 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Uncertainty-Informed Sampling from Federated Streaming Data
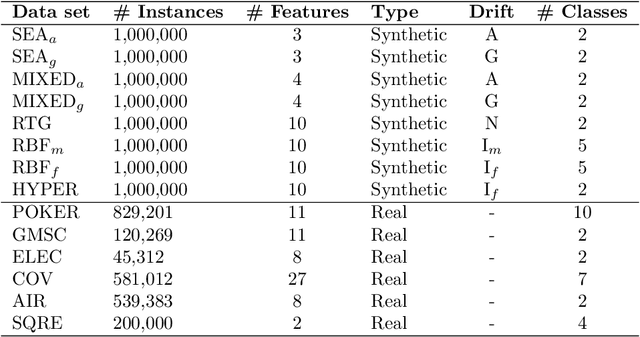
Aug 30, 2024We present a numerically robust, computationally efficient approach for non-I.I.D. data stream sampling in federated client systems, where resources are limited and labeled data for local model adaptation is sparse and expensive. The proposed method identifies relevant stream observations to optimize the underlying client model, given a local labeling budget, and performs instantaneous labeling decisions without relying on any memory buffering strategies. Our experiments show enhanced training batch diversity and an improved numerical robustness of the proposal compared to existing strategies over large-scale data streams, making our approach an effective and convenient solution in FL environments.
Efficient Cross-Domain Federated Learning by MixStyle Approximation
Dec 12, 2023With the advent of interconnected and sensor-equipped edge devices, Federated Learning (FL) has gained significant attention, enabling decentralized learning while maintaining data privacy. However, FL faces two challenges in real-world tasks: expensive data labeling and domain shift between source and target samples. In this paper, we introduce a privacy-preserving, resource-efficient FL concept for client adaptation in hardware-constrained environments. Our approach includes server model pre-training on source data and subsequent fine-tuning on target data via low-end clients. The local client adaptation process is streamlined by probabilistic mixing of instance-level feature statistics approximated from source and target domain data. The adapted parameters are transferred back to the central server and globally aggregated. Preliminary results indicate that our method reduces computational and transmission costs while maintaining competitive performance on downstream tasks.
Federated Learning -- Methods, Applications and beyond
Dec 22, 2022


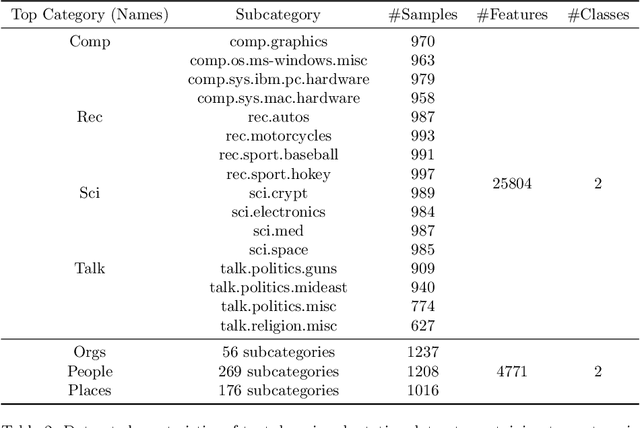
In recent years the applications of machine learning models have increased rapidly, due to the large amount of available data and technological progress.While some domains like web analysis can benefit from this with only minor restrictions, other fields like in medicine with patient data are strongerregulated. In particular \emph{data privacy} plays an important role as recently highlighted by the trustworthy AI initiative of the EU or general privacy regulations in legislation. Another major challenge is, that the required training \emph{data is} often \emph{distributed} in terms of features or samples and unavailable for classicalbatch learning approaches. In 2016 Google came up with a framework, called \emph{Federated Learning} to solve both of these problems. We provide a brief overview on existing Methods and Applications in the field of vertical and horizontal \emph{Federated Learning}, as well as \emph{Fderated Transfer Learning}.
Revisiting Memory Efficient Kernel Approximation: An Indefinite Learning Perspective
Jan 20, 2022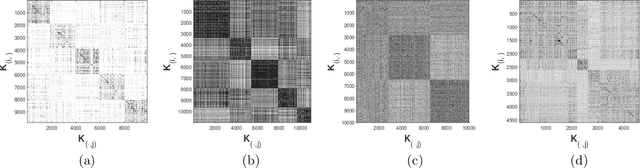
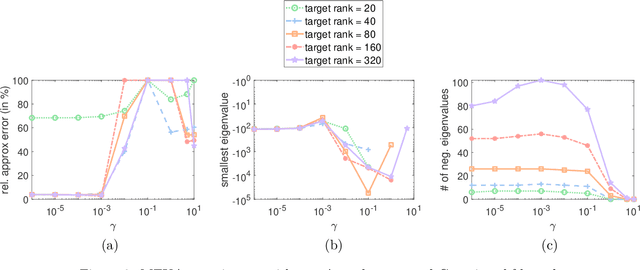
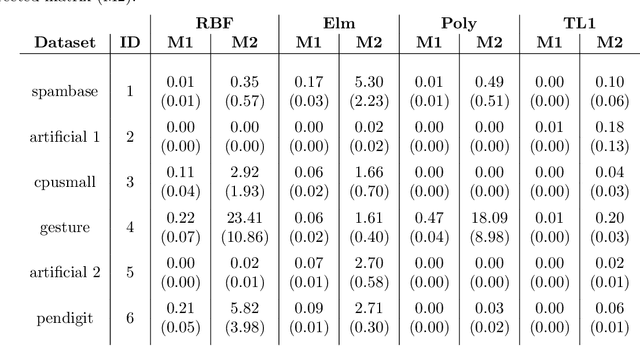
Matrix approximations are a key element in large-scale algebraic machine learning approaches. The recently proposed method MEKA (Si et al., 2014) effectively employs two common assumptions in Hilbert spaces: the low-rank property of an inner product matrix obtained from a shift-invariant kernel function and a data compactness hypothesis by means of an inherent block-cluster structure. In this work, we extend MEKA to be applicable not only for shift-invariant kernels but also for non-stationary kernels like polynomial kernels and an extreme learning kernel. We also address in detail how to handle non-positive semi-definite kernel functions within MEKA, either caused by the approximation itself or by the intentional use of general kernel functions. We present a Lanczos-based estimation of a spectrum shift to develop a stable positive semi-definite MEKA approximation, also usable in classical convex optimization frameworks. Furthermore, we support our findings with theoretical considerations and a variety of experiments on synthetic and real-world data.
Complex-valued embeddings of generic proximity data
Aug 31, 2020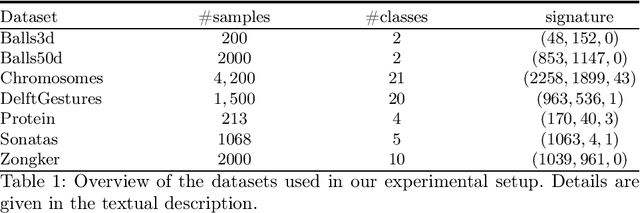
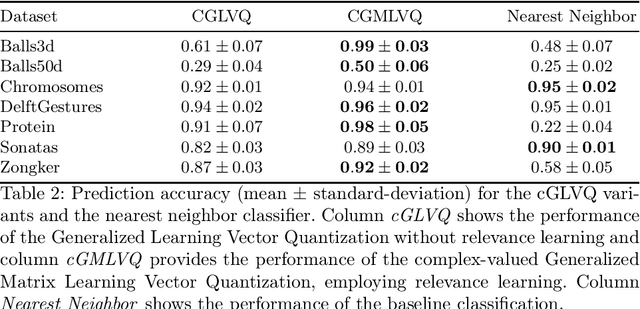
Proximities are at the heart of almost all machine learning methods. If the input data are given as numerical vectors of equal lengths, euclidean distance, or a Hilbertian inner product is frequently used in modeling algorithms. In a more generic view, objects are compared by a (symmetric) similarity or dissimilarity measure, which may not obey particular mathematical properties. This renders many machine learning methods invalid, leading to convergence problems and the loss of guarantees, like generalization bounds. In many cases, the preferred dissimilarity measure is not metric, like the earth mover distance, or the similarity measure may not be a simple inner product in a Hilbert space but in its generalization a Krein space. If the input data are non-vectorial, like text sequences, proximity-based learning is used or ngram embedding techniques can be applied. Standard embeddings lead to the desired fixed-length vector encoding, but are costly and have substantial limitations in preserving the original data's full information. As an information preserving alternative, we propose a complex-valued vector embedding of proximity data. This allows suitable machine learning algorithms to use these fixed-length, complex-valued vectors for further processing. The complex-valued data can serve as an input to complex-valued machine learning algorithms. In particular, we address supervised learning and use extensions of prototype-based learning. The proposed approach is evaluated on a variety of standard benchmarks and shows strong performance compared to traditional techniques in processing non-metric or non-psd proximity data.
Transfer learning extensions for the probabilistic classification vector machine
Jul 11, 2020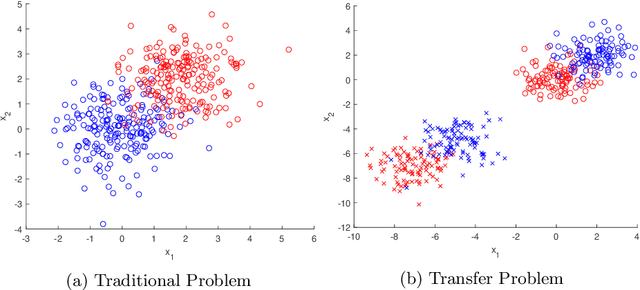
Transfer learning is focused on the reuse of supervised learning models in a new context. Prominent applications can be found in robotics, image processing or web mining. In these fields, the learning scenarios are naturally changing but often remain related to each other motivating the reuse of existing supervised models. Current transfer learning models are neither sparse nor interpretable. Sparsity is very desirable if the methods have to be used in technically limited environments and interpretability is getting more critical due to privacy regulations. In this work, we propose two transfer learning extensions integrated into the sparse and interpretable probabilistic classification vector machine. They are compared to standard benchmarks in the field and show their relevance either by sparsity or performance improvements.
* arXiv admin note: text overlap with arXiv:1907.01343
Reactive Soft Prototype Computing for Concept Drift Streams
Jul 10, 2020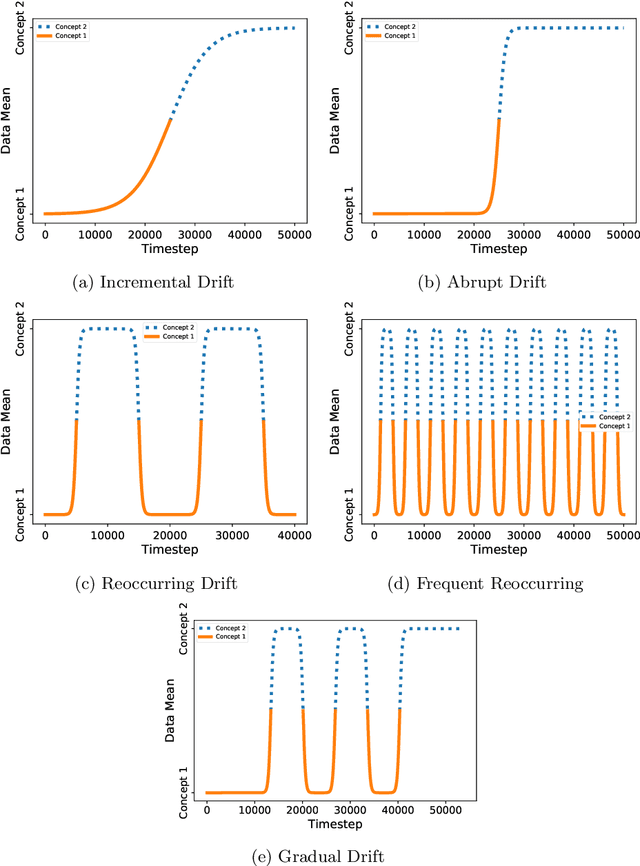
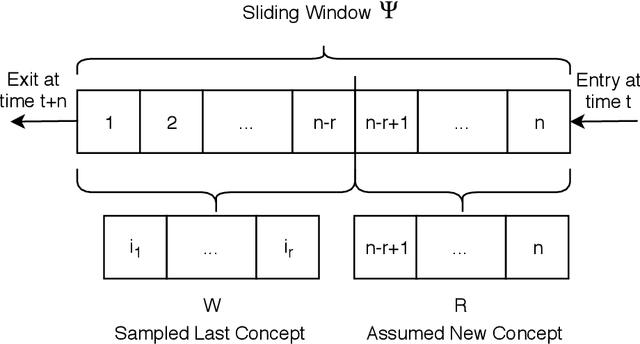

The amount of real-time communication between agents in an information system has increased rapidly since the beginning of the decade. This is because the use of these systems, e. g. social media, has become commonplace in today's society. This requires analytical algorithms to learn and predict this stream of information in real-time. The nature of these systems is non-static and can be explained, among other things, by the fast pace of trends. This creates an environment in which algorithms must recognize changes and adapt. Recent work shows vital research in the field, but mainly lack stable performance during model adaptation. In this work, a concept drift detection strategy followed by a prototype-based adaptation strategy is proposed. Validated through experimental results on a variety of typical non-static data, our solution provides stable and quick adjustments in times of change.
Domain Adaptation via Low-Rank Basis Approximation
Jul 02, 2019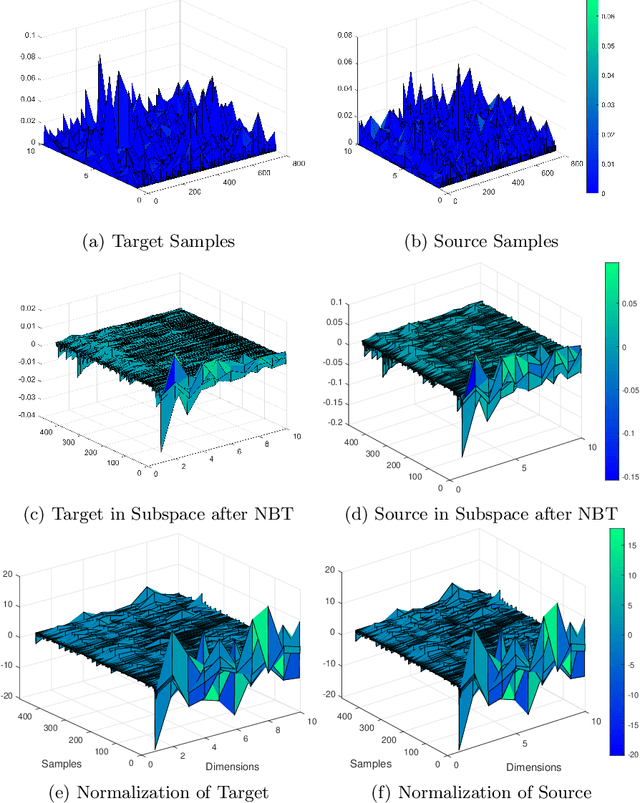
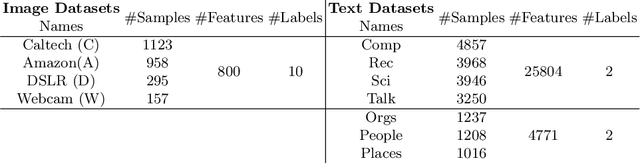
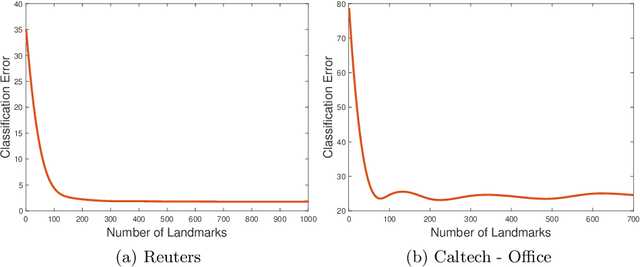

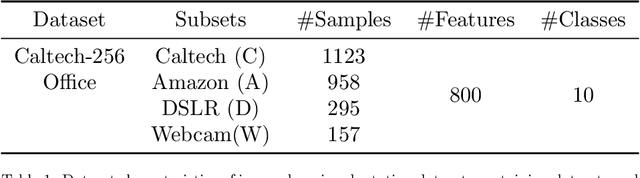
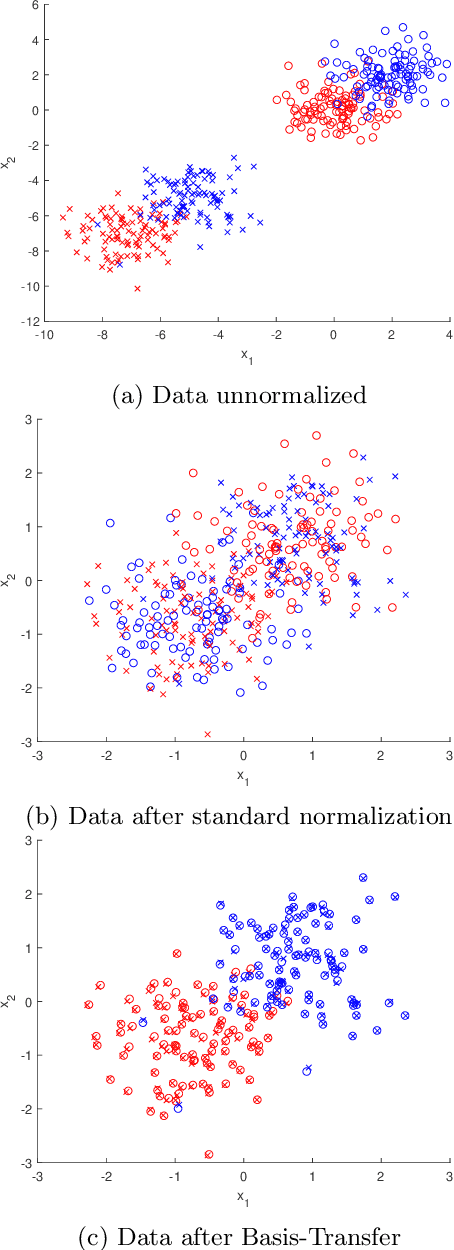
Transfer learning focuses on the reuse of supervised learning models in a new context. Prominent applications can be found in robotics, image processing or web mining. In these areas, learning scenarios change by nature, but often remain related and motivate the reuse of existing supervised models. While the majority of symmetric and asymmetric domain adaptation algorithms utilize all available source and target domain data, we show that domain adaptation requires only a substantial smaller subset. This makes it more suitable for real-world scenarios where target domain data is rare. The presented approach finds a target subspace representation for source and target data to address domain differences by orthogonal basis transfer. We employ Nystr\"om techniques and show the reliability of this approximation without a particular landmark matrix by applying post-transfer normalization. It is evaluated on typical domain adaptation tasks with standard benchmark data.
Probabilistic classifiers with low rank indefinite kernels
Apr 08, 2016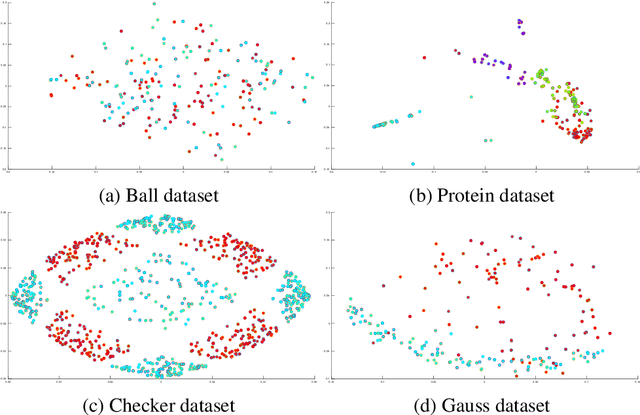

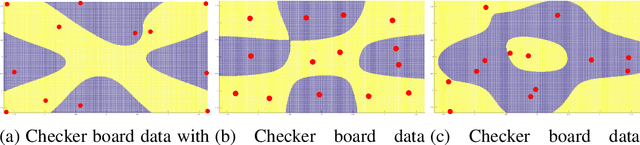
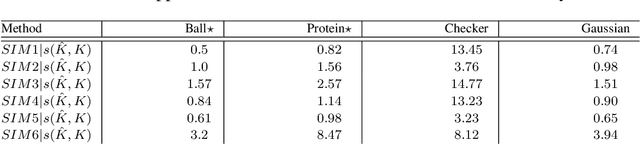
Indefinite similarity measures can be frequently found in bio-informatics by means of alignment scores, but are also common in other fields like shape measures in image retrieval. Lacking an underlying vector space, the data are given as pairwise similarities only. The few algorithms available for such data do not scale to larger datasets. Focusing on probabilistic batch classifiers, the Indefinite Kernel Fisher Discriminant (iKFD) and the Probabilistic Classification Vector Machine (PCVM) are both effective algorithms for this type of data but, with cubic complexity. Here we propose an extension of iKFD and PCVM such that linear runtime and memory complexity is achieved for low rank indefinite kernels. Employing the Nystr\"om approximation for indefinite kernels, we also propose a new almost parameter free approach to identify the landmarks, restricted to a supervised learning problem. Evaluations at several larger similarity data from various domains show that the proposed methods provides similar generalization capabilities while being easier to parametrize and substantially faster for large scale data.