 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Shapley Value Computation for the Naive Bayes Classifier
Jul 31, 2023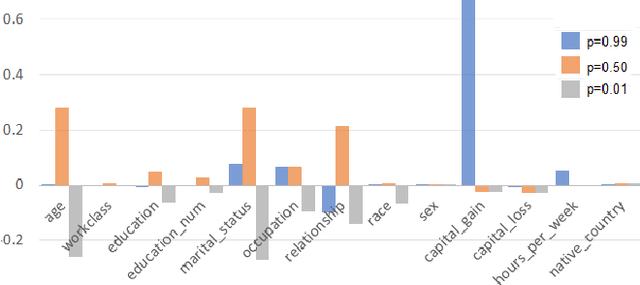
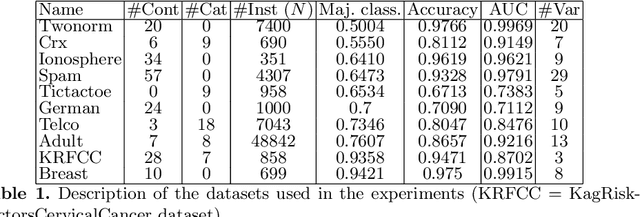
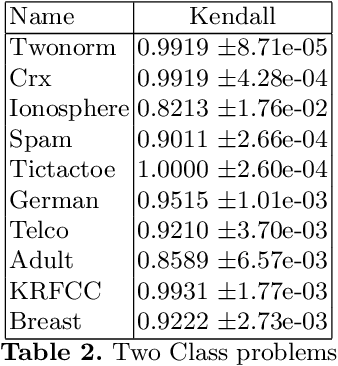
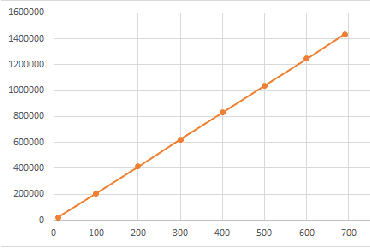
Variable selection or importance measurement of input variables to a machine learning model has become the focus of much research. It is no longer enough to have a good model, one also must explain its decisions. This is why there are so many intelligibility algorithms available today. Among them, Shapley value estimation algorithms are intelligibility methods based on cooperative game theory. In the case of the naive Bayes classifier, and to our knowledge, there is no ``analytical" formulation of Shapley values. This article proposes an exact analytic expression of Shapley values in the special case of the naive Bayes Classifier. We analytically compare this Shapley proposal, to another frequently used indicator, the Weight of Evidence (WoE) and provide an empirical comparison of our proposal with (i) the WoE and (ii) KernelShap results on real world datasets, discussing similar and dissimilar results. The results show that our Shapley proposal for the naive Bayes classifier provides informative results with low algorithmic complexity so that it can be used on very large datasets with extremely low computation time.
Co-clustering based exploratory analysis of mixed-type data tables
Dec 22, 2022Co-clustering is a class of unsupervised data analysis techniques that extract the existing underlying dependency structure between the instances and variables of a data table as homogeneous blocks. Most of those techniques are limited to variables of the same type. In this paper, we propose a mixed data co-clustering method based on a two-step methodology. In the first step, all the variables are binarized according to a number of bins chosen by the analyst, by equal frequency discretization in the numerical case, or keeping the most frequent values in the categorical case. The second step applies a co-clustering to the instances and the binary variables, leading to groups of instances and groups of variable parts. We apply this methodology on several data sets and compare with the results of a Multiple Correspondence Analysis applied to the same data.
Model Based Co-clustering of Mixed Numerical and Binary Data
Dec 22, 2022Co-clustering is a data mining technique used to extract the underlying block structure between the rows and columns of a data matrix. Many approaches have been studied and have shown their capacity to extract such structures in continuous, binary or contingency tables. However, very little work has been done to perform co-clustering on mixed type data. In this article, we extend the latent block models based co-clustering to the case of mixed data (continuous and binary variables). We then evaluate the effectiveness of the proposed approach on simulated data and we discuss its advantages and potential limits.
Open challenges for Machine Learning based Early Decision-Making research
Apr 27, 2022
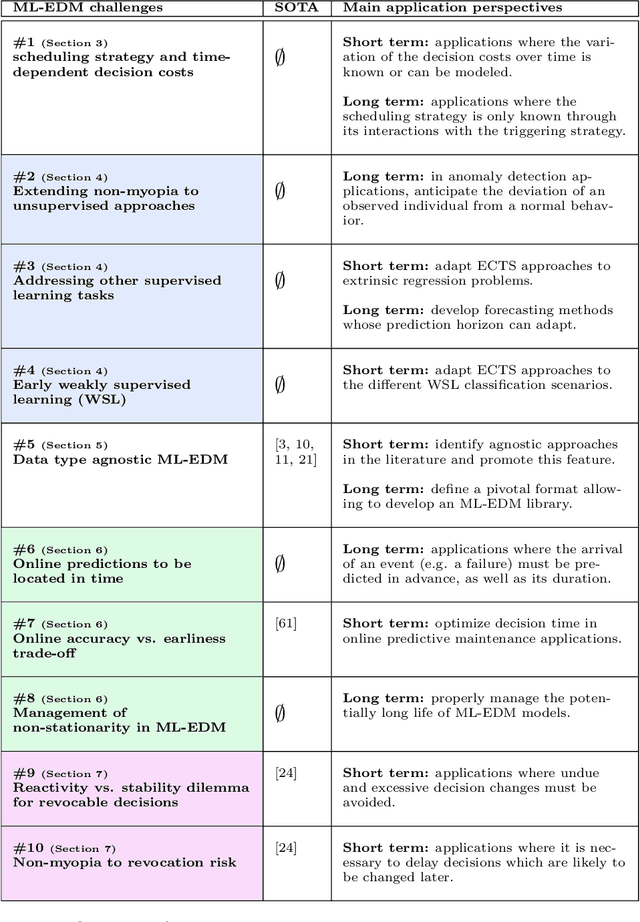
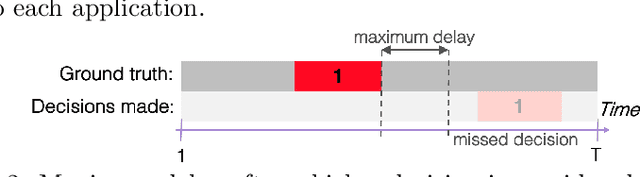
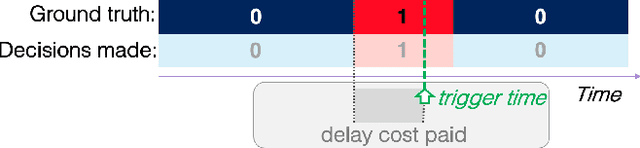
More and more applications require early decisions, i.e. taken as soon as possible from partially observed data. However, the later a decision is made, the more its accuracy tends to improve, since the description of the problem to hand is enriched over time. Such a compromise between the earliness and the accuracy of decisions has been particularly studied in the field of Early Time Series Classification. This paper introduces a more general problem, called Machine Learning based Early Decision Making (ML-EDM), which consists in optimizing the decision times of models in a wide range of settings where data is collected over time. After defining the ML-EDM problem, ten challenges are identified and proposed to the scientific community to further research in this area. These challenges open important application perspectives, discussed in this paper.
Un modèle Bayésien de co-clustering de données mixtes
Feb 06, 2019
We propose a MAP Bayesian approach to perform and evaluate a co-clustering of mixed-type data tables. The proposed model infers an optimal segmentation of all variables then performs a co-clustering by minimizing a Bayesian model selection cost function. One advantage of this approach is that it is user parameter-free. Another main advantage is the proposed criterion which gives an exact measure of the model quality, measured by probability of fitting it to the data. Continuous optimization of this criterion ensures finding better and better models while avoiding data over-fitting. The experiments conducted on real data show the interest of this co-clustering approach in exploratory data analysis of large data sets.
* in French
Random Forest for the Contextual Bandit Problem - extended version
Sep 15, 2016
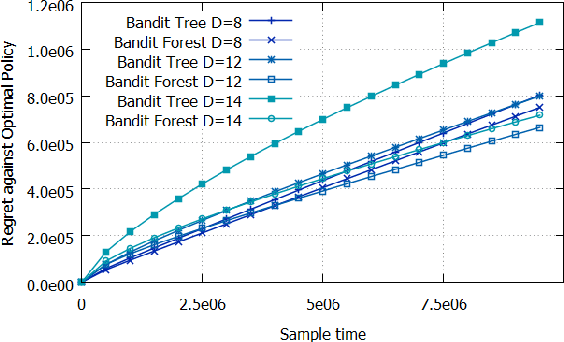
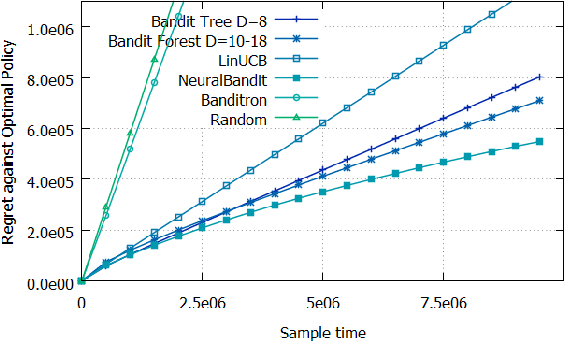

To address the contextual bandit problem, we propose an online random forest algorithm. The analysis of the proposed algorithm is based on the sample complexity needed to find the optimal decision stump. Then, the decision stumps are assembled in a random collection of decision trees, Bandit Forest. We show that the proposed algorithm is optimal up to logarithmic factors. The dependence of the sample complexity upon the number of contextual variables is logarithmic. The computational cost of the proposed algorithm with respect to the time horizon is linear. These analytical results allow the proposed algorithm to be efficient in real applications, where the number of events to process is huge, and where we expect that some contextual variables, chosen from a large set, have potentially non- linear dependencies with the rewards. In the experiments done to illustrate the theoretical analysis, Bandit Forest obtain promising results in comparison with state-of-the-art algorithms.
A Relative Exponential Weighing Algorithm for Adversarial Utility-based Dueling Bandits
Jan 15, 2016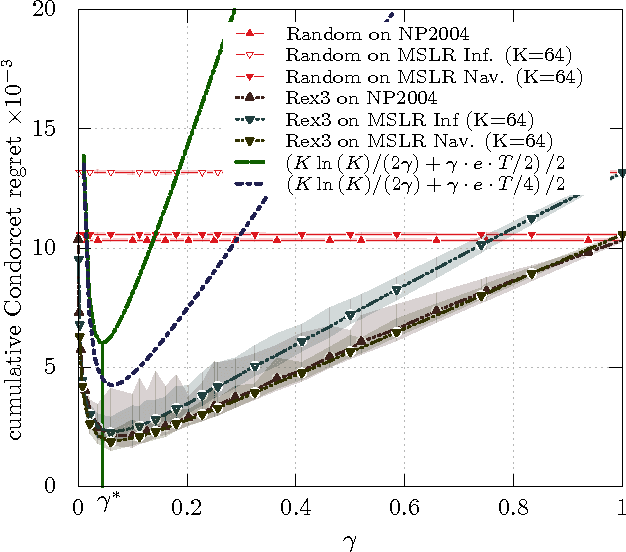

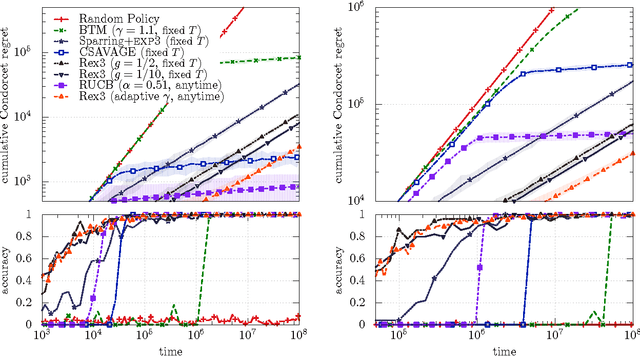
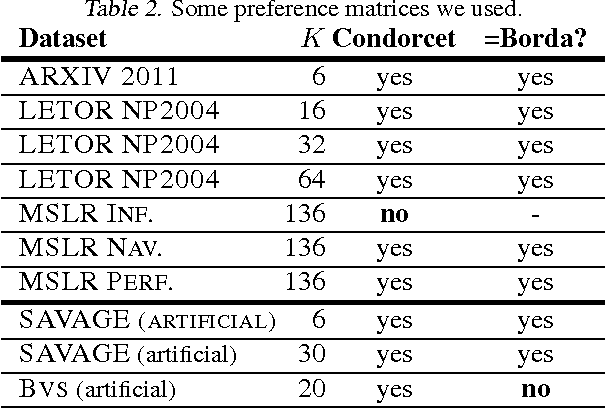
We study the K-armed dueling bandit problem which is a variation of the classical Multi-Armed Bandit (MAB) problem in which the learner receives only relative feedback about the selected pairs of arms. We propose a new algorithm called Relative Exponential-weight algorithm for Exploration and Exploitation (REX3) to handle the adversarial utility-based formulation of this problem. This algorithm is a non-trivial extension of the Exponential-weight algorithm for Exploration and Exploitation (EXP3) algorithm. We prove a finite time expected regret upper bound of order O(sqrt(K ln(K)T)) for this algorithm and a general lower bound of order omega(sqrt(KT)). At the end, we provide experimental results using real data from information retrieval applications.
Cats & Co: Categorical Time Series Coclustering
May 06, 2015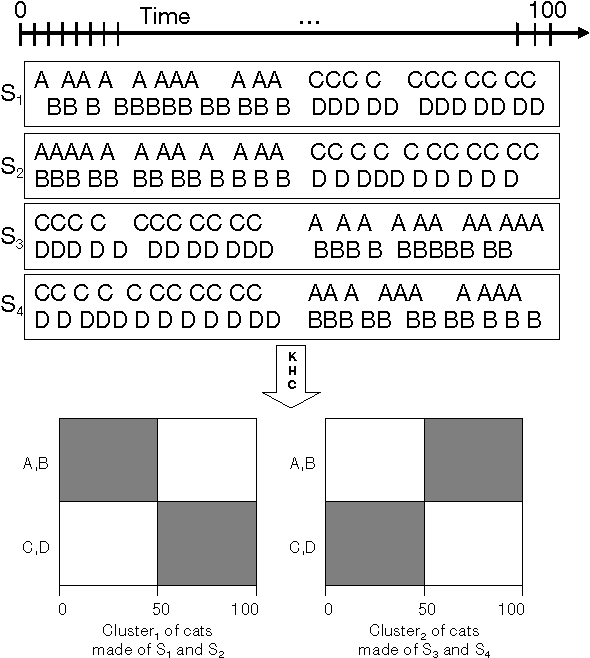

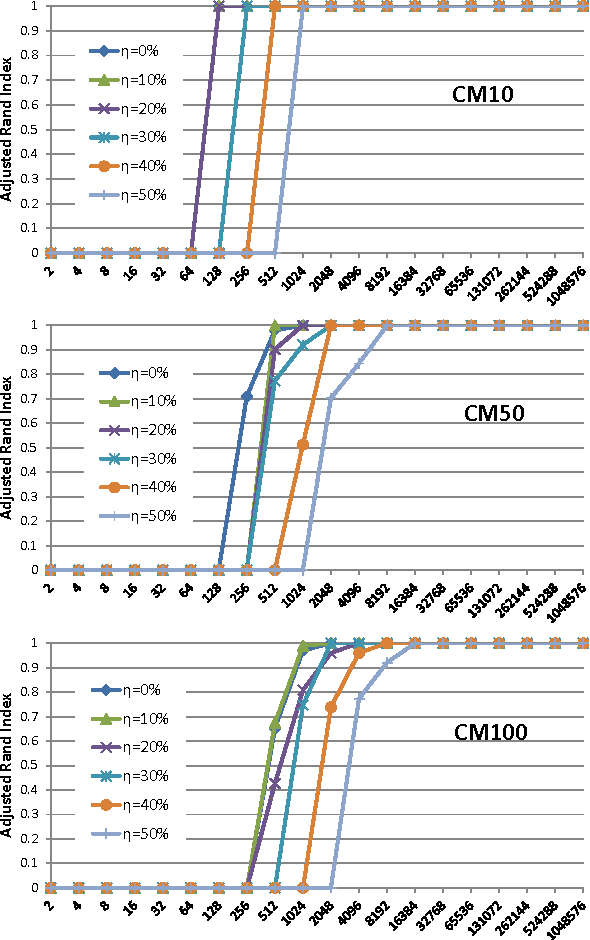
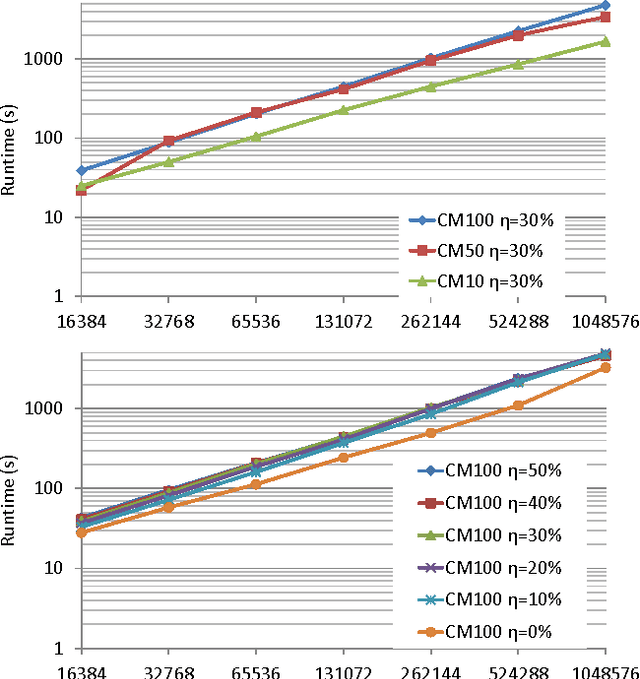
We suggest a novel method of clustering and exploratory analysis of temporal event sequences data (also known as categorical time series) based on three-dimensional data grid models. A data set of temporal event sequences can be represented as a data set of three-dimensional points, each point is defined by three variables: a sequence identifier, a time value and an event value. Instantiating data grid models to the 3D-points turns the problem into 3D-coclustering. The sequences are partitioned into clusters, the time variable is discretized into intervals and the events are partitioned into clusters. The cross-product of the univariate partitions forms a multivariate partition of the representation space, i.e., a grid of cells and it also represents a nonparametric estimator of the joint distribution of the sequences, time and events dimensions. Thus, the sequences are grouped together because they have similar joint distribution of time and events, i.e., similar distribution of events along the time dimension. The best data grid is computed using a parameter-free Bayesian model selection approach. We also suggest several criteria for exploiting the resulting grid through agglomerative hierarchies, for interpreting the clusters of sequences and characterizing their components through insightful visualizations. Extensive experiments on both synthetic and real-world data sets demonstrate that data grid models are efficient, effective and discover meaningful underlying patterns of categorical time series data.
Country-scale Exploratory Analysis of Call Detail Records through the Lens of Data Grid Models
Mar 20, 2015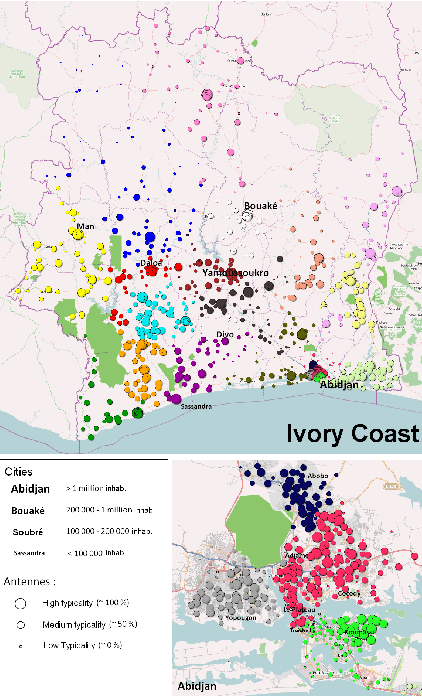
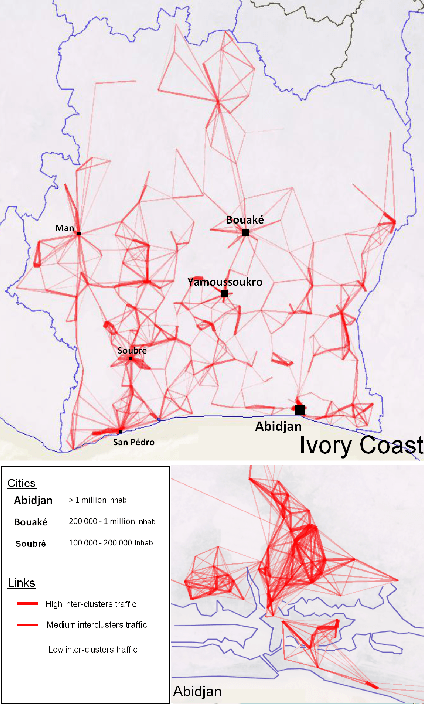
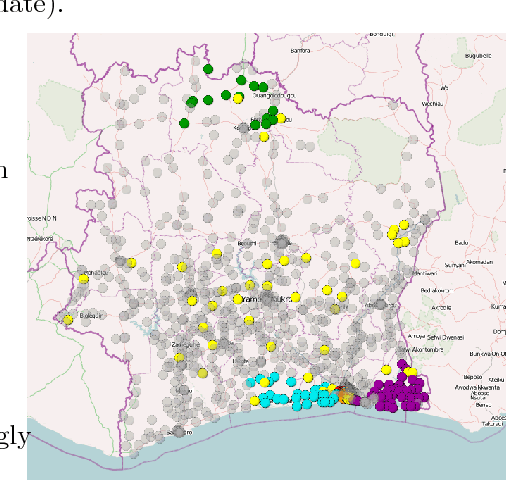
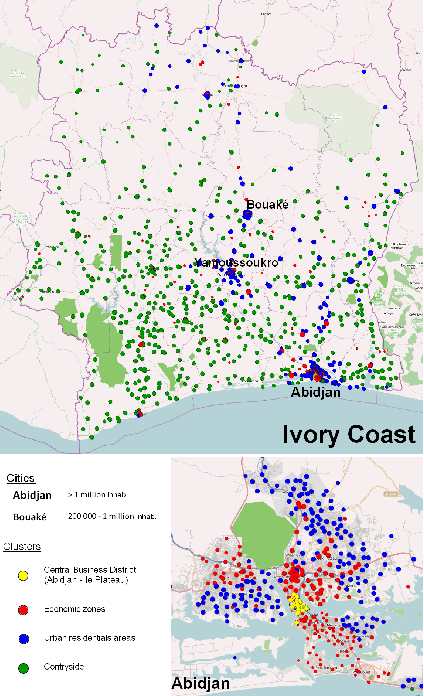
Call Detail Records (CDRs) are data recorded by telecommunications companies, consisting of basic informations related to several dimensions of the calls made through the network: the source, destination, date and time of calls. CDRs data analysis has received much attention in the recent years since it might reveal valuable information about human behavior. It has shown high added value in many application domains like e.g., communities analysis or network planning. In this paper, we suggest a generic methodology for summarizing information contained in CDRs data. The method is based on a parameter-free estimation of the joint distribution of the variables that describe the calls. We also suggest several well-founded criteria that allows one to browse the summary at various granularities and to explore the summary by means of insightful visualizations. The method handles network graph data, temporal sequence data as well as user mobility data stemming from original CDRs data. We show the relevance of our methodology for various case studies on real-world CDRs data from Ivory Coast.