 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex-valued embeddings of generic proximity data
Paper and Code
Aug 31, 2020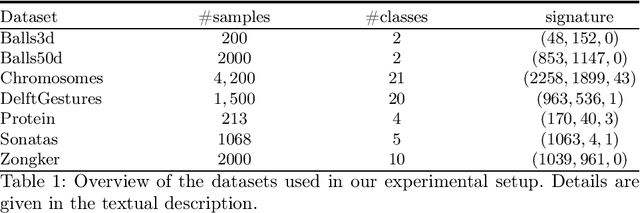
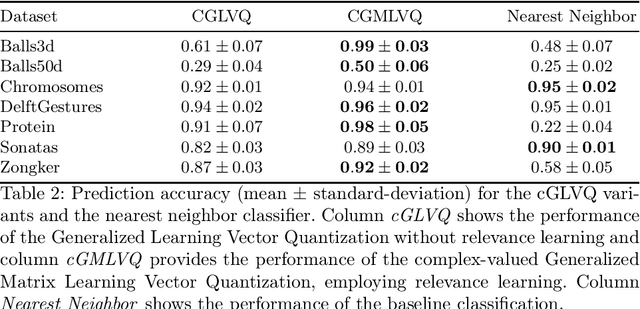
Proximities are at the heart of almost all machine learning methods. If the input data are given as numerical vectors of equal lengths, euclidean distance, or a Hilbertian inner product is frequently used in modeling algorithms. In a more generic view, objects are compared by a (symmetric) similarity or dissimilarity measure, which may not obey particular mathematical properties. This renders many machine learning methods invalid, leading to convergence problems and the loss of guarantees, like generalization bounds. In many cases, the preferred dissimilarity measure is not metric, like the earth mover distance, or the similarity measure may not be a simple inner product in a Hilbert space but in its generalization a Krein space. If the input data are non-vectorial, like text sequences, proximity-based learning is used or ngram embedding techniques can be applied. Standard embeddings lead to the desired fixed-length vector encoding, but are costly and have substantial limitations in preserving the original data's full information. As an information preserving alternative, we propose a complex-valued vector embedding of proximity data. This allows suitable machine learning algorithms to use these fixed-length, complex-valued vectors for further processing. The complex-valued data can serve as an input to complex-valued machine learning algorithms. In particular, we address supervised learning and use extensions of prototype-based learning. The proposed approach is evaluated on a variety of standard benchmarks and shows strong performance compared to traditional techniques in processing non-metric or non-psd proximity data.