 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Policy Gradient
Jan 31, 2025Motivated by the increasing deployment of reinforcement learning in the real world, involving a large consumption of personal data, we introduce a differentially private (DP) policy gradient algorithm. We show that, in this setting, the introduction of Differential Privacy can be reduced to the computation of appropriate trust regions, thus avoiding the sacrifice of theoretical properties of the DP-less methods. Therefore, we show that it is possible to find the right trade-off between privacy noise and trust-region size to obtain a performant differentially private policy gradient algorithm. We then outline its performance empirically on various benchmarks. Our results and the complexity of the tasks addressed represent a significant improvement over existing DP algorithms in online RL.
Differentially Private Model-Based Offline Reinforcement Learning
Feb 08, 2024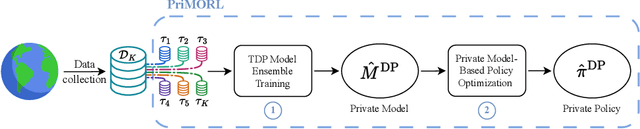



We address offline reinforcement learning with privacy guarantees, where the goal is to train a policy that is differentially private with respect to individual trajectories in the dataset. To achieve this, we introduce DP-MORL, an MBRL algorithm coming with differential privacy guarantees. A private model of the environment is first learned from offline data using DP-FedAvg, a training method for neural networks that provides differential privacy guarantees at the trajectory level. Then, we use model-based policy optimization to derive a policy from the (penalized) private model, without any further interaction with the system or access to the input data. We empirically show that DP-MORL enables the training of private RL agents from offline data and we furthermore outline the price of privacy in this setting.