 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeml_edm package: a Python toolkit for Machine Learning based Early Decision Making
Aug 23, 2024
\texttt{ml\_edm} is a Python 3 library, designed for early decision making of any learning tasks involving temporal/sequential data. The package is also modular, providing researchers an easy way to implement their own triggering strategy for classification, regression or any machine learning task. As of now, many Early Classification of Time Series (ECTS) state-of-the-art algorithms, are efficiently implemented in the library leveraging parallel computation. The syntax follows the one introduce in \texttt{scikit-learn}, making estimators and pipelines compatible with \texttt{ml\_edm}. This software is distributed over the BSD-3-Clause license, source code can be found at \url{https://github.com/ML-EDM/ml_edm}.
SANGEA: Scalable and Attributed Network Generation
Sep 27, 2023



The topic of synthetic graph generators (SGGs) has recently received much attention due to the wave of the latest breakthroughs in generative modelling. However, many state-of-the-art SGGs do not scale well with the graph size. Indeed, in the generation process, all the possible edges for a fixed number of nodes must often be considered, which scales in $\mathcal{O}(N^2)$, with $N$ being the number of nodes in the graph. For this reason, many state-of-the-art SGGs are not applicable to large graphs. In this paper, we present SANGEA, a sizeable synthetic graph generation framework which extends the applicability of any SGG to large graphs. By first splitting the large graph into communities, SANGEA trains one SGG per community, then links the community graphs back together to create a synthetic large graph. Our experiments show that the graphs generated by SANGEA have high similarity to the original graph, in terms of both topology and node feature distribution. Additionally, these generated graphs achieve high utility on downstream tasks such as link prediction. Finally, we provide a privacy assessment of the generated graphs to show that, even though they have excellent utility, they also achieve reasonable privacy scores.
Open challenges for Machine Learning based Early Decision-Making research
Apr 27, 2022
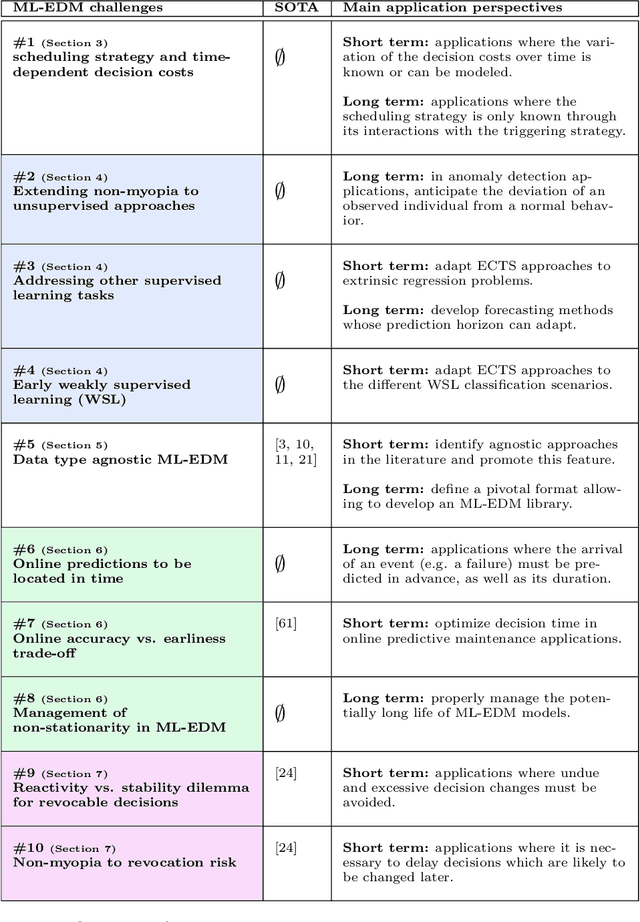
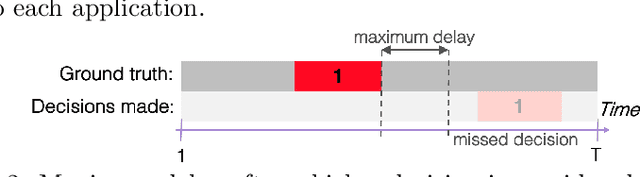
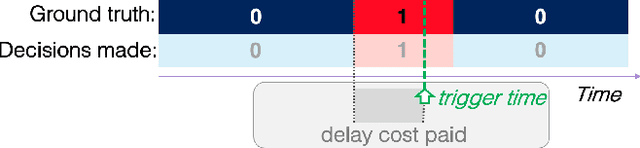
More and more applications require early decisions, i.e. taken as soon as possible from partially observed data. However, the later a decision is made, the more its accuracy tends to improve, since the description of the problem to hand is enriched over time. Such a compromise between the earliness and the accuracy of decisions has been particularly studied in the field of Early Time Series Classification. This paper introduces a more general problem, called Machine Learning based Early Decision Making (ML-EDM), which consists in optimizing the decision times of models in a wide range of settings where data is collected over time. After defining the ML-EDM problem, ten challenges are identified and proposed to the scientific community to further research in this area. These challenges open important application perspectives, discussed in this paper.
ECOTS: Early Classification in Open Time Series
Apr 01, 2022

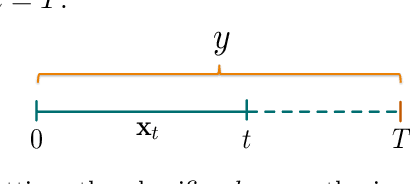

Learning to predict ahead of time events in open time series is challenging. While Early Classification of Time Series (ECTS) tackles the problem of balancing online the accuracy of the prediction with the cost of delaying the decision when the individuals are time series of finite length with a unique label for the whole time series. Surprisingly, this trade-off has never been investigated for open time series with undetermined length and with different classes for each subsequence of the same time series. In this paper, we propose a principled method to adapt any technique for ECTS to the Early Classification in Open Time Series (ECOTS). We show how the classifiers must be constructed and what the decision triggering system becomes in this new scenario. We address the challenge of decision making in the predictive maintenance field. We illustrate our methodology by transforming two state-of-the-art ECTS algorithms for the ECOTS scenario and report numerical experiments on a real dataset for predictive maintenance that demonstrate the practicality of the novel approach.
Early and Revocable Time Series Classification
Sep 22, 2021
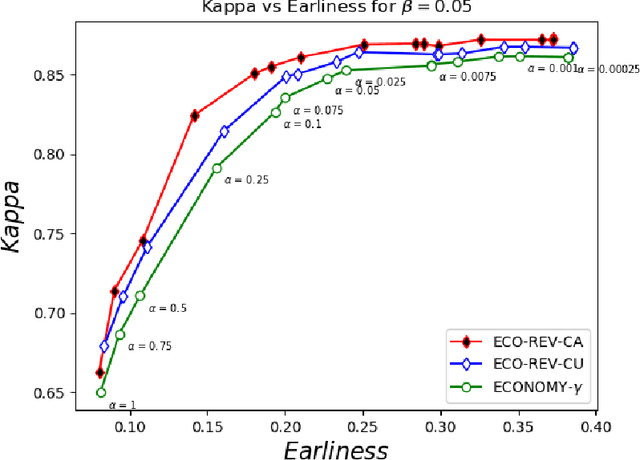
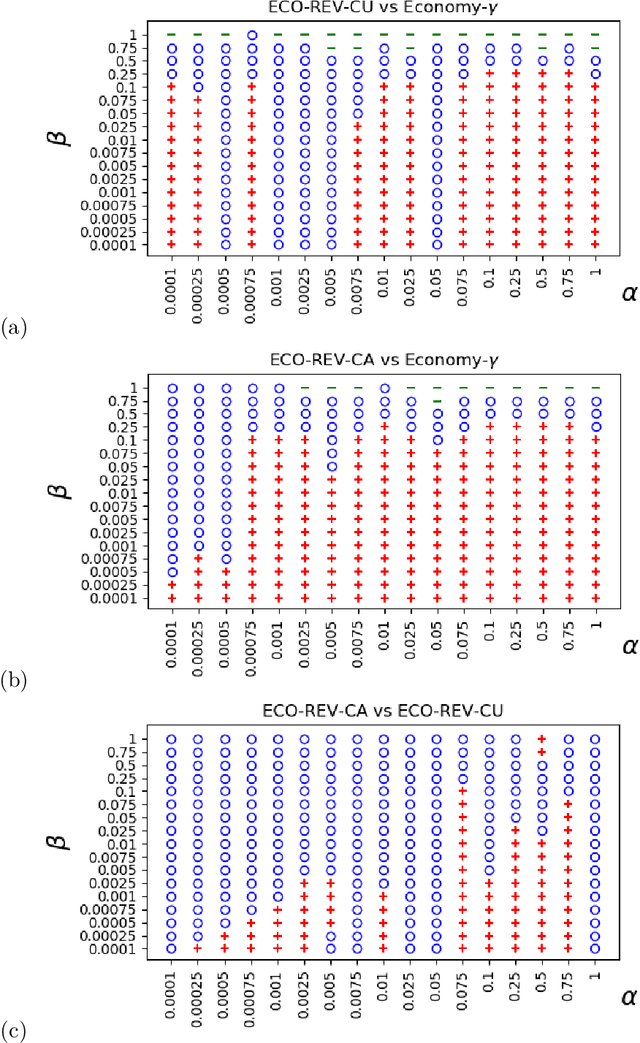
Many approaches have been proposed for early classification of time series in light of itssignificance in a wide range of applications including healthcare, transportation and fi-nance. Until now, the early classification problem has been dealt with by considering onlyirrevocable decisions. This paper introduces a new problem calledearly and revocabletimeseries classification, where the decision maker can revoke its earlier decisions based on thenew available measurements. In order to formalize and tackle this problem, we propose anew cost-based framework and derive two new approaches from it. The first approach doesnot consider explicitly the cost of changing decision, while the second one does. Exten-sive experiments are conducted to evaluate these approaches on a large benchmark of realdatasets. The empirical results obtained convincingly show (i) that the ability of revok-ing decisions significantly improves performance over the irrevocable regime, and (ii) thattaking into account the cost of changing decision brings even better results in general.Keywords:revocable decisions, cost estimation, online decision making
Early Classification of Time Series is Meaningful
Apr 30, 2021Many approaches have been proposed for early classification of time series in light of its significance in a wide range of applications including healthcare, transportation and finance. However, recently a preprint saved on Arxiv claim that all research done for almost 20 years now on the Early Classification of Time Series is useless, or, at the very least, ill-oriented because severely lacking a strong ground. In this paper, we answer in detail the main issues and misunderstandings raised by the authors of the preprint, and propose directions to further expand the fields of application of early classification of time series.
Early Classification of Time Series. Cost-based Optimization Criterion and Algorithms
May 20, 2020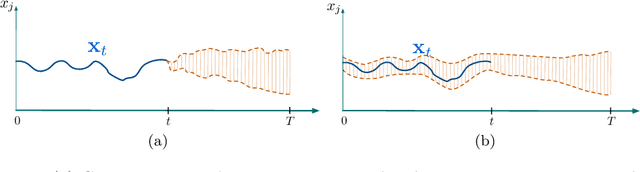
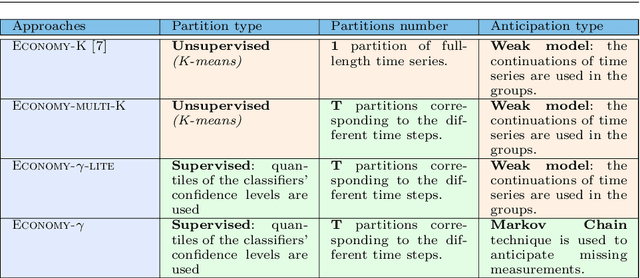
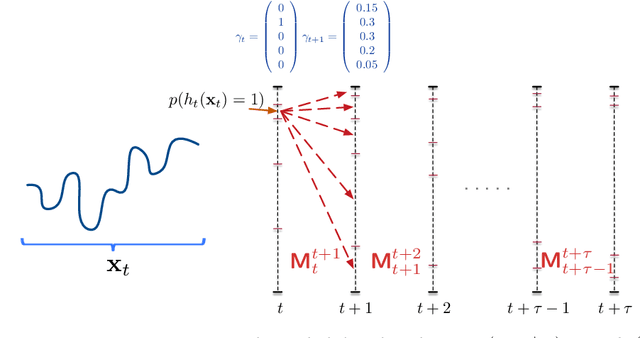
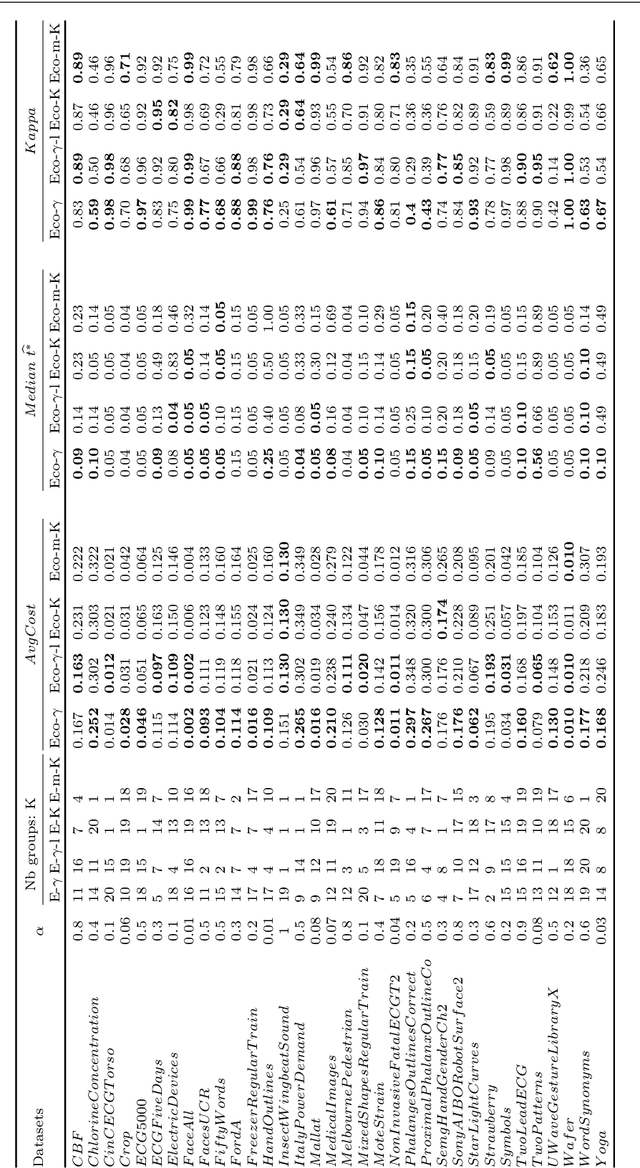
An increasing number of applications require to recognize the class of an incoming time series as quickly as possible without unduly compromising the accuracy of the prediction. In this paper, we put forward a new optimization criterion which takes into account both the cost of misclassification and the cost of delaying the decision. Based on this optimization criterion, we derived a family of non-myopic algorithms which try to anticipate the expected future gain in information in balance with the cost of waiting. In one class of algorithms, unsupervised-based, the expectations use the clustering of time series, while in a second class, supervised-based, time series are grouped according to the confidence level of the classifier used to label them. Extensive experiments carried out on real data sets using a large range of delay cost functions show that the presented algorithms are able to satisfactorily solving the earliness vs. accuracy trade-off, with the supervised-based approaches faring better than the unsupervised-based ones. In addition, all these methods perform better in a wide variety of conditions than a state of the art method based on a myopic strategy which is recognized as very competitive.