 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-Driven Railway Delay Prediction: An Imitation Learning Approach
Dec 17, 2025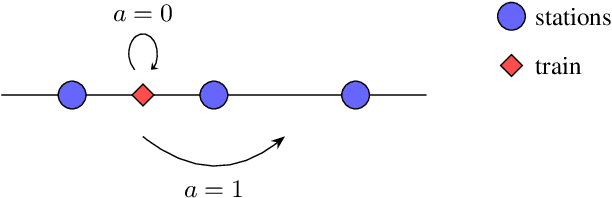
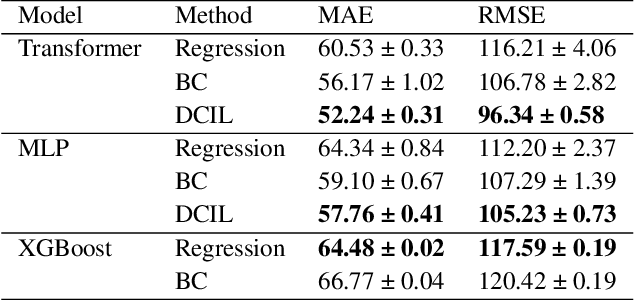
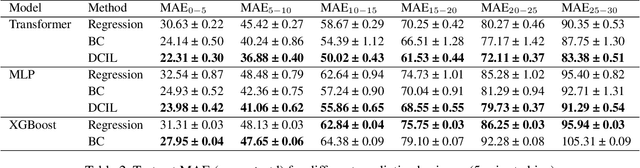
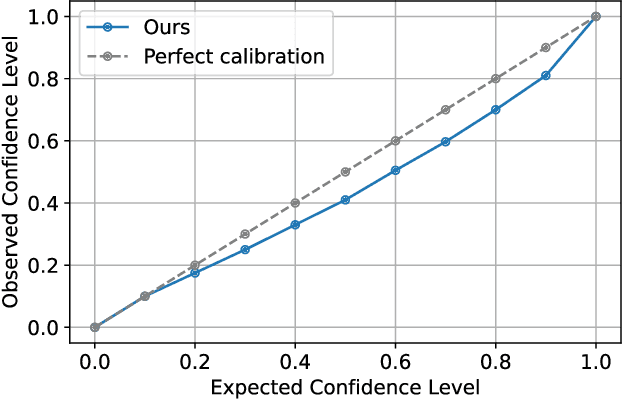
Reliable prediction of train delays is essential for enhancing the robustness and efficiency of railway transportation systems. In this work, we reframe delay forecasting as a stochastic simulation task, modeling state-transition dynamics through imitation learning. We introduce Drift-Corrected Imitation Learning (DCIL), a novel self-supervised algorithm that extends DAgger by incorporating distance-based drift correction, thereby mitigating covariate shift during rollouts without requiring access to an external oracle or adversarial schemes. Our approach synthesizes the dynamical fidelity of event-driven models with the representational capacity of data-driven methods, enabling uncertainty-aware forecasting via Monte Carlo simulation. We evaluate DCIL using a comprehensive real-world dataset from \textsc{Infrabel}, the Belgian railway infrastructure manager, which encompasses over three million train movements. Our results, focused on predictions up to 30 minutes ahead, demonstrate superior predictive performance of DCIL over traditional regression models and behavioral cloning on deep learning architectures, highlighting its effectiveness in capturing the sequential and uncertain nature of delay propagation in large-scale networks.
Binary Split Categorical feature with Mean Absolute Error Criteria in CART
Nov 11, 2025


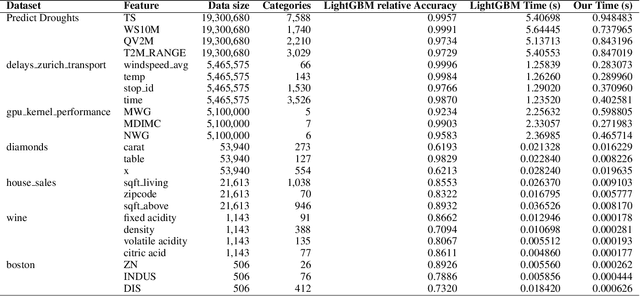
In the context of the Classification and Regression Trees (CART) algorithm, the efficient splitting of categorical features using standard criteria like GINI and Entropy is well-established. However, using the Mean Absolute Error (MAE) criterion for categorical features has traditionally relied on various numerical encoding methods. This paper demonstrates that unsupervised numerical encoding methods are not viable for the MAE criteria. Furthermore, we present a novel and efficient splitting algorithm that addresses the challenges of handling categorical features with the MAE criterion. Our findings underscore the limitations of existing approaches and offer a promising solution to enhance the handling of categorical data in CART algorithms.
Online Isolation Forest
May 14, 2025The anomaly detection literature is abundant with offline methods, which require repeated access to data in memory, and impose impractical assumptions when applied to a streaming context. Existing online anomaly detection methods also generally fail to address these constraints, resorting to periodic retraining to adapt to the online context. We propose Online-iForest, a novel method explicitly designed for streaming conditions that seamlessly tracks the data generating process as it evolves over time. Experimental validation on real-world datasets demonstrated that Online-iForest is on par with online alternatives and closely rivals state-of-the-art offline anomaly detection techniques that undergo periodic retraining. Notably, Online-iForest consistently outperforms all competitors in terms of efficiency, making it a promising solution in applications where fast identification of anomalies is of primary importance such as cybersecurity, fraud and fault detection.
Evaluation for Regression Analyses on Evolving Data Streams
Feb 11, 2025



The paper explores the challenges of regression analysis in evolving data streams, an area that remains relatively underexplored compared to classification. We propose a standardized evaluation process for regression and prediction interval tasks in streaming contexts. Additionally, we introduce an innovative drift simulation strategy capable of synthesizing various drift types, including the less-studied incremental drift. Comprehensive experiments with state-of-the-art methods, conducted under the proposed process, validate the effectiveness and robustness of our approach.
CapyMOA: Efficient Machine Learning for Data Streams in Python
Feb 11, 2025CapyMOA is an open-source library designed for efficient machine learning on streaming data. It provides a structured framework for real-time learning and evaluation, featuring a flexible data representation. CapyMOA includes an extensible architecture that allows integration with external frameworks such as MOA and PyTorch, facilitating hybrid learning approaches that combine traditional online algorithms with deep learning techniques. By emphasizing adaptability, scalability, and usability, CapyMOA allows researchers and practitioners to tackle dynamic learning challenges across various domains.
Optimizing Hyperparameters for Quantum Data Re-Uploaders in Calorimetric Particle Identification
Dec 16, 2024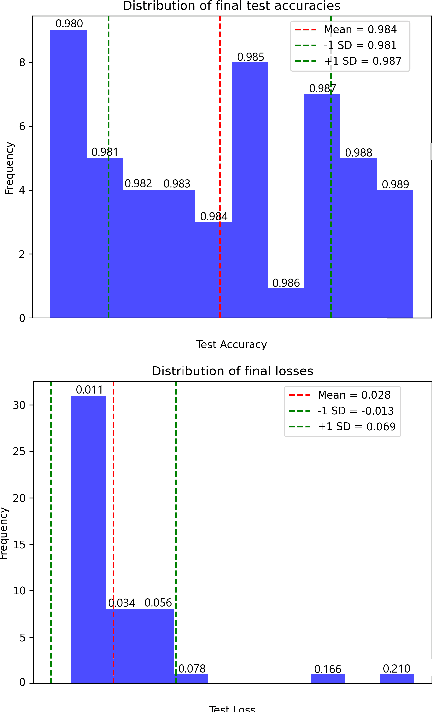

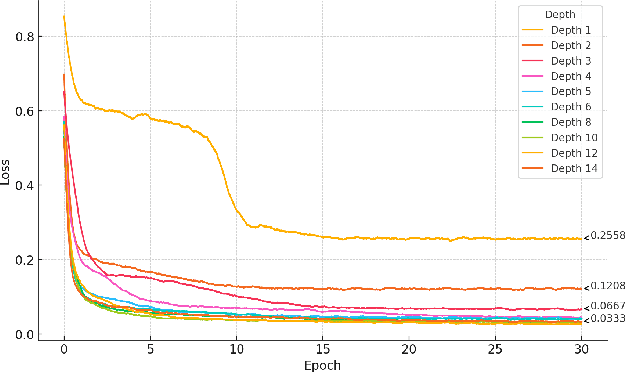

We present an application of a single-qubit Data Re-Uploading (QRU) quantum model for particle classification in calorimetric experiments. Optimized for Noisy Intermediate-Scale Quantum (NISQ) devices, this model requires minimal qubits while delivering strong classification performance. Evaluated on a novel simulated dataset specific to particle physics, the QRU model achieves high accuracy in classifying particle types. Through a systematic exploration of model hyperparameters -- such as circuit depth, rotation gates, input normalization and the number of trainable parameters per input -- and training parameters like batch size, optimizer, loss function and learning rate, we assess their individual impacts on model accuracy and efficiency. Additionally, we apply global optimization methods, uncovering hyperparameter correlations that further enhance performance. Our results indicate that the QRU model attains significant accuracy with efficient computational costs, underscoring its potential for practical quantum machine learning applications.
Real-Time Energy Pricing in New Zealand: An Evolving Stream Analysis
Aug 29, 2024
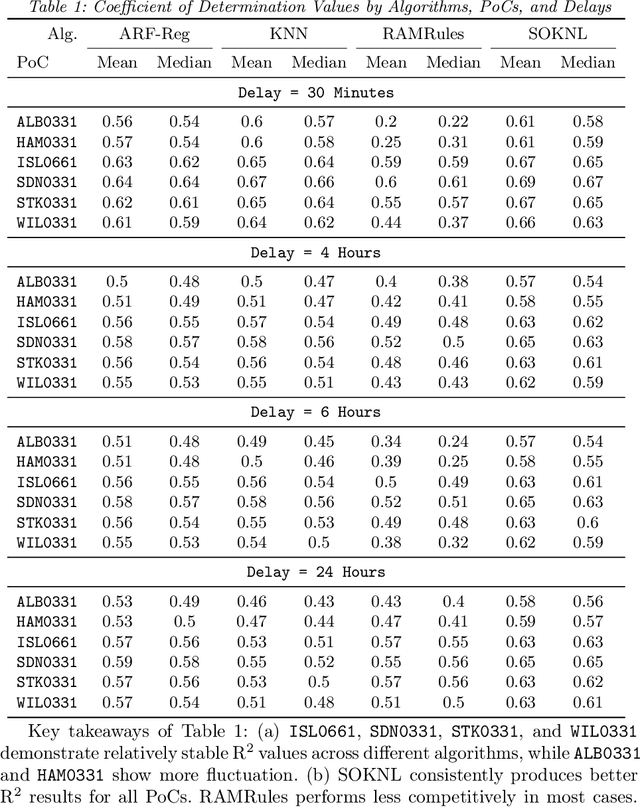
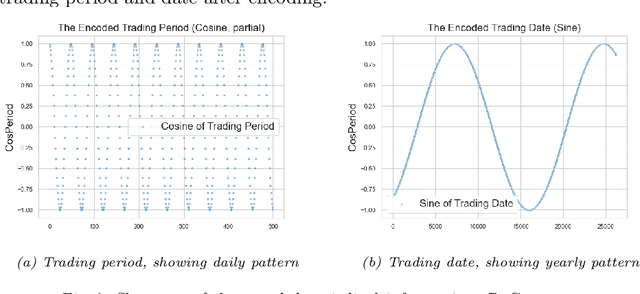
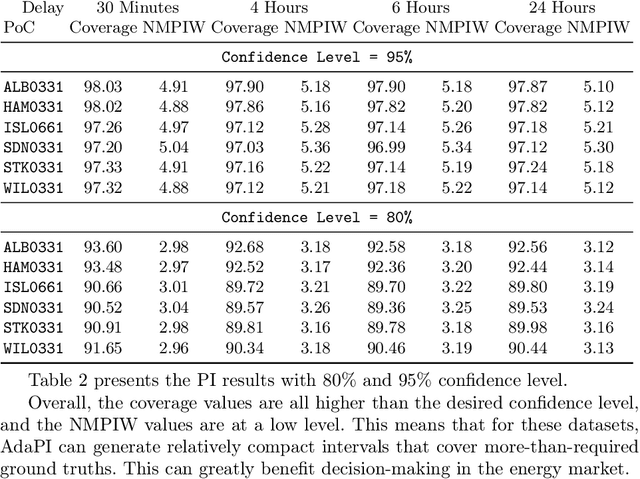
This paper introduces a group of novel datasets representing real-time time-series and streaming data of energy prices in New Zealand, sourced from the Electricity Market Information (EMI) website maintained by the New Zealand government. The datasets are intended to address the scarcity of proper datasets for streaming regression learning tasks. We conduct extensive analyses and experiments on these datasets, covering preprocessing techniques, regression tasks, prediction intervals, concept drift detection, and anomaly detection. Our experiments demonstrate the datasets' utility and highlight the challenges and opportunities for future research in energy price forecasting.
A Probabilistic Framework for Adapting to Changing and Recurring Concepts in Data Streams
Aug 18, 2024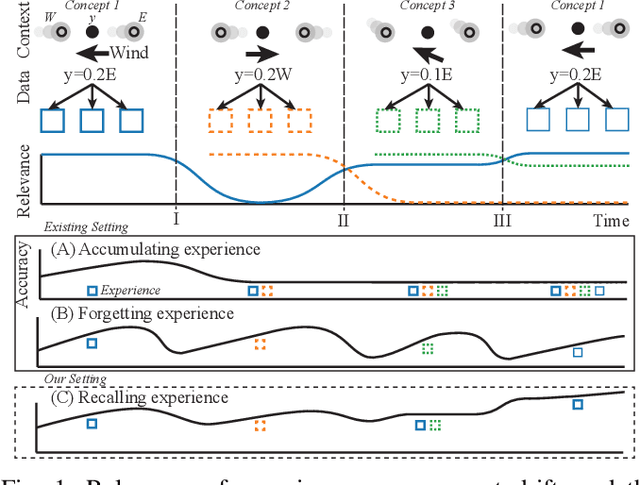
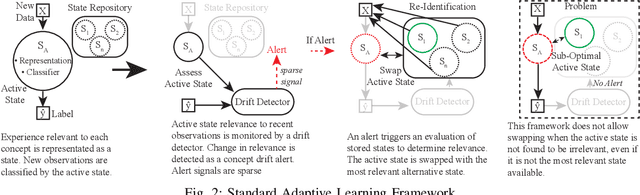
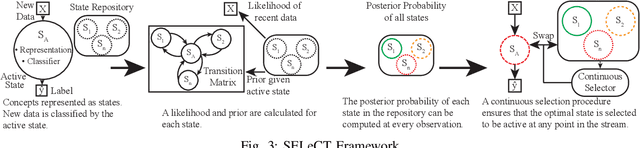
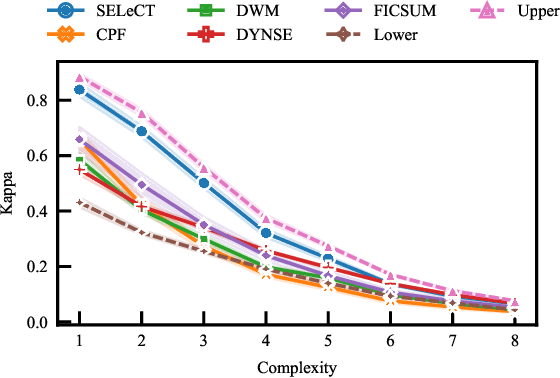
The distribution of streaming data often changes over time as conditions change, a phenomenon known as concept drift. Only a subset of previous experience, collected in similar conditions, is relevant to learning an accurate classifier for current data. Learning from irrelevant experience describing a different concept can degrade performance. A system learning from streaming data must identify which recent experience is irrelevant when conditions change and which past experience is relevant when concepts reoccur, \textit{e.g.,} when weather events or financial patterns repeat. Existing streaming approaches either do not consider experience to change in relevance over time and thus cannot handle concept drift, or only consider the recency of experience and thus cannot handle recurring concepts, or only sparsely evaluate relevance and thus fail when concept drift is missed. To enable learning in changing conditions, we propose SELeCT, a probabilistic method for continuously evaluating the relevance of past experience. SELeCT maintains a distinct internal state for each concept, representing relevant experience with a unique classifier. We propose a Bayesian algorithm for estimating state relevance, combining the likelihood of drawing recent observations from a given state with a transition pattern prior based on the system's current state.
Branches: A Fast Dynamic Programming and Branch & Bound Algorithm for Optimal Decision Trees
Jun 04, 2024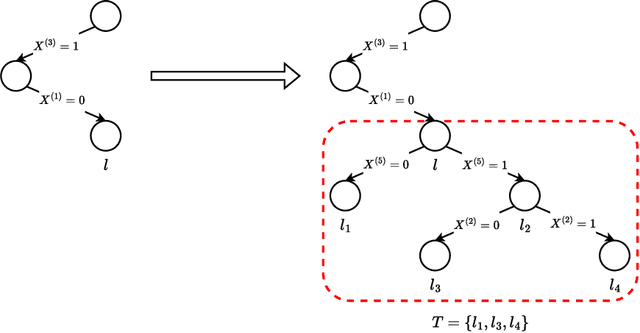
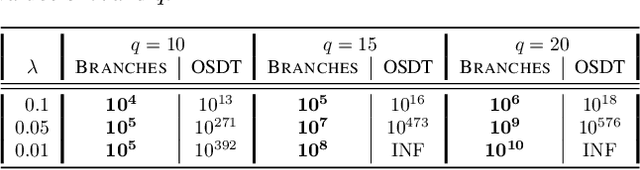
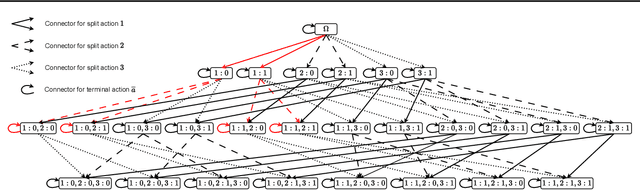
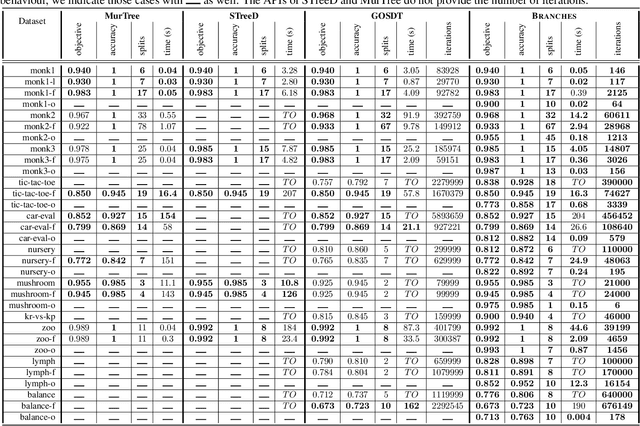
Decision Tree Learning is a fundamental problem for Interpretable Machine Learning, yet it poses a formidable optimization challenge. Despite numerous efforts dating back to the early 1990's, practical algorithms have only recently emerged, primarily leveraging Dynamic Programming (DP) and Branch & Bound (B&B) techniques. These breakthroughs led to the development of two distinct approaches. Algorithms like DL8.5 and MurTree operate on the space of nodes (or branches), they are very fast, but do not penalise complex Decision Trees, i.e. they do not solve for sparsity. On the other hand, algorithms like OSDT and GOSDT operate on the space of Decision Trees, they solve for sparsity but at the detriment of speed. In this work, we introduce Branches, a novel algorithm that integrates the strengths of both paradigms. Leveraging DP and B&B, Branches achieves exceptional speed while also solving for sparsity. Central to its efficiency is a novel analytical bound enabling substantial pruning of the search space. Theoretical analysis demonstrates that Branches has lower complexity compared to state-of-the-art methods, a claim validated through extensive empirical evaluation. Our results illustrate that Branches not only greatly outperforms existing approaches in terms of speed and number of iterations, it also consistently yields optimal Decision Trees.
A Retrospective of the Tutorial on Opportunities and Challenges of Online Deep Learning
May 28, 2024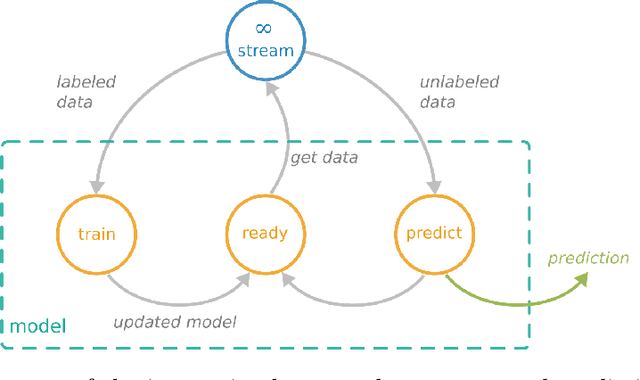
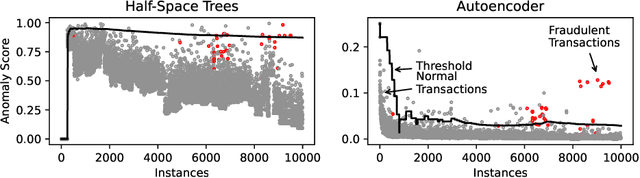
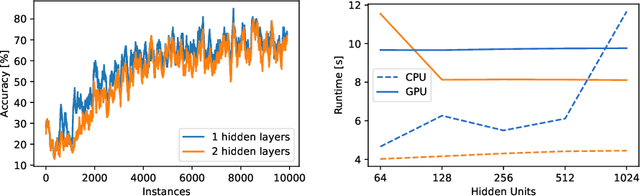
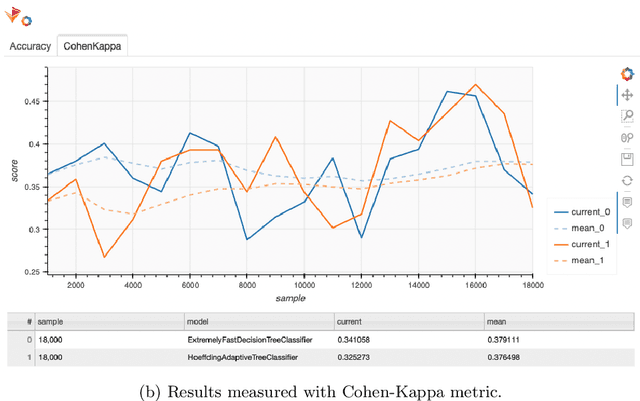
Machine learning algorithms have become indispensable in today's world. They support and accelerate the way we make decisions based on the data at hand. This acceleration means that data structures that were valid at one moment could no longer be valid in the future. With these changing data structures, it is necessary to adapt machine learning (ML) systems incrementally to the new data. This is done with the use of online learning or continuous ML technologies. While deep learning technologies have shown exceptional performance on predefined datasets, they have not been widely applied to online, streaming, and continuous learning. In this retrospective of our tutorial titled Opportunities and Challenges of Online Deep Learning held at ECML PKDD 2023, we provide a brief overview of the opportunities but also the potential pitfalls for the application of neural networks in online learning environments using the frameworks River and Deep-River.