 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Evaluating and Benchmarking Concept Drift Detection Methods
Jun 05, 2026Data stream mining is fundamentally challenged by concept drift, where distributional changes can degrade model performance. Despite the proliferation of drift detection methods, progress in the field is hindered by inconsistent evaluation practices: studies rely on oversimplified synthetic data generators, adopt incompatible metrics, and lack transparency in hyperparameter selection, making fair comparisons difficult. We address this gap with a novel benchmarking framework comprising three contributions: (1) a drift simulation method that injects controlled distributional changes into real-world datasets via Monte Carlo trials, enabling supervised evaluation while preserving real-world data complexity; (2) an evaluation protocol for drift detection with timing-aware criteria, including the derivation of new metrics (e.g., F1 detection score, normalized detection time) that are comparable across streams; and (3) we advocate for a leave-one-dataset-out hyperparameter optimization protocol for drift detection methods that promotes configuration robustness across heterogeneous stream dynamics. We benchmark 14 widely used drift detection methods on 7 realworld datasets across 4 drift types (class prior, label swap, feature permutation, feature filtering), each under both abrupt and gradual transitions. Our experimental results provide insights into the strengths and weaknesses of current drift detection approaches while establishing baseline performance metrics for future research in this area. All code and experiments are publicly available.
CapyMOA: Efficient Machine Learning for Data Streams in Python
Feb 11, 2025

CapyMOA is an open-source library designed for efficient machine learning on streaming data. It provides a structured framework for real-time learning and evaluation, featuring a flexible data representation. CapyMOA includes an extensible architecture that allows integration with external frameworks such as MOA and PyTorch, facilitating hybrid learning approaches that combine traditional online algorithms with deep learning techniques. By emphasizing adaptability, scalability, and usability, CapyMOA allows researchers and practitioners to tackle dynamic learning challenges across various domains.
Evaluation for Regression Analyses on Evolving Data Streams
Feb 11, 2025



The paper explores the challenges of regression analysis in evolving data streams, an area that remains relatively underexplored compared to classification. We propose a standardized evaluation process for regression and prediction interval tasks in streaming contexts. Additionally, we introduce an innovative drift simulation strategy capable of synthesizing various drift types, including the less-studied incremental drift. Comprehensive experiments with state-of-the-art methods, conducted under the proposed process, validate the effectiveness and robustness of our approach.
CLOFAI: A Dataset of Real And Fake Image Classification Tasks for Continual Learning
Jan 19, 2025The rapid advancement of generative AI models capable of creating realistic media has led to a need for classifiers that can accurately distinguish between genuine and artificially-generated images. A significant challenge for these classifiers emerges when they encounter images from generative models that are not represented in their training data, usually resulting in diminished performance. A typical approach is to periodically update the classifier's training data with images from the new generative models then retrain the classifier on the updated dataset. However, in some real-life scenarios, storage, computational, or privacy constraints render this approach impractical. Additionally, models used in security applications may be required to rapidly adapt. In these circumstances, continual learning provides a promising alternative, as the classifier can be updated without retraining on the entire dataset. In this paper, we introduce a new dataset called CLOFAI (Continual Learning On Fake and Authentic Images), which takes the form of a domain-incremental image classification problem. Moreover, we showcase the applicability of this dataset as a benchmark for evaluating continual learning methodologies. In doing this, we set a baseline on our novel dataset using three foundational continual learning methods -- EWC, GEM, and Experience Replay -- and find that EWC performs poorly, while GEM and Experience Replay show promise, performing significantly better than a Naive baseline. The dataset and code to run the experiments can be accessed from the following GitHub repository: https://github.com/Will-Doherty/CLOFAI.
Real-Time Energy Pricing in New Zealand: An Evolving Stream Analysis
Aug 29, 2024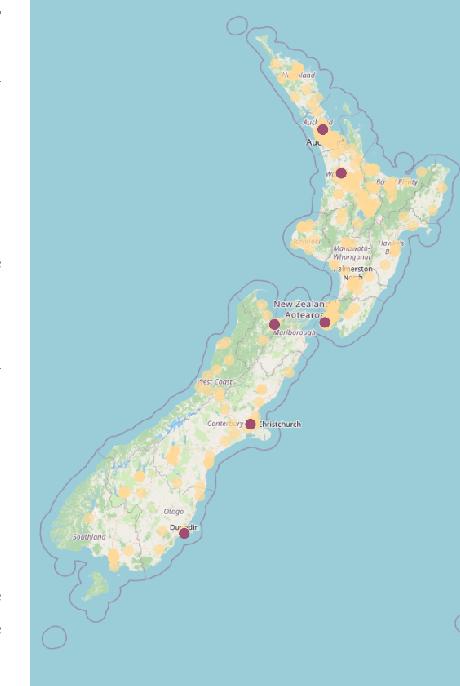
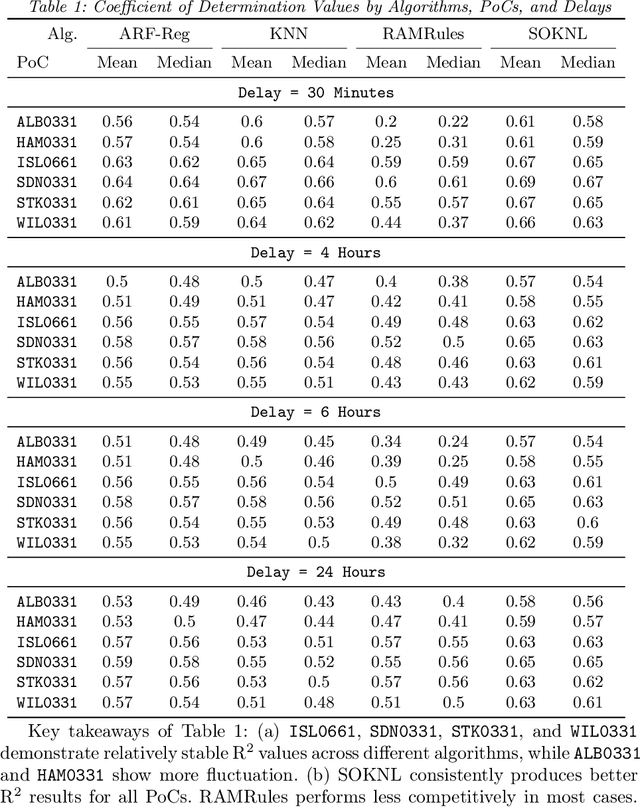
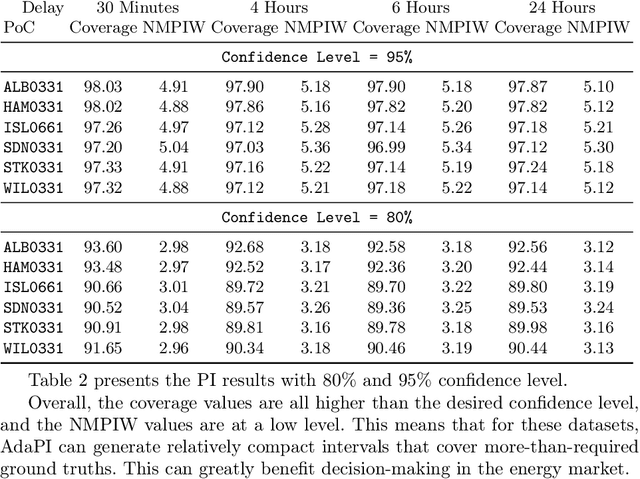
This paper introduces a group of novel datasets representing real-time time-series and streaming data of energy prices in New Zealand, sourced from the Electricity Market Information (EMI) website maintained by the New Zealand government. The datasets are intended to address the scarcity of proper datasets for streaming regression learning tasks. We conduct extensive analyses and experiments on these datasets, covering preprocessing techniques, regression tasks, prediction intervals, concept drift detection, and anomaly detection. Our experiments demonstrate the datasets' utility and highlight the challenges and opportunities for future research in energy price forecasting.
Look At Me, No Replay! SurpriseNet: Anomaly Detection Inspired Class Incremental Learning
Oct 30, 2023

Continual learning aims to create artificial neural networks capable of accumulating knowledge and skills through incremental training on a sequence of tasks. The main challenge of continual learning is catastrophic interference, wherein new knowledge overrides or interferes with past knowledge, leading to forgetting. An associated issue is the problem of learning "cross-task knowledge," where models fail to acquire and retain knowledge that helps differentiate classes across task boundaries. A common solution to both problems is "replay," where a limited buffer of past instances is utilized to learn cross-task knowledge and mitigate catastrophic interference. However, a notable drawback of these methods is their tendency to overfit the limited replay buffer. In contrast, our proposed solution, SurpriseNet, addresses catastrophic interference by employing a parameter isolation method and learning cross-task knowledge using an auto-encoder inspired by anomaly detection. SurpriseNet is applicable to both structured and unstructured data, as it does not rely on image-specific inductive biases. We have conducted empirical experiments demonstrating the strengths of SurpriseNet on various traditional vision continual-learning benchmarks, as well as on structured data datasets. Source code made available at https://doi.org/10.5281/zenodo.8247906 and https://github.com/tachyonicClock/SurpriseNet-CIKM-23
Advances on Concept Drift Detection in Regression Tasks using Social Networks Theory
Apr 19, 2023Mining data streams is one of the main studies in machine learning area due to its application in many knowledge areas. One of the major challenges on mining data streams is concept drift, which requires the learner to discard the current concept and adapt to a new one. Ensemble-based drift detection algorithms have been used successfully to the classification task but usually maintain a fixed size ensemble of learners running the risk of needlessly spending processing time and memory. In this paper we present improvements to the Scale-free Network Regressor (SFNR), a dynamic ensemble-based method for regression that employs social networks theory. In order to detect concept drifts SFNR uses the Adaptive Window (ADWIN) algorithm. Results show improvements in accuracy, especially in concept drift situations and better performance compared to other state-of-the-art algorithms in both real and synthetic data.
Fast & Furious: Modelling Malware Detection as Evolving Data Streams
May 24, 2022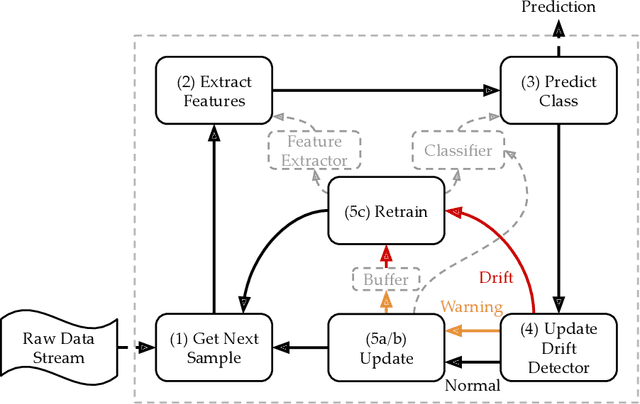
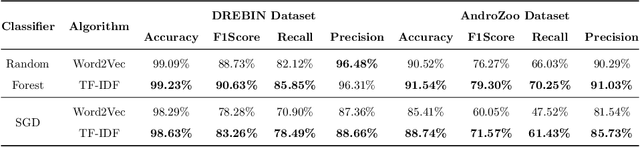
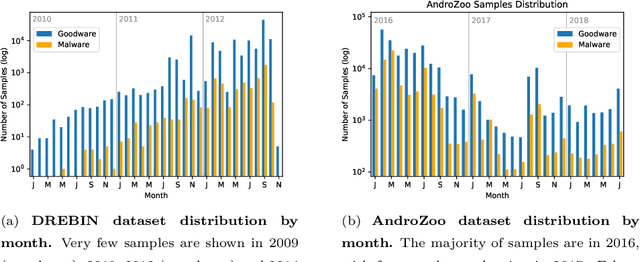
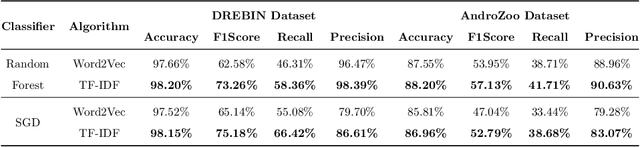
Malware is a major threat to computer systems and imposes many challenges to cyber security. Targeted threats, such as ransomware, cause millions of dollars in losses every year. The constant increase of malware infections has been motivating popular antiviruses (AVs) to develop dedicated detection strategies, which include meticulously crafted machine learning (ML) pipelines. However, malware developers unceasingly change their samples features to bypass detection. This constant evolution of malware samples causes changes to the data distribution (i.e., concept drifts) that directly affect ML model detection rates. In this work, we evaluate the impact of concept drift on malware classifiers for two Android datasets: DREBIN (~130K apps) and AndroZoo (~350K apps). Android is a ubiquitous operating system for smartphones, which stimulates attackers to regularly create and update malware to the platform. We conducted a longitudinal evaluation by (i) classifying malware samples collected over nine years (2009-2018), (ii) reviewing concept drift detection algorithms to attest its pervasiveness, (iii) comparing distinct ML approaches to mitigate the issue, and (iv) proposing an ML data stream pipeline that outperformed literature approaches. As a result, we observed that updating every component of the pipeline in response to concept drifts allows the classification model to achieve increasing detection rates as the data representation (extracted features) is updated. Furthermore, we discuss the impact of the changes on the classification models by comparing the variations in the extracted features.
A Survey on Semi-Supervised Learning for Delayed Partially Labelled Data Streams
Jun 16, 2021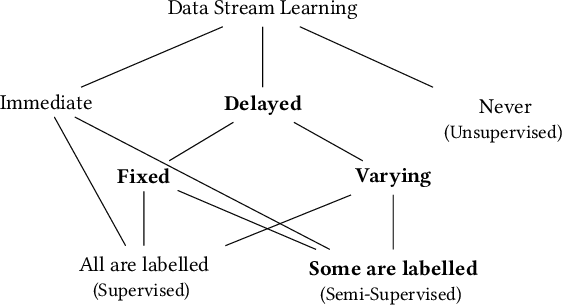
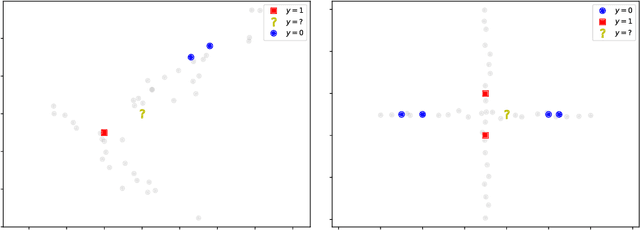
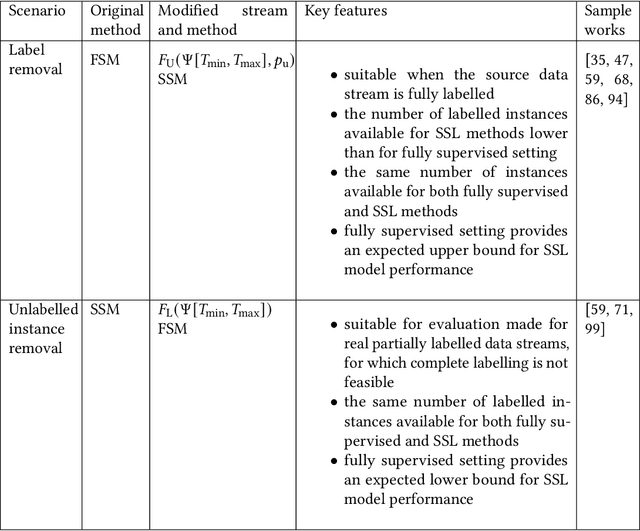
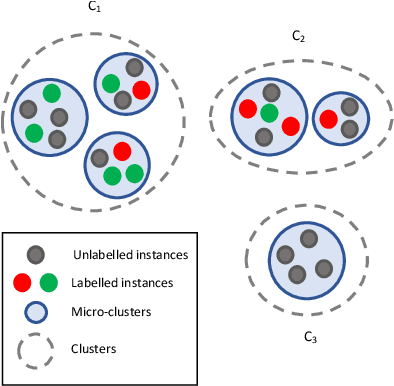
Unlabelled data appear in many domains and are particularly relevant to streaming applications, where even though data is abundant, labelled data is rare. To address the learning problems associated with such data, one can ignore the unlabelled data and focus only on the labelled data (supervised learning); use the labelled data and attempt to leverage the unlabelled data (semi-supervised learning); or assume some labels will be available on request (active learning). The first approach is the simplest, yet the amount of labelled data available will limit the predictive performance. The second relies on finding and exploiting the underlying characteristics of the data distribution. The third depends on an external agent to provide the required labels in a timely fashion. This survey pays special attention to methods that leverage unlabelled data in a semi-supervised setting. We also discuss the delayed labelling issue, which impacts both fully supervised and semi-supervised methods. We propose a unified problem setting, discuss the learning guarantees and existing methods, explain the differences between related problem settings. Finally, we review the current benchmarking practices and propose adaptations to enhance them.
STUDD: A Student-Teacher Method for Unsupervised Concept Drift Detection
Mar 01, 2021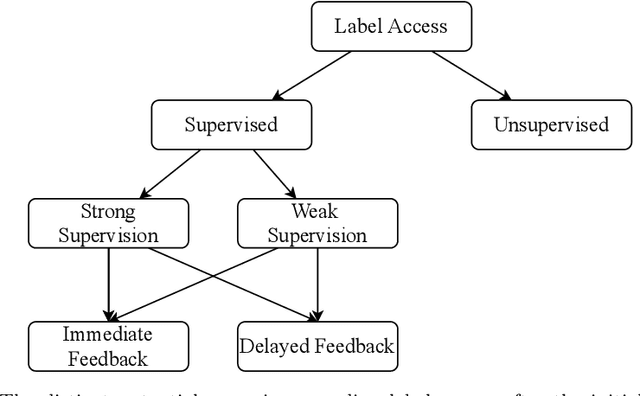
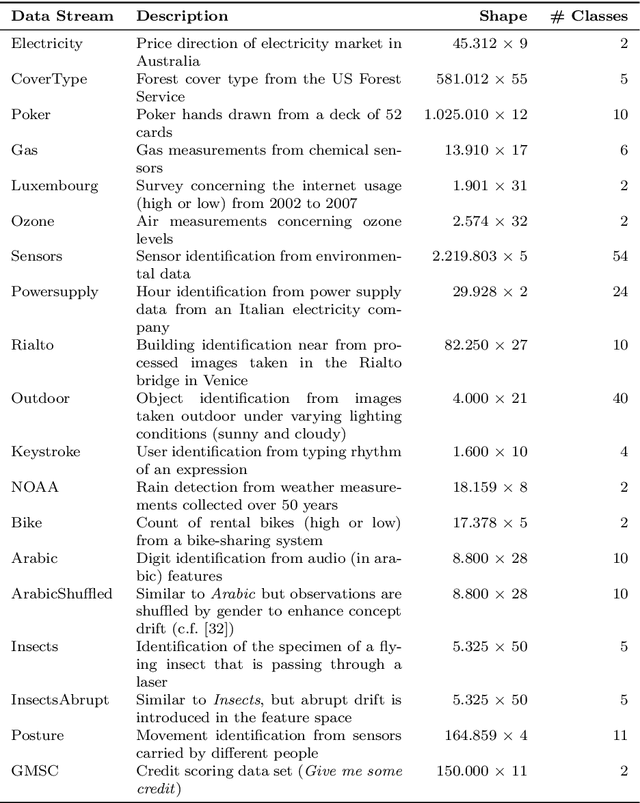

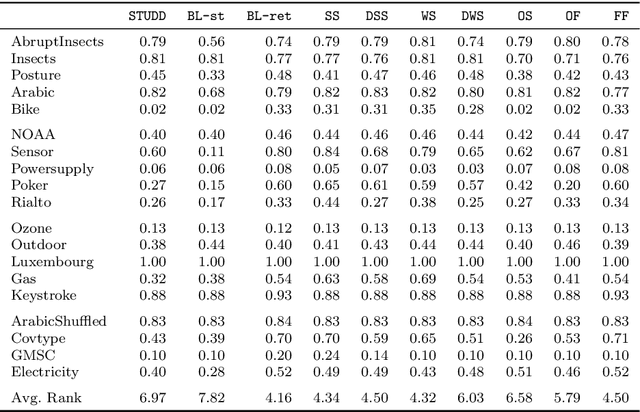
Concept drift detection is a crucial task in data stream evolving environments. Most of state of the art approaches designed to tackle this problem monitor the loss of predictive models. However, this approach falls short in many real-world scenarios, where the true labels are not readily available to compute the loss. In this context, there is increasing attention to approaches that perform concept drift detection in an unsupervised manner, i.e., without access to the true labels. We propose a novel approach to unsupervised concept drift detection based on a student-teacher learning paradigm. Essentially, we create an auxiliary model (student) to mimic the behaviour of the primary model (teacher). At run-time, our approach is to use the teacher for predicting new instances and monitoring the mimicking loss of the student for concept drift detection. In a set of experiments using 19 data streams, we show that the proposed approach can detect concept drift and present a competitive behaviour relative to the state of the art approaches.