 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Obfuscated Code through Graph-Based Semantic Analysis of Binary Code
Apr 02, 2025Protecting sensitive program content is a critical issue in various situations, ranging from legitimate use cases to unethical contexts. Obfuscation is one of the most used techniques to ensure such protection. Consequently, attackers must first detect and characterize obfuscation before launching any attack against it. This paper investigates the problem of function-level obfuscation detection using graph-based approaches, comparing algorithms, from elementary baselines to promising techniques like GNN (Graph Neural Networks), on different feature choices. We consider various obfuscation types and obfuscators, resulting in two complex datasets. Our findings demonstrate that GNNs need meaningful features that capture aspects of function semantics to outperform baselines. Our approach shows satisfactory results, especially in a challenging 11-class classification task and in a practical malware analysis example.
Meta-survey on outlier and anomaly detection
Dec 12, 2023



The impact of outliers and anomalies on model estimation and data processing is of paramount importance, as evidenced by the extensive body of research spanning various fields over several decades: thousands of research papers have been published on the subject. As a consequence, numerous reviews, surveys, and textbooks have sought to summarize the existing literature, encompassing a wide range of methods from both the statistical and data mining communities. While these endeavors to organize and summarize the research are invaluable, they face inherent challenges due to the pervasive nature of outliers and anomalies in all data-intensive applications, irrespective of the specific application field or scientific discipline. As a result, the resulting collection of papers remains voluminous and somewhat heterogeneous. To address the need for knowledge organization in this domain, this paper implements the first systematic meta-survey of general surveys and reviews on outlier and anomaly detection. Employing a classical systematic survey approach, the study collects nearly 500 papers using two specialized scientific search engines. From this comprehensive collection, a subset of 56 papers that claim to be general surveys on outlier detection is selected using a snowball search technique to enhance field coverage. A meticulous quality assessment phase further refines the selection to a subset of 25 high-quality general surveys. Using this curated collection, the paper investigates the evolution of the outlier detection field over a 20-year period, revealing emerging themes and methods. Furthermore, an analysis of the surveys sheds light on the survey writing practices adopted by scholars from different communities who have contributed to this field. Finally, the paper delves into several topics where consensus has emerged from the literature. These include taxonomies of outlier types, challenges posed by high-dimensional data, the importance of anomaly scores, the impact of learning conditions, difficulties in benchmarking, and the significance of neural networks. Non-consensual aspects are also discussed, particularly the distinction between local and global outliers and the challenges in organizing detection methods into meaningful taxonomies.
Mixture of von Mises-Fisher distribution with sparse prototypes
Dec 30, 2022Mixtures of von Mises-Fisher distributions can be used to cluster data on the unit hypersphere. This is particularly adapted for high-dimensional directional data such as texts. We propose in this article to estimate a von Mises mixture using a l 1 penalized likelihood. This leads to sparse prototypes that improve clustering interpretability. We introduce an expectation-maximisation (EM) algorithm for this estimation and explore the trade-off between the sparsity term and the likelihood one with a path following algorithm. The model's behaviour is studied on simulated data and, we show the advantages of the approach on real data benchmark. We also introduce a new data set on financial reports and exhibit the benefits of our method for exploratory analysis.
Fast and fully-automated histograms for large-scale data sets
Dec 27, 2022G-Enum histograms are a new fast and fully automated method for irregular histogram construction. By framing histogram construction as a density estimation problem and its automation as a model selection task, these histograms leverage the Minimum Description Length principle (MDL) to derive two different model selection criteria. Several proven theoretical results about these criteria give insights about their asymptotic behavior and are used to speed up their optimisation. These insights, combined to a greedy search heuristic, are used to construct histograms in linearithmic time rather than the polynomial time incurred by previous works. The capabilities of the proposed MDL density estimation method are illustrated with reference to other fully automated methods in the literature, both on synthetic and large real-world data sets.
Challenges in anomaly and change point detection
Dec 27, 2022This paper presents an introduction to the state-of-the-art in anomaly and change-point detection. On the one hand, the main concepts needed to understand the vast scientific literature on those subjects are introduced. On the other, a selection of important surveys and books, as well as two selected active research topics in the field, are presented.
Model Based Co-clustering of Mixed Numerical and Binary Data
Dec 22, 2022Co-clustering is a data mining technique used to extract the underlying block structure between the rows and columns of a data matrix. Many approaches have been studied and have shown their capacity to extract such structures in continuous, binary or contingency tables. However, very little work has been done to perform co-clustering on mixed type data. In this article, we extend the latent block models based co-clustering to the case of mixed data (continuous and binary variables). We then evaluate the effectiveness of the proposed approach on simulated data and we discuss its advantages and potential limits.
Federated Learning -- Methods, Applications and beyond
Dec 22, 2022In recent years the applications of machine learning models have increased rapidly, due to the large amount of available data and technological progress.While some domains like web analysis can benefit from this with only minor restrictions, other fields like in medicine with patient data are strongerregulated. In particular \emph{data privacy} plays an important role as recently highlighted by the trustworthy AI initiative of the EU or general privacy regulations in legislation. Another major challenge is, that the required training \emph{data is} often \emph{distributed} in terms of features or samples and unavailable for classicalbatch learning approaches. In 2016 Google came up with a framework, called \emph{Federated Learning} to solve both of these problems. We provide a brief overview on existing Methods and Applications in the field of vertical and horizontal \emph{Federated Learning}, as well as \emph{Fderated Transfer Learning}.
Co-clustering based exploratory analysis of mixed-type data tables
Dec 22, 2022Co-clustering is a class of unsupervised data analysis techniques that extract the existing underlying dependency structure between the instances and variables of a data table as homogeneous blocks. Most of those techniques are limited to variables of the same type. In this paper, we propose a mixed data co-clustering method based on a two-step methodology. In the first step, all the variables are binarized according to a number of bins chosen by the analyst, by equal frequency discretization in the numerical case, or keeping the most frequent values in the categorical case. The second step applies a co-clustering to the instances and the binary variables, leading to groups of instances and groups of variable parts. We apply this methodology on several data sets and compare with the results of a Multiple Correspondence Analysis applied to the same data.
The State of the Art in Enhancing Trust in Machine Learning Models with the Use of Visualizations
Dec 22, 2022Machine learning (ML) models are nowadays used in complex applications in various domains, such as medicine, bioinformatics, and other sciences. Due to their black box nature, however, it may sometimes be hard to understand and trust the results they provide. This has increased the demand for reliable visualization tools related to enhancing trust in ML models, which has become a prominent topic of research in the visualization community over the past decades. To provide an overview and present the frontiers of current research on the topic, we present a State-of-the-Art Report (STAR) on enhancing trust in ML models with the use of interactive visualization. We define and describe the background of the topic, introduce a categorization for visualization techniques that aim to accomplish this goal, and discuss insights and opportunities for future research directions. Among our contributions is a categorization of trust against different facets of interactive ML, expanded and improved from previous research. Our results are investigated from different analytical perspectives: (a) providing a statistical overview, (b) summarizing key findings, (c) performing topic analyses, and (d) exploring the data sets used in the individual papers, all with the support of an interactive web-based survey browser. We intend this survey to be beneficial for visualization researchers whose interests involve making ML models more trustworthy, as well as researchers and practitioners from other disciplines in their search for effective visualization techniques suitable for solving their tasks with confidence and conveying meaning to their data.
Binary Diffing as a Network Alignment Problem via Belief Propagation
Dec 31, 2021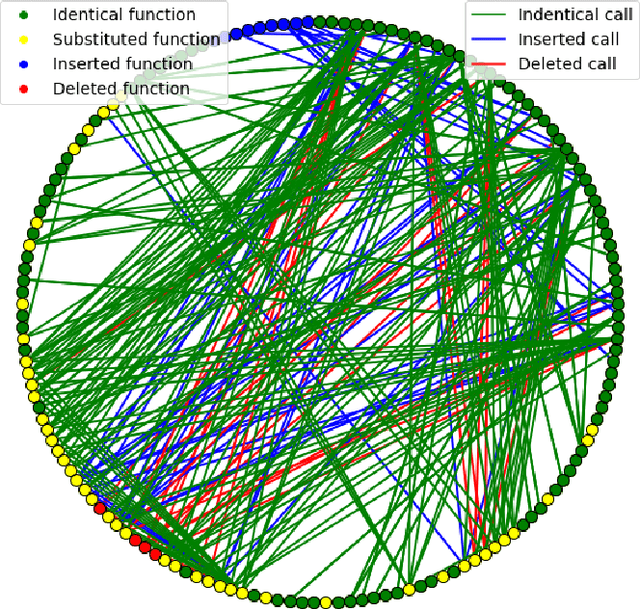
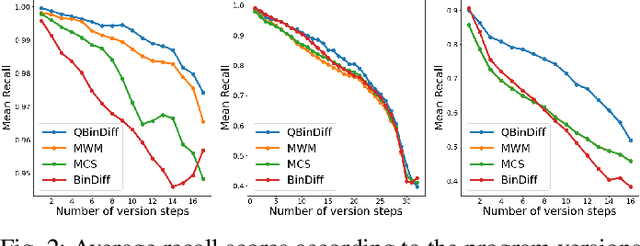
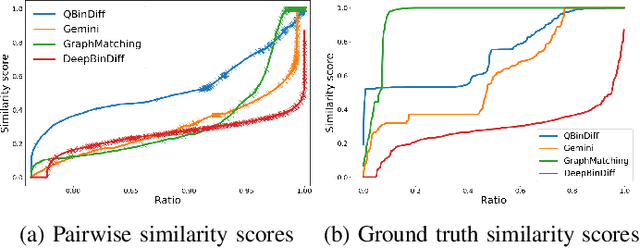
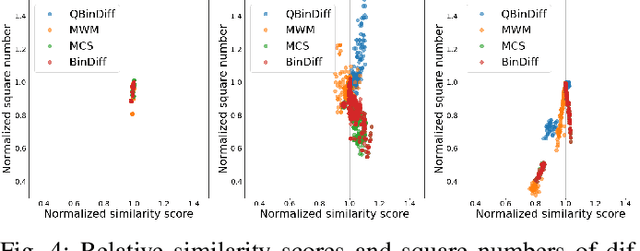
In this paper, we address the problem of finding a correspondence, or matching, between the functions of two programs in binary form, which is one of the most common task in binary diffing. We introduce a new formulation of this problem as a particular instance of a graph edit problem over the call graphs of the programs. In this formulation, the quality of a mapping is evaluated simultaneously with respect to both function content and call graph similarities. We show that this formulation is equivalent to a network alignment problem. We propose a solving strategy for this problem based on max-product belief propagation. Finally, we implement a prototype of our method, called QBinDiff, and propose an extensive evaluation which shows that our approach outperforms state of the art diffing tools.