 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVehicle Occurrence-based Parking Space Detection
Jun 16, 2023Smart-parking solutions use sensors, cameras, and data analysis to improve parking efficiency and reduce traffic congestion. Computer vision-based methods have been used extensively in recent years to tackle the problem of parking lot management, but most of the works assume that the parking spots are manually labeled, impacting the cost and feasibility of deployment. To fill this gap, this work presents an automatic parking space detection method, which receives a sequence of images of a parking lot and returns a list of coordinates identifying the detected parking spaces. The proposed method employs instance segmentation to identify cars and, using vehicle occurrence, generate a heat map of parking spaces. The results using twelve different subsets from the PKLot and CNRPark-EXT parking lot datasets show that the method achieved an AP25 score up to 95.60\% and AP50 score up to 79.90\%.
Fast & Furious: Modelling Malware Detection as Evolving Data Streams
May 24, 2022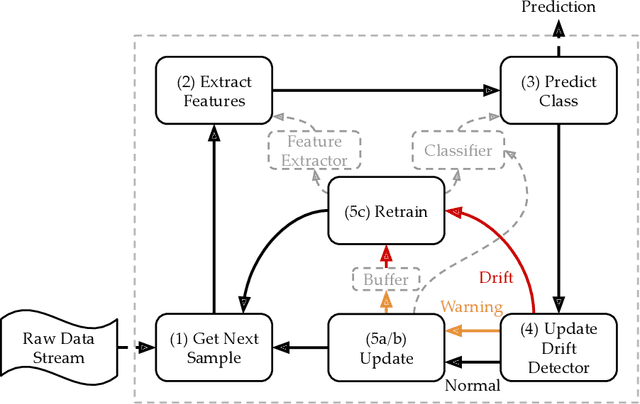
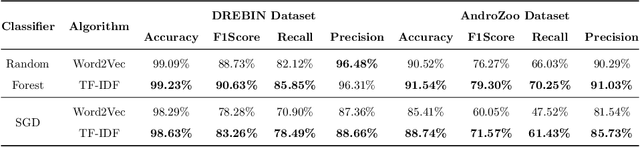
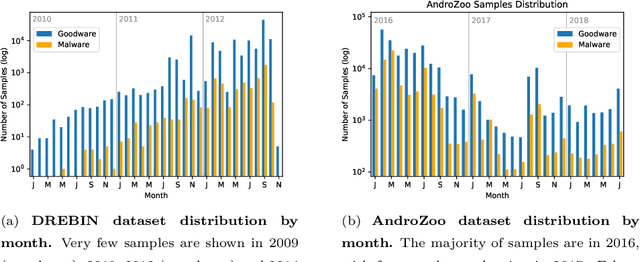
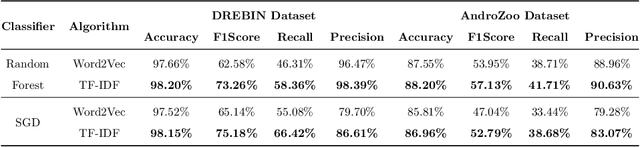
Malware is a major threat to computer systems and imposes many challenges to cyber security. Targeted threats, such as ransomware, cause millions of dollars in losses every year. The constant increase of malware infections has been motivating popular antiviruses (AVs) to develop dedicated detection strategies, which include meticulously crafted machine learning (ML) pipelines. However, malware developers unceasingly change their samples features to bypass detection. This constant evolution of malware samples causes changes to the data distribution (i.e., concept drifts) that directly affect ML model detection rates. In this work, we evaluate the impact of concept drift on malware classifiers for two Android datasets: DREBIN (~130K apps) and AndroZoo (~350K apps). Android is a ubiquitous operating system for smartphones, which stimulates attackers to regularly create and update malware to the platform. We conducted a longitudinal evaluation by (i) classifying malware samples collected over nine years (2009-2018), (ii) reviewing concept drift detection algorithms to attest its pervasiveness, (iii) comparing distinct ML approaches to mitigate the issue, and (iv) proposing an ML data stream pipeline that outperformed literature approaches. As a result, we observed that updating every component of the pipeline in response to concept drifts allows the classification model to achieve increasing detection rates as the data representation (extracted features) is updated. Furthermore, we discuss the impact of the changes on the classification models by comparing the variations in the extracted features.
Classifier Pool Generation based on a Two-level Diversity Approach
Nov 03, 2020
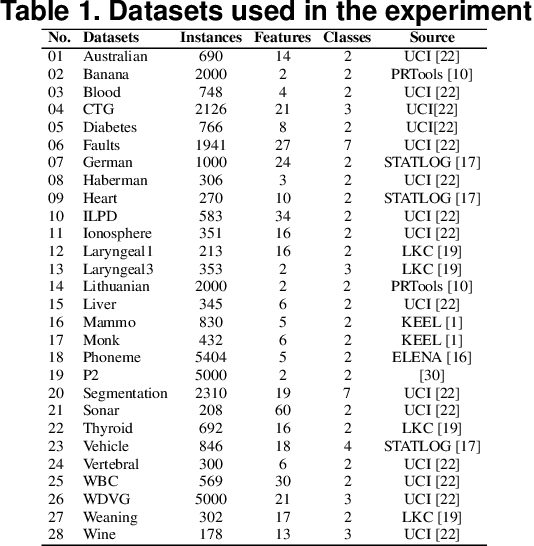
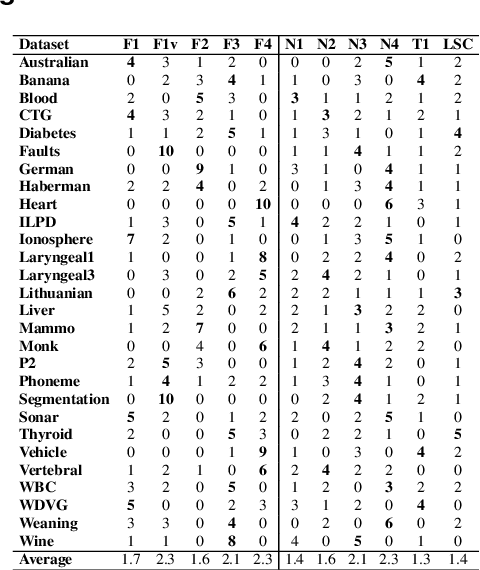
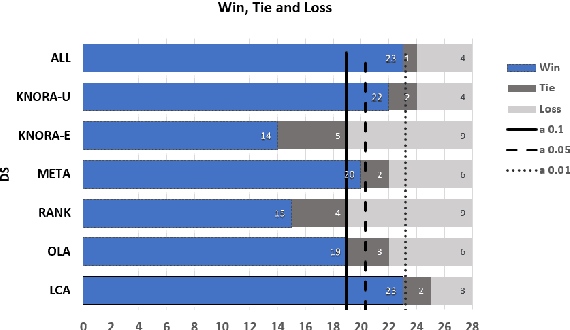
This paper describes a classifier pool generation method guided by the diversity estimated on the data complexity and classifier decisions. First, the behavior of complexity measures is assessed by considering several subsamples of the dataset. The complexity measures with high variability across the subsamples are selected for posterior pool adaptation, where an evolutionary algorithm optimizes diversity in both complexity and decision spaces. A robust experimental protocol with 28 datasets and 20 replications is used to evaluate the proposed method. Results show significant accuracy improvements in 69.4% of the experiments when Dynamic Classifier Selection and Dynamic Ensemble Selection methods are applied.
Machine Learning (In) Security: A Stream of Problems
Oct 30, 2020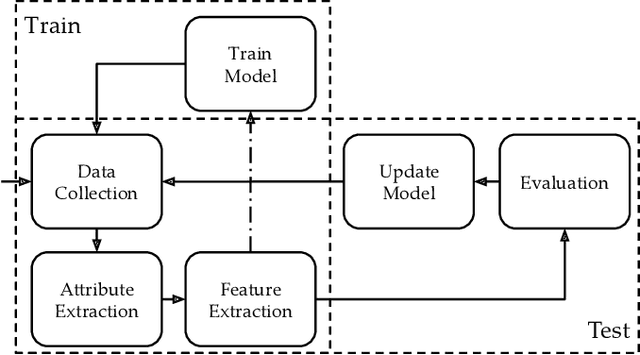
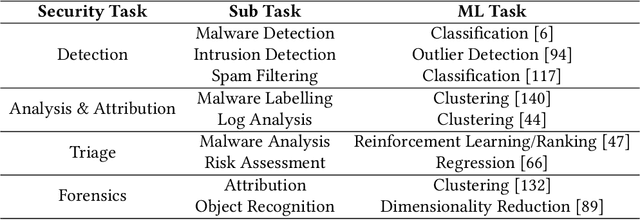

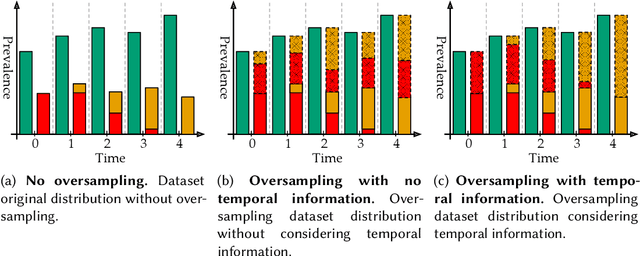
Machine Learning (ML) has been widely applied to cybersecurity, and is currently considered state-of-the-art for solving many of the field's open issues. However, it is very difficult to evaluate how good the produced solutions are, since the challenges faced in security may not appear in other areas (at least not in the same way). One of these challenges is the concept drift, that actually creates an arms race between attackers and defenders, given that any attacker may create novel, different threats as time goes by (to overcome defense solutions) and this "evolution" is not always considered in many works. Due to this type of issue, it is fundamental to know how to correctly build and evaluate a ML-based security solution. In this work, we list, detail, and discuss some of the challenges of applying ML to cybersecurity, including concept drift, concept evolution, delayed labels, and adversarial machine learning. We also show how existing solutions fail and, in some cases, we propose possible solutions to fix them.
A Comprehensive Comparison of End-to-End Approaches for Handwritten Digit String Recognition
Oct 29, 2020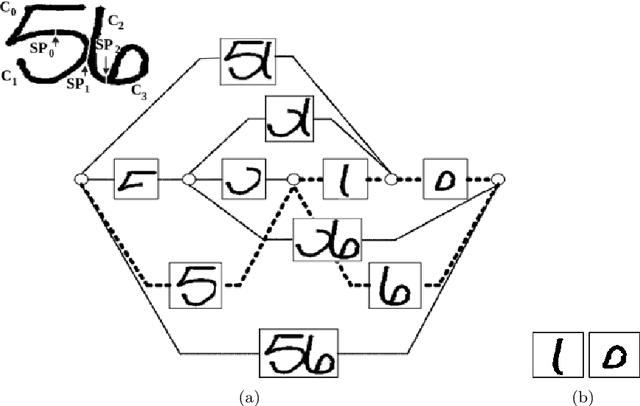
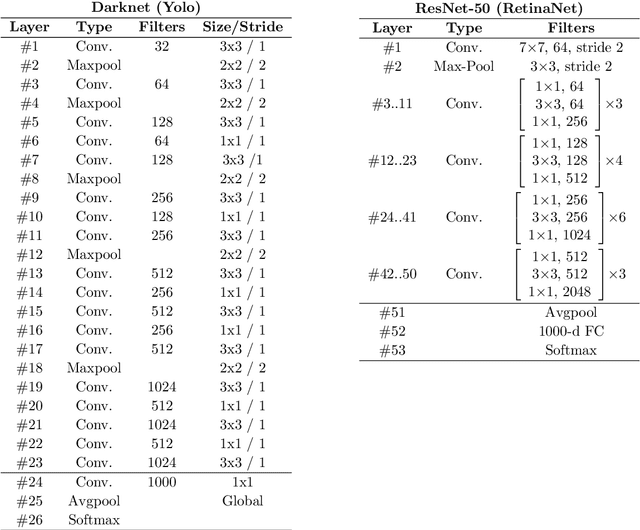
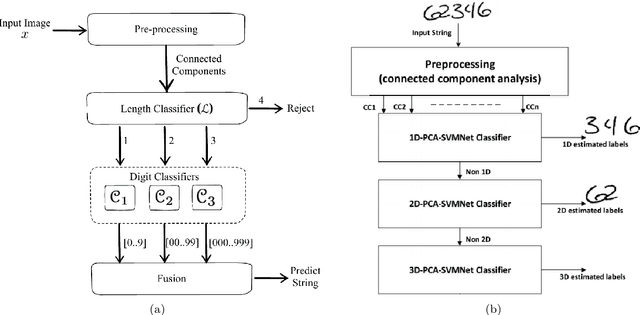
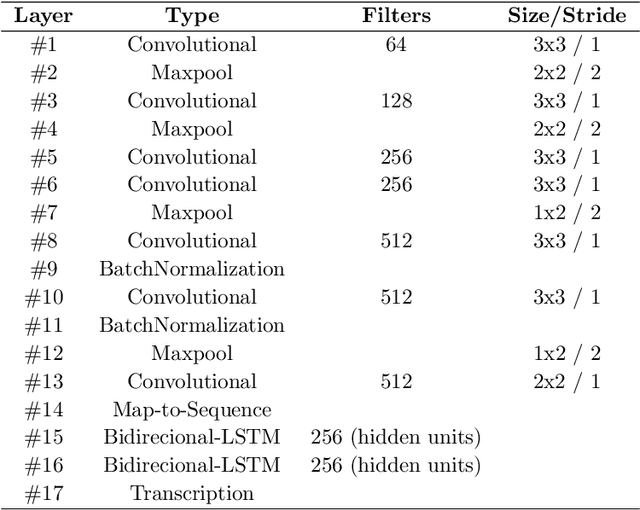
Over the last decades, most approaches proposed for handwritten digit string recognition (HDSR) have resorted to digit segmentation, which is dominated by heuristics, thereby imposing substantial constraints on the final performance. Few of them have been based on segmentation-free strategies where each pixel column has a potential cut location. Recently, segmentation-free strategies has added another perspective to the problem, leading to promising results. However, these strategies still show some limitations when dealing with a large number of touching digits. To bridge the resulting gap, in this paper, we hypothesize that a string of digits can be approached as a sequence of objects. We thus evaluate different end-to-end approaches to solve the HDSR problem, particularly in two verticals: those based on object-detection (e.g., Yolo and RetinaNet) and those based on sequence-to-sequence representation (CRNN). The main contribution of this work lies in its provision of a comprehensive comparison with a critical analysis of the above mentioned strategies on five benchmarks commonly used to assess HDSR, including the challenging Touching Pair dataset, NIST SD19, and two real-world datasets (CAR and CVL) proposed for the ICFHR 2014 competition on HDSR. Our results show that the Yolo model compares favorably against segmentation-free models with the advantage of having a shorter pipeline that minimizes the presence of heuristics-based models. It achieved a 97%, 96%, and 84% recognition rate on the NIST-SD19, CAR, and CVL datasets, respectively.
Intrapersonal Parameter Optimization for Offline Handwritten Signature Augmentation
Oct 13, 2020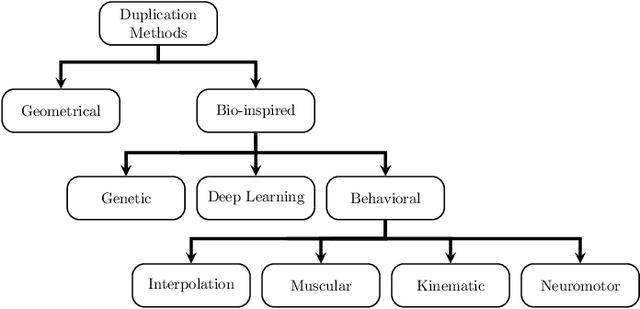
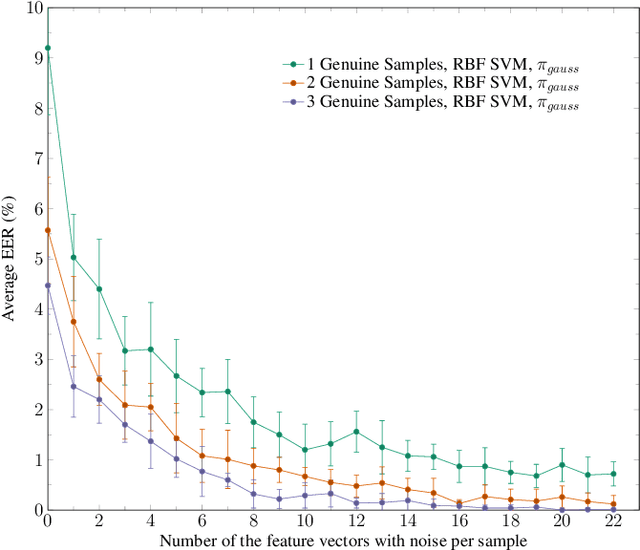
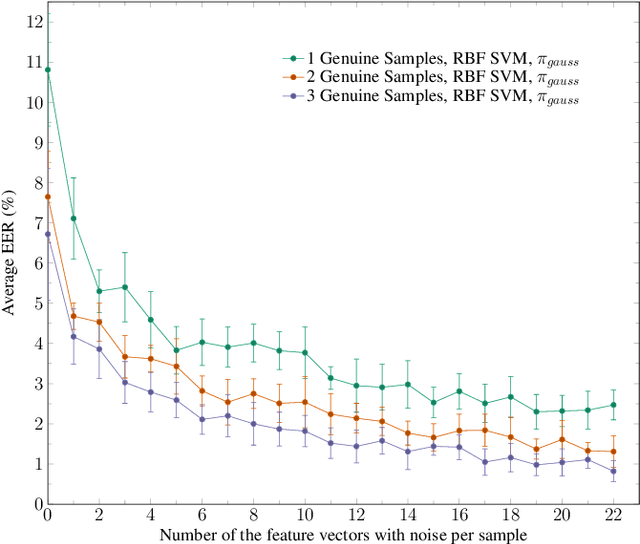
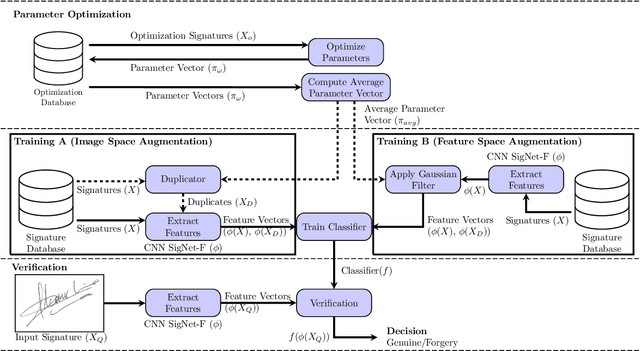
Usually, in a real-world scenario, few signature samples are available to train an automatic signature verification system (ASVS). However, such systems do indeed need a lot of signatures to achieve an acceptable performance. Neuromotor signature duplication methods and feature space augmentation methods may be used to meet the need for an increase in the number of samples. Such techniques manually or empirically define a set of parameters to introduce a degree of writer variability. Therefore, in the present study, a method to automatically model the most common writer variability traits is proposed. The method is used to generate offline signatures in the image and the feature space and train an ASVS. We also introduce an alternative approach to evaluate the quality of samples considering their feature vectors. We evaluated the performance of an ASVS with the generated samples using three well-known offline signature datasets: GPDS, MCYT-75, and CEDAR. In GPDS-300, when the SVM classifier was trained using one genuine signature per writer and the duplicates generated in the image space, the Equal Error Rate (EER) decreased from 5.71% to 1.08%. Under the same conditions, the EER decreased to 1.04% using the feature space augmentation technique. We also verified that the model that generates duplicates in the image space reproduces the most common writer variability traits in the three different datasets.
Legal Document Classification: An Application to Law Area Prediction of Petitions to Public Prosecution Service
Oct 13, 2020



In recent years, there has been an increased interest in the application of Natural Language Processing (NLP) to legal documents. The use of convolutional and recurrent neural networks along with word embedding techniques have presented promising results when applied to textual classification problems, such as sentiment analysis and topic segmentation of documents. This paper proposes the use of NLP techniques for textual classification, with the purpose of categorizing the descriptions of the services provided by the Public Prosecutor's Office of the State of Paran\'a to the population in one of the areas of law covered by the institution. Our main goal is to automate the process of assigning petitions to their respective areas of law, with a consequent reduction in costs and time associated with such process while allowing the allocation of human resources to more complex tasks. In this paper, we compare different approaches to word representations in the aforementioned task: including document-term matrices and a few different word embeddings. With regards to the classification models, we evaluated three different families: linear models, boosted trees and neural networks. The best results were obtained with a combination of Word2Vec trained on a domain-specific corpus and a Recurrent Neural Network (RNN) architecture (more specifically, LSTM), leading to an accuracy of 90\% and F1-Score of 85\% in the classification of eighteen categories (law areas).
Impact of lung segmentation on the diagnosis and explanation of COVID-19 in chest X-ray images
Sep 21, 2020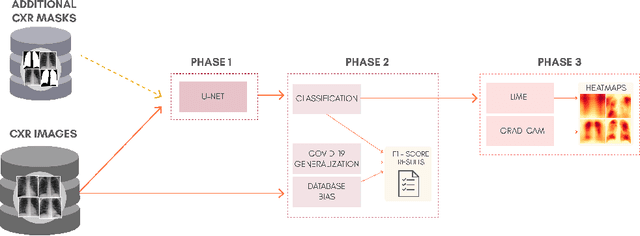
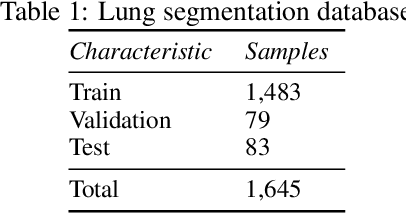
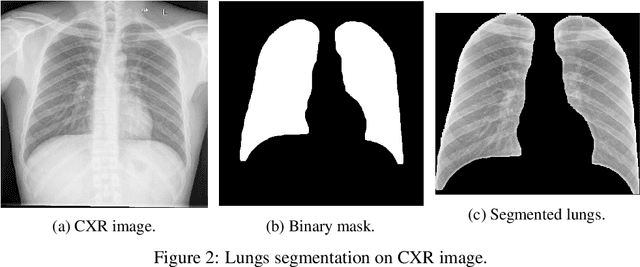
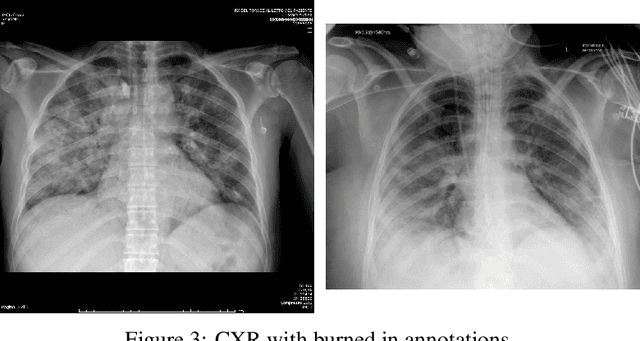
The COVID-19 pandemic is undoubtedly one of the biggest public health crises our society has ever faced. This paper's main objectives are to demonstrate the impact of lung segmentation in COVID-19 automatic identification using CXR images and evaluate which contents of the image decisively contribute to the identification. We have performed lung segmentation using a U-Net CNN architecture, and the classification using three well-known CNN architectures: VGG, ResNet, and Inception. To estimate the impact of lung segmentation, we applied some Explainable Artificial Intelligence (XAI), such as LIME and Grad-CAM. To evaluate our approach, we built a database named RYDLS-20-v2, following our previous publication and the COVIDx database guidelines. We evaluated the impact of creating a COVID-19 CXR image database from different sources, called database bias, and the COVID-19 generalization from one database to another, representing our less biased scenario. The experimental results of the segmentation achieved a Jaccard distance of 0.034 and a Dice coefficient of 0.982. In the best and more realistic scenario, we achieved an F1-Score of 0.74 and an area under the ROC curve of 0.9 for COVID-19 identification using segmented CXR images. Further testing and XAI techniques suggest that segmented CXR images represent a much more realistic and less biased performance. More importantly, the experiments conducted show that even after segmentation, there is a strong bias introduced by underlying factors from the data sources, and more efforts regarding the creation of a more significant and comprehensive database still need to be done.
Single-sample writers -- "Document Filter" and their impacts on writer identification
May 18, 2020



The writing can be used as an important biometric modality which allows to unequivocally identify an individual. It happens because the writing of two different persons present differences that can be explored both in terms of graphometric properties or even by addressing the manuscript as a digital image, taking into account the use of image processing techniques that can properly capture different visual attributes of the image (e.g. texture). In this work, perform a detailed study in which we dissect whether or not the use of a database with only a single sample taken from some writers may skew the results obtained in the experimental protocol. In this sense, we propose here what we call "document filter". The "document filter" protocol is supposed to be used as a preprocessing technique, such a way that all the data taken from fragments of the same document must be placed either into the training or into the test set. The rationale behind it, is that the classifier must capture the features from the writer itself, and not features regarding other particularities which could affect the writing in a specific document (i.e. emotional state of the writer, pen used, paper type, and etc.). By analyzing the literature, one can find several works dealing the writer identification problem. However, the performance of the writer identification systems must be evaluated also taking into account the occurrence of writer volunteers who contributed with a single sample during the creation of the manuscript databases. To address the open issue investigated here, a comprehensive set of experiments was performed on the IAM, BFL and CVL databases. They have shown that, in the most extreme case, the recognition rate obtained using the "document filter" protocol drops from 81.80% to 50.37%.
Ocular Recognition Databases and Competitions: A Survey
Nov 21, 2019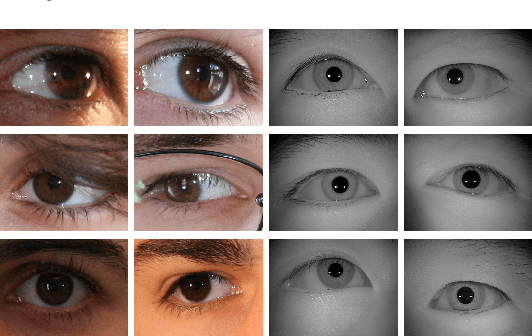
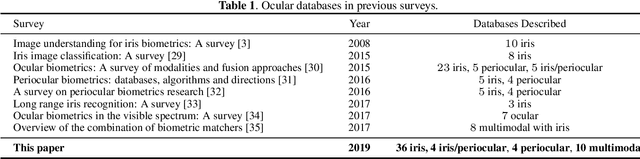
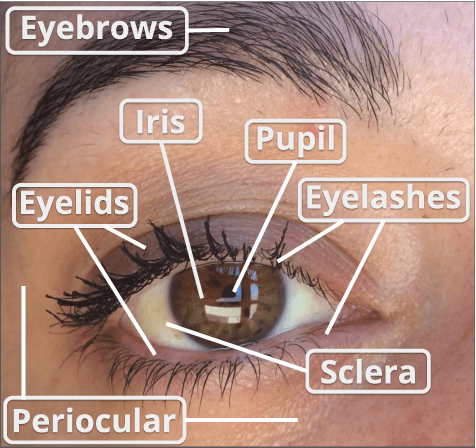
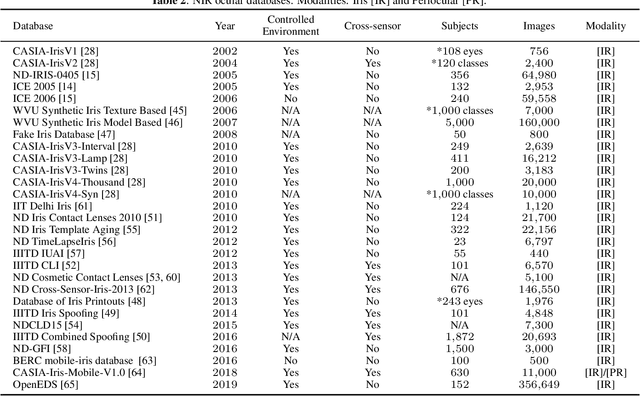
The use of the iris and periocular region as biometric traits has been extensively investigated, mainly due to the singularity of the iris features and the use of the periocular region when the image resolution is not sufficient to extract iris information. In addition to providing information about an individual's identity, features extracted from these traits can also be explored to obtain other information such as the individual's gender, the influence of drug use, the use of contact lenses, spoofing, among others. This work presents a survey of the databases created for ocular recognition, detailing their protocols and how their images were acquired. We also describe and discuss the most popular ocular recognition competitions (contests), highlighting the submitted algorithms that achieved the best results using only iris trait and also fusing iris and periocular region information. Finally, we describe some relevant works applying deep learning techniques to ocular recognition and point out new challenges and future directions. Considering that there are a large number of ocular databases, and each one is usually designed for a specific problem, we believe this survey can provide a broad overview of the challenges in ocular biometrics.