 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning -- Methods, Applications and beyond
Dec 22, 2022


In recent years the applications of machine learning models have increased rapidly, due to the large amount of available data and technological progress.While some domains like web analysis can benefit from this with only minor restrictions, other fields like in medicine with patient data are strongerregulated. In particular \emph{data privacy} plays an important role as recently highlighted by the trustworthy AI initiative of the EU or general privacy regulations in legislation. Another major challenge is, that the required training \emph{data is} often \emph{distributed} in terms of features or samples and unavailable for classicalbatch learning approaches. In 2016 Google came up with a framework, called \emph{Federated Learning} to solve both of these problems. We provide a brief overview on existing Methods and Applications in the field of vertical and horizontal \emph{Federated Learning}, as well as \emph{Fderated Transfer Learning}.
Transfer learning extensions for the probabilistic classification vector machine
Jul 11, 2020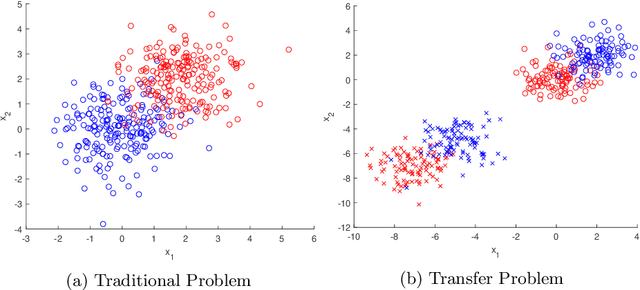
Transfer learning is focused on the reuse of supervised learning models in a new context. Prominent applications can be found in robotics, image processing or web mining. In these fields, the learning scenarios are naturally changing but often remain related to each other motivating the reuse of existing supervised models. Current transfer learning models are neither sparse nor interpretable. Sparsity is very desirable if the methods have to be used in technically limited environments and interpretability is getting more critical due to privacy regulations. In this work, we propose two transfer learning extensions integrated into the sparse and interpretable probabilistic classification vector machine. They are compared to standard benchmarks in the field and show their relevance either by sparsity or performance improvements.
* arXiv admin note: text overlap with arXiv:1907.01343
Reactive Soft Prototype Computing for Concept Drift Streams
Jul 10, 2020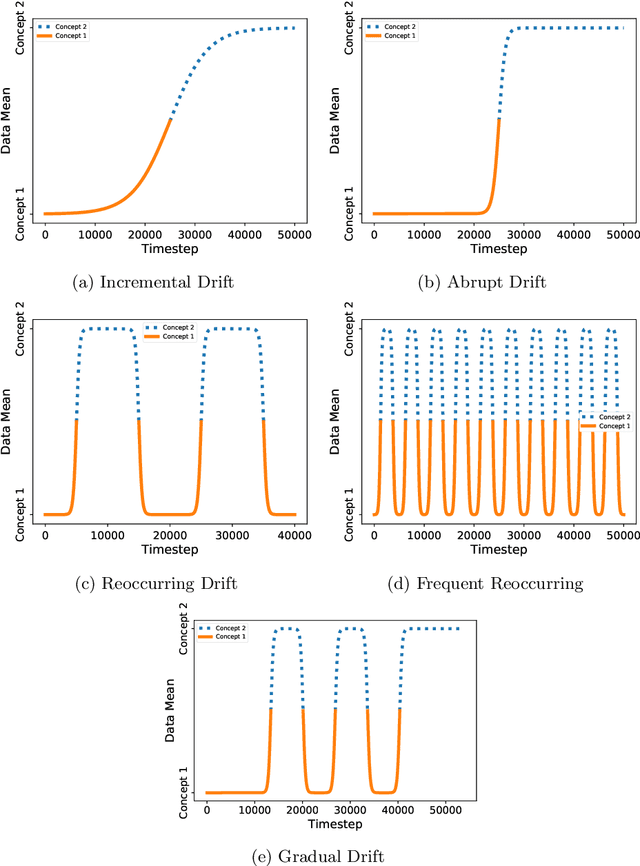
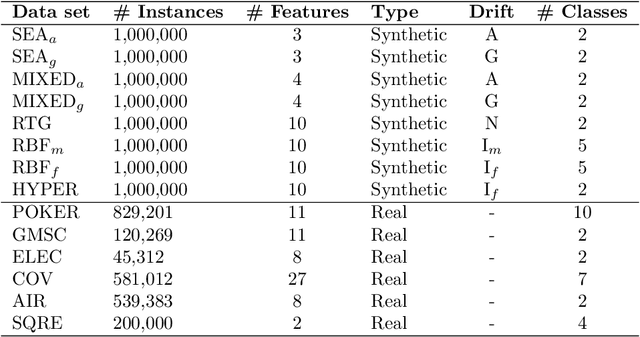
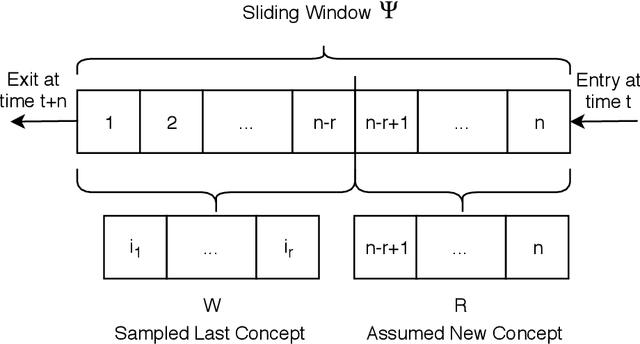

The amount of real-time communication between agents in an information system has increased rapidly since the beginning of the decade. This is because the use of these systems, e. g. social media, has become commonplace in today's society. This requires analytical algorithms to learn and predict this stream of information in real-time. The nature of these systems is non-static and can be explained, among other things, by the fast pace of trends. This creates an environment in which algorithms must recognize changes and adapt. Recent work shows vital research in the field, but mainly lack stable performance during model adaptation. In this work, a concept drift detection strategy followed by a prototype-based adaptation strategy is proposed. Validated through experimental results on a variety of typical non-static data, our solution provides stable and quick adjustments in times of change.
Domain Adaptation via Low-Rank Basis Approximation
Jul 02, 2019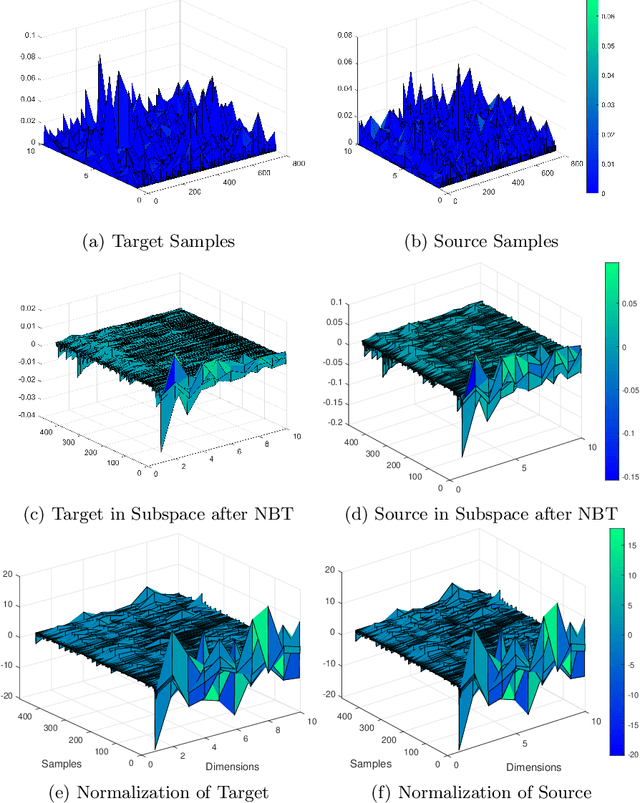
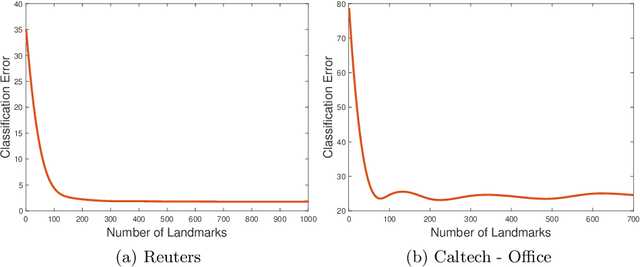

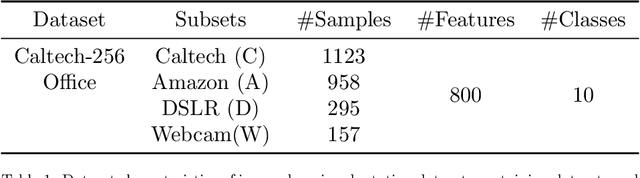
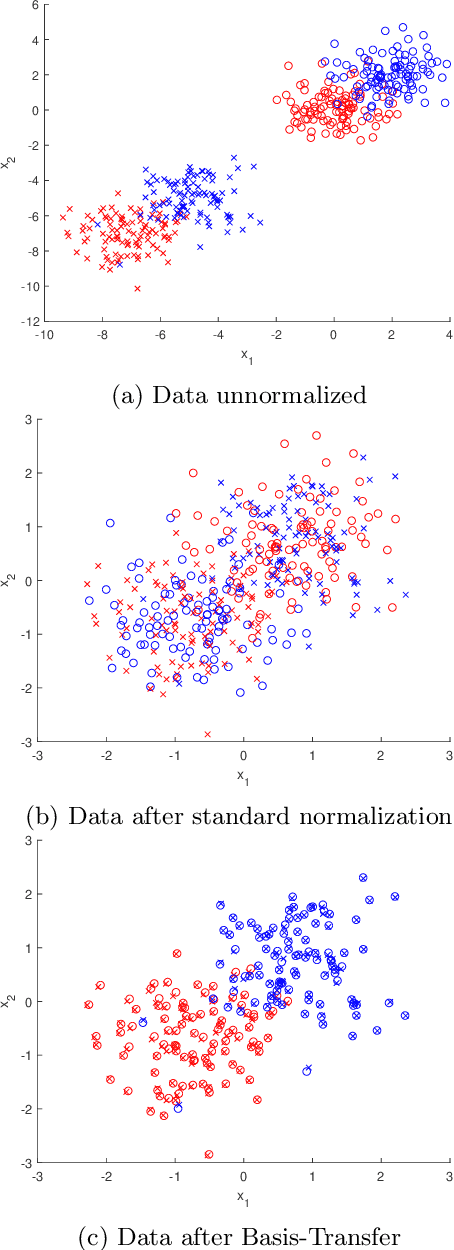
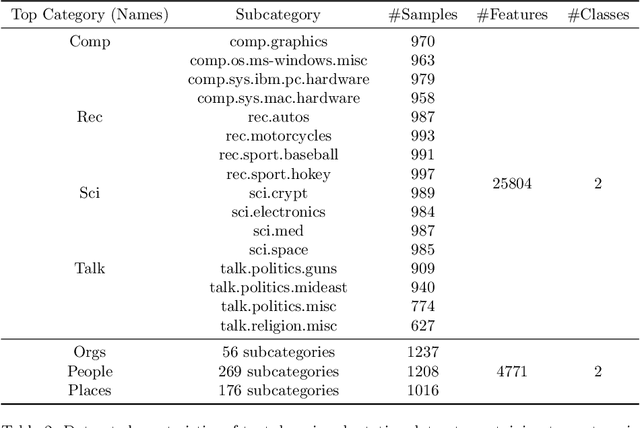
Transfer learning focuses on the reuse of supervised learning models in a new context. Prominent applications can be found in robotics, image processing or web mining. In these areas, learning scenarios change by nature, but often remain related and motivate the reuse of existing supervised models. While the majority of symmetric and asymmetric domain adaptation algorithms utilize all available source and target domain data, we show that domain adaptation requires only a substantial smaller subset. This makes it more suitable for real-world scenarios where target domain data is rare. The presented approach finds a target subspace representation for source and target data to address domain differences by orthogonal basis transfer. We employ Nystr\"om techniques and show the reliability of this approximation without a particular landmark matrix by applying post-transfer normalization. It is evaluated on typical domain adaptation tasks with standard benchmark data.