 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond pass@k: Redundancy-Aware RLVR for Multi-Sample Code Generation
May 27, 2026LLMs for code generation are commonly evaluated in repeated-sampling settings using Pass@k, where multiple candidate programs are executed against unit tests under a finite sampling budget. While recent verifier-based reinforcement learning (RLVR) methods improve executable correctness, how these objectives affect redundancy among sampled programs remains poorly understood. In this work, we study implementation-level redundancy in code generation using JPlag, a plagiarism-detection system for code. Across models and benchmarks, we show that correctness-only RLVR often concentrates generations around repeated implementations, whereas Pass@k-aware objectives maintain lower redundancy and improve larger-budget performance. Motivated by these observations, we augment RLVR with direct anti-redundancy rewards based on JPlag similarity. Across 3 models and 3 benchmarks, discouraging near-duplicate generations reliably improves finite-budget executable performance, often matching or outperforming specialized Pass@k-aware objectives.
Equalized Generative Treatment: Matching f-divergences for Fairness in Generative Models
Feb 09, 2026Fairness is a crucial concern for generative models, which not only reflect but can also amplify societal and cultural biases. Existing fairness notions for generative models are largely adapted from classification and focus on balancing the probability of generating samples from each sensitive group. We show that such criteria are brittle, as they can be met even when different sensitive groups are modeled with widely varying quality. To address this limitation, we introduce a new fairness definition for generative models, termed as equalized generative treatment (EGT), which requires comparable generation quality across all sensitive groups, with quality measured via a reference f-divergence. We further analyze the trade-offs induced by EGT, demonstrating that enforcing fairness constraints necessarily couples the overall model quality to that of the most challenging group to approximate. This indicates that a simple yet efficient min-max fine-tuning method should be able to balance f-divergences across sensitive groups to satisfy EGT. We validate this theoretical insight through a set of experiments on both image and text generation tasks. We demonstrate that min-max methods consistently achieve fairer outcomes compared to other approaches from the literature, while maintaining competitive overall performance for both tasks.
Spectral Collapse in Diffusion Inversion
Feb 09, 2026Conditional diffusion inversion provides a powerful framework for unpaired image-to-image translation. However, we demonstrate through an extensive analysis that standard deterministic inversion (e.g. DDIM) fails when the source domain is spectrally sparse compared to the target domain (e.g., super-resolution, sketch-to-image). In these contexts, the recovered latent from the input does not follow the expected isotropic Gaussian distribution. Instead it exhibits a signal with lower frequencies, locking target sampling to oversmoothed and texture-poor generations. We term this phenomenon spectral collapse. We observe that stochastic alternatives attempting to restore the noise variance tend to break the semantic link to the input, leading to structural drift. To resolve this structure-texture trade-off, we propose Orthogonal Variance Guidance (OVG), an inference-time method that corrects the ODE dynamics to enforce the theoretical Gaussian noise magnitude within the null-space of the structural gradient. Extensive experiments on microscopy super-resolution (BBBC021) and sketch-to-image (Edges2Shoes) demonstrate that OVG effectively restores photorealistic textures while preserving structural fidelity.
Improving Discriminator Guidance in Diffusion Models
Mar 20, 2025Discriminator Guidance has become a popular method for efficiently refining pre-trained Score-Matching Diffusion models. However, in this paper, we demonstrate that the standard implementation of this technique does not necessarily lead to a distribution closer to the real data distribution. Specifically, we show that training the discriminator using Cross-Entropy loss, as commonly done, can in fact increase the Kullback-Leibler divergence between the model and target distributions, particularly when the discriminator overfits. To address this, we propose a theoretically sound training objective for discriminator guidance that properly minimizes the KL divergence. We analyze its properties and demonstrate empirically across multiple datasets that our proposed method consistently improves over the conventional method by producing samples of higher quality.
Exploring Precision and Recall to assess the quality and diversity of LLMs
Feb 28, 2024



This paper introduces a novel evaluation framework for Large Language Models (LLMs) such as Llama-2 and Mistral, focusing on the adaptation of Precision and Recall metrics from image generation to text generation. This approach allows for a nuanced assessment of the quality and diversity of generated text without the need for aligned corpora. By conducting a comprehensive evaluation of state-of-the-art language models, the study reveals significant insights into their performance on open-ended generation tasks, which are not adequately captured by traditional benchmarks. The findings highlight a trade-off between the quality and diversity of generated samples, particularly when models are fine-tuned with human feedback. This work extends the toolkit for distribution-based NLP evaluation, offering insights into the practical capabilities and challenges faced by current LLMs in generating diverse and high-quality text.
Optimal Budgeted Rejection Sampling for Generative Models
Nov 01, 2023



Rejection sampling methods have recently been proposed to improve the performance of discriminator-based generative models. However, these methods are only optimal under an unlimited sampling budget, and are usually applied to a generator trained independently of the rejection procedure. We first propose an Optimal Budgeted Rejection Sampling (OBRS) scheme that is provably optimal with respect to \textit{any} $f$-divergence between the true distribution and the post-rejection distribution, for a given sampling budget. Second, we propose an end-to-end method that incorporates the sampling scheme into the training procedure to further enhance the model's overall performance. Through experiments and supporting theory, we show that the proposed methods are effective in significantly improving the quality and diversity of the samples.
Precision-Recall Divergence Optimization for Generative Modeling with GANs and Normalizing Flows
May 30, 2023



Achieving a balance between image quality (precision) and diversity (recall) is a significant challenge in the domain of generative models. Current state-of-the-art models primarily rely on optimizing heuristics, such as the Fr\'echet Inception Distance. While recent developments have introduced principled methods for evaluating precision and recall, they have yet to be successfully integrated into the training of generative models. Our main contribution is a novel training method for generative models, such as Generative Adversarial Networks and Normalizing Flows, which explicitly optimizes a user-defined trade-off between precision and recall. More precisely, we show that achieving a specified precision-recall trade-off corresponds to minimizing a unique $f$-divergence from a family we call the \mbox{\em PR-divergences}. Conversely, any $f$-divergence can be written as a linear combination of PR-divergences and corresponds to a weighted precision-recall trade-off. Through comprehensive evaluations, we show that our approach improves the performance of existing state-of-the-art models like BigGAN in terms of either precision or recall when tested on datasets such as ImageNet.
Training Normalizing Flows with the Precision-Recall Divergence
Feb 02, 2023



Generative models can have distinct mode of failures like mode dropping and low quality samples, which cannot be captured by a single scalar metric. To address this, recent works propose evaluating generative models using precision and recall, where precision measures quality of samples and recall measures the coverage of the target distribution. Although a variety of discrepancy measures between the target and estimated distribution are used to train generative models, it is unclear what precision-recall trade-offs are achieved by various choices of the discrepancy measures. In this paper, we show that achieving a specified precision-recall trade-off corresponds to minimising -divergences from a family we call the {\em PR-divergences }. Conversely, any -divergence can be written as a linear combination of PR-divergences and therefore correspond to minimising a weighted precision-recall trade-off. Further, we propose a novel generative model that is able to train a normalizing flow to minimise any -divergence, and in particular, achieve a given precision-recall trade-off.
On the expressivity of bi-Lipschitz normalizing flows
Jul 15, 2021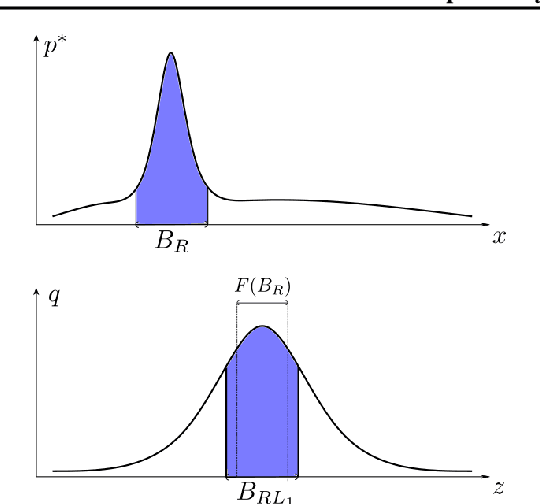
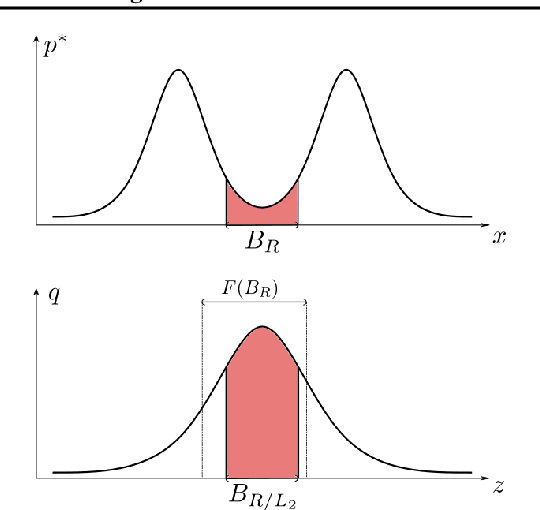
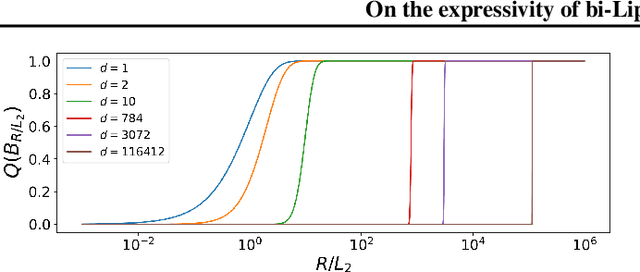

An invertible function is bi-Lipschitz if both the function and its inverse have bounded Lipschitz constants. Nowadays, most Normalizing Flows are bi-Lipschitz by design or by training to limit numerical errors (among other things). In this paper, we discuss the expressivity of bi-Lipschitz Normalizing Flows and identify several target distributions that are difficult to approximate using such models. Then, we characterize the expressivity of bi-Lipschitz Normalizing Flows by giving several lower bounds on the Total Variation distance between these particularly unfavorable distributions and their best possible approximation. Finally, we discuss potential remedies which include using more complex latent distributions.