 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness Cannot be Reduced to Regularization: Studying Adversarial Training Beyond the Linear Case
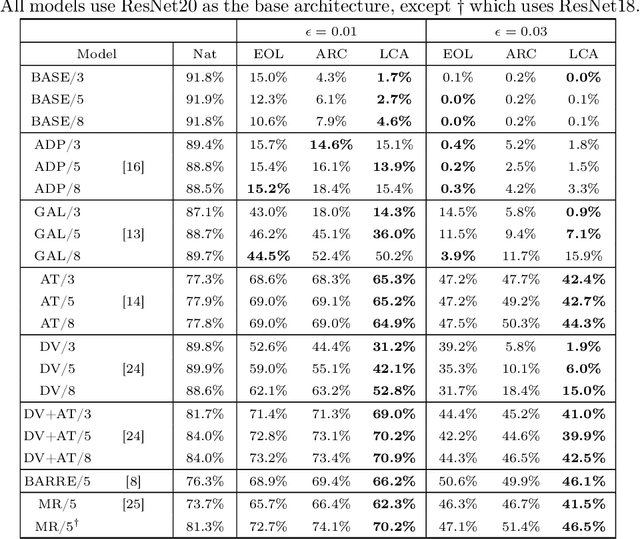
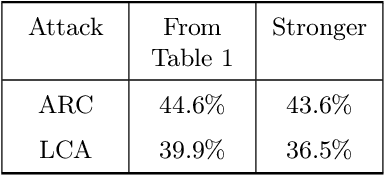
Jun 19, 2026The vulnerability of ML models to adversarial examples has recently emerged as a major concern. While adversarial training is one of the most effective countermeasures to this issue, its high computational cost remains an obstacle to practical deployment. Recent progress in reducing this cost has relied, in the case of linear models, on a formal equivalence between the adversarial risk and a simpler form of regularized risk. This enabled significantly more efficient training procedures, which naturally raises the question of whether such an equivalence can be extended beyond linear models. In this work, we formally show that no such equivalence is possible for two-layer networks. Our proofs proceed via a reduction to key properties that fundamentally separate the adversarial risk from any simple regularized risk which would only exhibit a weak form of data dependence. Beyond this setting, we provide empirical evidence on Wide-ResNets indicating that the same type of impossibility persists in deeper and more expressive architectures.
MetagenBERT: a Transformer-based Architecture using Foundational genomic Large Language Models for novel Metagenome Representation
Jan 05, 2026Metagenomic disease prediction commonly relies on species abundance tables derived from large, incomplete reference catalogs, constraining resolution and discarding valuable information contained in DNA reads. To overcome these limitations, we introduce MetagenBERT, a Transformer based framework that produces end to end metagenome embeddings directly from raw DNA sequences, without taxonomic or functional annotations. Reads are embedded using foundational genomic language models (DNABERT2 and the microbiome specialized DNABERTMS), then aggregated through a scalable clustering strategy based on FAISS accelerated KMeans. Each metagenome is represented as a cluster abundance vector summarizing the distribution of its embedded reads. We evaluate this approach on five benchmark gut microbiome datasets (Cirrhosis, T2D, Obesity, IBD, CRC). MetagenBERT achieves competitive or superior AUC performance relative to species abundance baselines across most tasks. Concatenating both representations further improves prediction, demonstrating complementarity between taxonomic and embedding derived signals. Clustering remains robust when applied to as little as 10% of reads, highlighting substantial redundancy in metagenomes and enabling major computational gains. We additionally introduce MetagenBERT Glob Mcardis, a cross cohort variant trained on the large, phenotypically diverse MetaCardis cohort and transferred to other datasets, retaining predictive signal including for unseen phenotypes, indicating the feasibility of a foundation model for metagenome representation. Robustness analyses (PERMANOVA, PERMDISP, entropy) show consistent separation of different states across subsamples. Overall, MetagenBERT provides a scalable, annotation free representation of metagenomes pointing toward future phenotype aware generalization across heterogeneous cohorts and sequencing technologies.
Lattice Climber Attack: Adversarial attacks for randomized mixtures of classifiers
Jun 12, 2025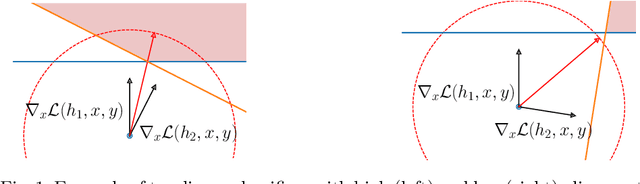
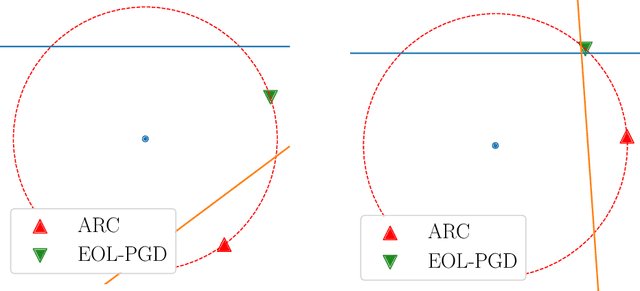
Finite mixtures of classifiers (a.k.a. randomized ensembles) have been proposed as a way to improve robustness against adversarial attacks. However, existing attacks have been shown to not suit this kind of classifier. In this paper, we discuss the problem of attacking a mixture in a principled way and introduce two desirable properties of attacks based on a geometrical analysis of the problem (effectiveness and maximality). We then show that existing attacks do not meet both of these properties. Finally, we introduce a new attack called {\em lattice climber attack} with theoretical guarantees in the binary linear setting, and demonstrate its performance by conducting experiments on synthetic and real datasets.
Improving Discriminator Guidance in Diffusion Models
Mar 20, 2025Discriminator Guidance has become a popular method for efficiently refining pre-trained Score-Matching Diffusion models. However, in this paper, we demonstrate that the standard implementation of this technique does not necessarily lead to a distribution closer to the real data distribution. Specifically, we show that training the discriminator using Cross-Entropy loss, as commonly done, can in fact increase the Kullback-Leibler divergence between the model and target distributions, particularly when the discriminator overfits. To address this, we propose a theoretically sound training objective for discriminator guidance that properly minimizes the KL divergence. We analyze its properties and demonstrate empirically across multiple datasets that our proposed method consistently improves over the conventional method by producing samples of higher quality.
Unveiling the Role of Randomization in Multiclass Adversarial Classification: Insights from Graph Theory
Mar 18, 2025



Randomization as a mean to improve the adversarial robustness of machine learning models has recently attracted significant attention. Unfortunately, much of the theoretical analysis so far has focused on binary classification, providing only limited insights into the more complex multiclass setting. In this paper, we take a step toward closing this gap by drawing inspiration from the field of graph theory. Our analysis focuses on discrete data distributions, allowing us to cast the adversarial risk minimization problems within the well-established framework of set packing problems. By doing so, we are able to identify three structural conditions on the support of the data distribution that are necessary for randomization to improve robustness. Furthermore, we are able to construct several data distributions where (contrarily to binary classification) switching from a deterministic to a randomized solution significantly reduces the optimal adversarial risk. These findings highlight the crucial role randomization can play in enhancing robustness to adversarial attacks in multiclass classification.
Memorization in Attention-only Transformers
Nov 15, 2024



Recent research has explored the memorization capacity of multi-head attention, but these findings are constrained by unrealistic limitations on the context size. We present a novel proof for language-based Transformers that extends the current hypothesis to any context size. Our approach improves upon the state-of-the-art by achieving more effective exact memorization with an attention layer, while also introducing the concept of approximate memorization of distributions. Through experimental validation, we demonstrate that our proposed bounds more accurately reflect the true memorization capacity of language models, and provide a precise comparison with prior work.
Exploring Precision and Recall to assess the quality and diversity of LLMs
Feb 28, 2024



This paper introduces a novel evaluation framework for Large Language Models (LLMs) such as Llama-2 and Mistral, focusing on the adaptation of Precision and Recall metrics from image generation to text generation. This approach allows for a nuanced assessment of the quality and diversity of generated text without the need for aligned corpora. By conducting a comprehensive evaluation of state-of-the-art language models, the study reveals significant insights into their performance on open-ended generation tasks, which are not adequately captured by traditional benchmarks. The findings highlight a trade-off between the quality and diversity of generated samples, particularly when models are fine-tuned with human feedback. This work extends the toolkit for distribution-based NLP evaluation, offering insights into the practical capabilities and challenges faced by current LLMs in generating diverse and high-quality text.
Optimal Budgeted Rejection Sampling for Generative Models
Nov 01, 2023



Rejection sampling methods have recently been proposed to improve the performance of discriminator-based generative models. However, these methods are only optimal under an unlimited sampling budget, and are usually applied to a generator trained independently of the rejection procedure. We first propose an Optimal Budgeted Rejection Sampling (OBRS) scheme that is provably optimal with respect to \textit{any} $f$-divergence between the true distribution and the post-rejection distribution, for a given sampling budget. Second, we propose an end-to-end method that incorporates the sampling scheme into the training procedure to further enhance the model's overall performance. Through experiments and supporting theory, we show that the proposed methods are effective in significantly improving the quality and diversity of the samples.
Adversarial attacks for mixtures of classifiers
Jul 20, 2023



Mixtures of classifiers (a.k.a. randomized ensembles) have been proposed as a way to improve robustness against adversarial attacks. However, it has been shown that existing attacks are not well suited for this kind of classifiers. In this paper, we discuss the problem of attacking a mixture in a principled way and introduce two desirable properties of attacks based on a geometrical analysis of the problem (effectiveness and maximality). We then show that existing attacks do not meet both of these properties. Finally, we introduce a new attack called lattice climber attack with theoretical guarantees on the binary linear setting, and we demonstrate its performance by conducting experiments on synthetic and real datasets.
Precision-Recall Divergence Optimization for Generative Modeling with GANs and Normalizing Flows
May 30, 2023



Achieving a balance between image quality (precision) and diversity (recall) is a significant challenge in the domain of generative models. Current state-of-the-art models primarily rely on optimizing heuristics, such as the Fr\'echet Inception Distance. While recent developments have introduced principled methods for evaluating precision and recall, they have yet to be successfully integrated into the training of generative models. Our main contribution is a novel training method for generative models, such as Generative Adversarial Networks and Normalizing Flows, which explicitly optimizes a user-defined trade-off between precision and recall. More precisely, we show that achieving a specified precision-recall trade-off corresponds to minimizing a unique $f$-divergence from a family we call the \mbox{\em PR-divergences}. Conversely, any $f$-divergence can be written as a linear combination of PR-divergences and corresponds to a weighted precision-recall trade-off. Through comprehensive evaluations, we show that our approach improves the performance of existing state-of-the-art models like BigGAN in terms of either precision or recall when tested on datasets such as ImageNet.