, we use model-based policy optimization to derive a policy from the (penalized) private model, without any further interaction with the system or access to the input data. We empirically show that DP-MORL enables the training of private RL agents from offline data and we furthermore outline the price of privacy in this setting.
A Trust Region Approach for Few-Shot Sim-to-Real Reinforcement Learning
Dec 24, 2023



Simulation-to-Reality Reinforcement Learning (Sim-to-Real RL) seeks to use simulations to minimize the need for extensive real-world interactions. Specifically, in the few-shot off-dynamics setting, the goal is to acquire a simulator-based policy despite a dynamics mismatch that can be effectively transferred to the real-world using only a handful of real-world transitions. In this context, conventional RL agents tend to exploit simulation inaccuracies resulting in policies that excel in the simulator but underperform in the real environment. To address this challenge, we introduce a novel approach that incorporates a penalty to constrain the trajectories induced by the simulator-trained policy inspired by recent advances in Imitation Learning and Trust Region based RL algorithms. We evaluate our method across various environments representing diverse Sim-to-Real conditions, where access to the real environment is extremely limited. These experiments include high-dimensional systems relevant to real-world applications. Across most tested scenarios, our proposed method demonstrates performance improvements compared to existing baselines.
Price of Safety in Linear Best Arm Identification
Sep 15, 2023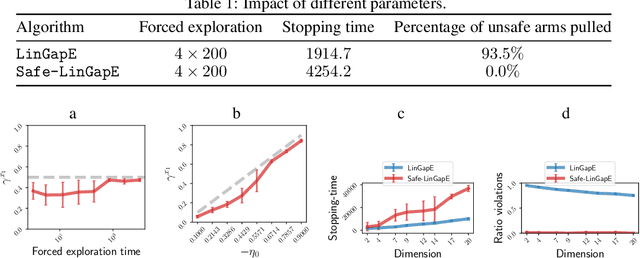
We introduce the safe best-arm identification framework with linear feedback, where the agent is subject to some stage-wise safety constraint that linearly depends on an unknown parameter vector. The agent must take actions in a conservative way so as to ensure that the safety constraint is not violated with high probability at each round. Ways of leveraging the linear structure for ensuring safety has been studied for regret minimization, but not for best-arm identification to the best our knowledge. We propose a gap-based algorithm that achieves meaningful sample complexity while ensuring the stage-wise safety. We show that we pay an extra term in the sample complexity due to the forced exploration phase incurred by the additional safety constraint. Experimental illustrations are provided to justify the design of our algorithm.
Clustered Multi-Agent Linear Bandits
Sep 15, 2023



We address in this paper a particular instance of the multi-agent linear stochastic bandit problem, called clustered multi-agent linear bandits. In this setting, we propose a novel algorithm leveraging an efficient collaboration between the agents in order to accelerate the overall optimization problem. In this contribution, a network controller is responsible for estimating the underlying cluster structure of the network and optimizing the experiences sharing among agents within the same groups. We provide a theoretical analysis for both the regret minimization problem and the clustering quality. Through empirical evaluation against state-of-the-art algorithms on both synthetic and real data, we demonstrate the effectiveness of our approach: our algorithm significantly improves regret minimization while managing to recover the true underlying cluster partitioning.