 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Gossip Algorithms for Machine Learning with Pairwise Objectives
Mar 25, 2026In the IoT era, information is more and more frequently picked up by connected smart sensors with increasing, though limited, storage, communication and computation abilities. Whether due to privacy constraints or to the structure of the distributed system, the development of statistical learning methods dedicated to data that are shared over a network is now a major issue. Gossip-based algorithms have been developed for the purpose of solving a wide variety of statistical learning tasks, ranging from data aggregation over sensor networks to decentralized multi-agent optimization. Whereas the vast majority of contributions consider situations where the function to be estimated or optimized is a basic average of individual observations, it is the goal of this article to investigate the case where the latter is of pairwise nature, taking the form of a U -statistic of degree two. Motivated by various problems such as similarity learning, ranking or clustering for instance, we revisit gossip algorithms specifically designed for pairwise objective functions and provide a comprehensive theoretical framework for their convergence. This analysis fills a gap in the literature by establishing conditions under which these methods succeed, and by identifying the graph properties that critically affect their efficiency. In particular, a refined analysis of the convergence upper and lower bounds is performed.
Decentralized Ranking Aggregation: Gossip Algorithms for Borda and Copeland Consensus
Feb 26, 2026The concept of ranking aggregation plays a central role in preference analysis, and numerous algorithms for calculating median rankings, often originating in social choice theory, have been documented in the literature, offering theoretical guarantees in a centralized setting, i.e., when all the ranking data to be aggregated can be brought together in a single computing unit. For many technologies (e.g. peer-to-peer networks, IoT, multi-agent systems), extending the ability to calculate consensus rankings with guarantees in a decentralized setting, i.e., when preference data is initially distributed across a communicating network, remains a major methodological challenge. Indeed, in recent years, the literature on decentralized computation has mainly focused on computing or optimizing statistics such as arithmetic means using gossip algorithms. The purpose of this article is precisely to study how to achieve reliable consensus on collective rankings using classical rules (e.g. Borda, Copeland) in a decentralized setting, thereby raising new questions, robustness to corrupted nodes, and scalability through reduced communication costs in particular. The approach proposed and analyzed here relies on random gossip communication, allowing autonomous agents to compute global ranking consensus using only local interactions, without coordination or central authority. We provide rigorous convergence guarantees, including explicit rate bounds, for the Borda and Copeland consensus methods. Beyond these rules, we also provide a decentralized implementation of consensus according to the median rank rule and local Kemenization. Extensive empirical evaluations on various network topologies and real and synthetic ranking datasets demonstrate that our algorithms converge quickly and reliably to the correct ranking aggregation.
Robust Distributed Learning under Resource Constraints: Decentralized Quantile Estimation via (Asynchronous) ADMM
Jan 28, 2026Specifications for decentralized learning on resource-constrained edge devices require algorithms that are communication-efficient, robust to data corruption, and lightweight in memory usage. While state-of-the-art gossip-based methods satisfy the first requirement, achieving robustness remains challenging. Asynchronous decentralized ADMM-based methods have been explored for estimating the median, a statistical centrality measure that is notoriously more robust than the mean. However, existing approaches require memory that scales with node degree, making them impractical when memory is limited. In this paper, we propose AsylADMM, a novel gossip algorithm for decentralized median and quantile estimation, primarily designed for asynchronous updates and requiring only two variables per node. We analyze a synchronous variant of AsylADMM to establish theoretical guarantees and empirically demonstrate fast convergence for the asynchronous algorithm. We then show that our algorithm enables quantile-based trimming, geometric median estimation, and depth-based trimming, with quantile-based trimming empirically outperforming existing rank-based methods. Finally, we provide a novel theoretical analysis of rank-based trimming via Markov chain theory.
Asynchronous Gossip Algorithms for Rank-Based Statistical Methods
Sep 09, 2025

As decentralized AI and edge intelligence become increasingly prevalent, ensuring robustness and trustworthiness in such distributed settings has become a critical issue-especially in the presence of corrupted or adversarial data. Traditional decentralized algorithms are vulnerable to data contamination as they typically rely on simple statistics (e.g., means or sum), motivating the need for more robust statistics. In line with recent work on decentralized estimation of trimmed means and ranks, we develop gossip algorithms for computing a broad class of rank-based statistics, including L-statistics and rank statistics-both known for their robustness to outliers. We apply our method to perform robust distributed two-sample hypothesis testing, introducing the first gossip algorithm for Wilcoxon rank-sum tests. We provide rigorous convergence guarantees, including the first convergence rate bound for asynchronous gossip-based rank estimation. We empirically validate our theoretical results through experiments on diverse network topologies.
Robust Distributed Estimation: Extending Gossip Algorithms to Ranking and Trimmed Means
May 23, 2025



This paper addresses the problem of robust estimation in gossip algorithms over arbitrary communication graphs. Gossip algorithms are fully decentralized, relying only on local neighbor-to-neighbor communication, making them well-suited for situations where communication is constrained. A fundamental challenge in existing mean-based gossip algorithms is their vulnerability to malicious or corrupted nodes. In this paper, we show that an outlier-robust mean can be computed by globally estimating a robust statistic. More specifically, we propose a novel gossip algorithm for rank estimation, referred to as \textsc{GoRank}, and leverage it to design a gossip procedure dedicated to trimmed mean estimation, coined \textsc{GoTrim}. In addition to a detailed description of the proposed methods, a key contribution of our work is a precise convergence analysis: we establish an $\mathcal{O}(1/t)$ rate for rank estimation and an $\mathcal{O}(\log(t)/t)$ rate for trimmed mean estimation, where by $t$ is meant the number of iterations. Moreover, we provide a breakdown point analysis of \textsc{GoTrim}. We empirically validate our theoretical results through experiments on diverse network topologies, data distributions and contamination schemes.
Differentially Private Policy Gradient
Jan 31, 2025Motivated by the increasing deployment of reinforcement learning in the real world, involving a large consumption of personal data, we introduce a differentially private (DP) policy gradient algorithm. We show that, in this setting, the introduction of Differential Privacy can be reduced to the computation of appropriate trust regions, thus avoiding the sacrifice of theoretical properties of the DP-less methods. Therefore, we show that it is possible to find the right trade-off between privacy noise and trust-region size to obtain a performant differentially private policy gradient algorithm. We then outline its performance empirically on various benchmarks. Our results and the complexity of the tasks addressed represent a significant improvement over existing DP algorithms in online RL.
Differentially Private Model-Based Offline Reinforcement Learning
Feb 08, 2024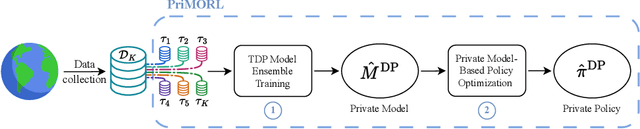



We address offline reinforcement learning with privacy guarantees, where the goal is to train a policy that is differentially private with respect to individual trajectories in the dataset. To achieve this, we introduce DP-MORL, an MBRL algorithm coming with differential privacy guarantees. A private model of the environment is first learned from offline data using DP-FedAvg, a training method for neural networks that provides differential privacy guarantees at the trajectory level. Then, we use model-based policy optimization to derive a policy from the (penalized) private model, without any further interaction with the system or access to the input data. We empirically show that DP-MORL enables the training of private RL agents from offline data and we furthermore outline the price of privacy in this setting.
Clustered Multi-Agent Linear Bandits
Sep 15, 2023



We address in this paper a particular instance of the multi-agent linear stochastic bandit problem, called clustered multi-agent linear bandits. In this setting, we propose a novel algorithm leveraging an efficient collaboration between the agents in order to accelerate the overall optimization problem. In this contribution, a network controller is responsible for estimating the underlying cluster structure of the network and optimizing the experiences sharing among agents within the same groups. We provide a theoretical analysis for both the regret minimization problem and the clustering quality. Through empirical evaluation against state-of-the-art algorithms on both synthetic and real data, we demonstrate the effectiveness of our approach: our algorithm significantly improves regret minimization while managing to recover the true underlying cluster partitioning.
Price of Safety in Linear Best Arm Identification
Sep 15, 2023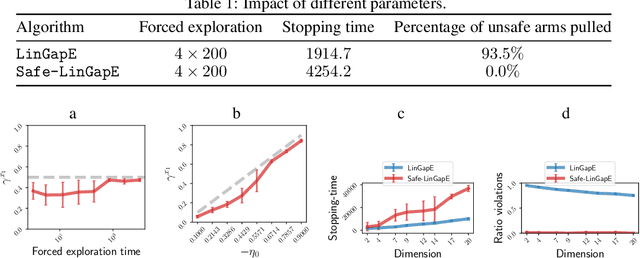
We introduce the safe best-arm identification framework with linear feedback, where the agent is subject to some stage-wise safety constraint that linearly depends on an unknown parameter vector. The agent must take actions in a conservative way so as to ensure that the safety constraint is not violated with high probability at each round. Ways of leveraging the linear structure for ensuring safety has been studied for regret minimization, but not for best-arm identification to the best our knowledge. We propose a gap-based algorithm that achieves meaningful sample complexity while ensuring the stage-wise safety. We show that we pay an extra term in the sample complexity due to the forced exploration phase incurred by the additional safety constraint. Experimental illustrations are provided to justify the design of our algorithm.
An $α$-No-Regret Algorithm For Graphical Bilinear Bandits
Jun 01, 2022
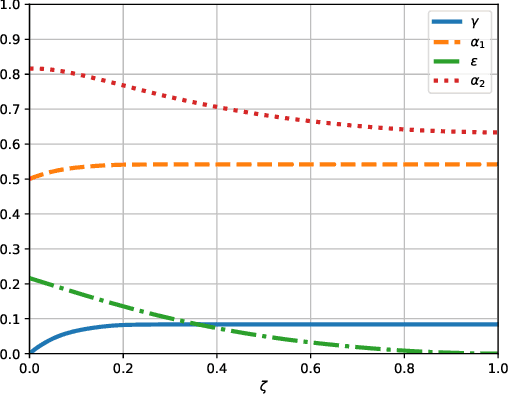
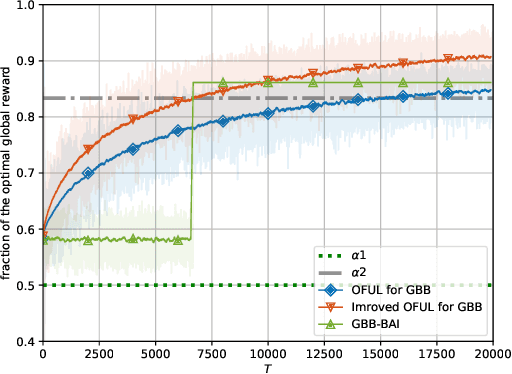
We propose the first regret-based approach to the Graphical Bilinear Bandits problem, where $n$ agents in a graph play a stochastic bilinear bandit game with each of their neighbors. This setting reveals a combinatorial NP-hard problem that prevents the use of any existing regret-based algorithm in the (bi-)linear bandit literature. In this paper, we fill this gap and present the first regret-based algorithm for graphical bilinear bandits using the principle of optimism in the face of uncertainty. Theoretical analysis of this new method yields an upper bound of $\tilde{O}(\sqrt{T})$ on the $\alpha$-regret and evidences the impact of the graph structure on the rate of convergence. Finally, we show through various experiments the validity of our approach.