 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Different Annotation Strategies for Deployment of Parking Spaces Classification Systems
Jul 22, 2022

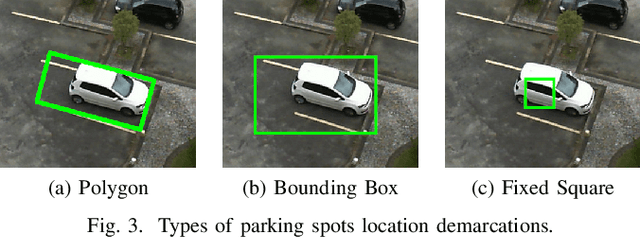
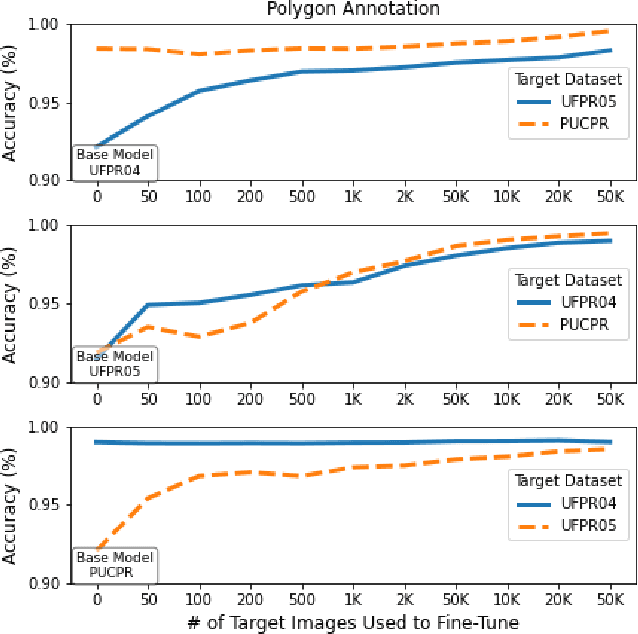
When using vision-based approaches to classify individual parking spaces between occupied and empty, human experts often need to annotate the locations and label a training set containing images collected in the target parking lot to fine-tune the system. We propose investigating three annotation types (polygons, bounding boxes, and fixed-size squares), providing different data representations of the parking spaces. The rationale is to elucidate the best trade-off between handcraft annotation precision and model performance. We also investigate the number of annotated parking spaces necessary to fine-tune a pre-trained model in the target parking lot. Experiments using the PKLot dataset show that it is possible to fine-tune a model to the target parking lot with less than 1,000 labeled samples, using low precision annotations such as fixed-size squares.
End-to-End Approach for Recognition of Historical Digit Strings
Apr 28, 2021
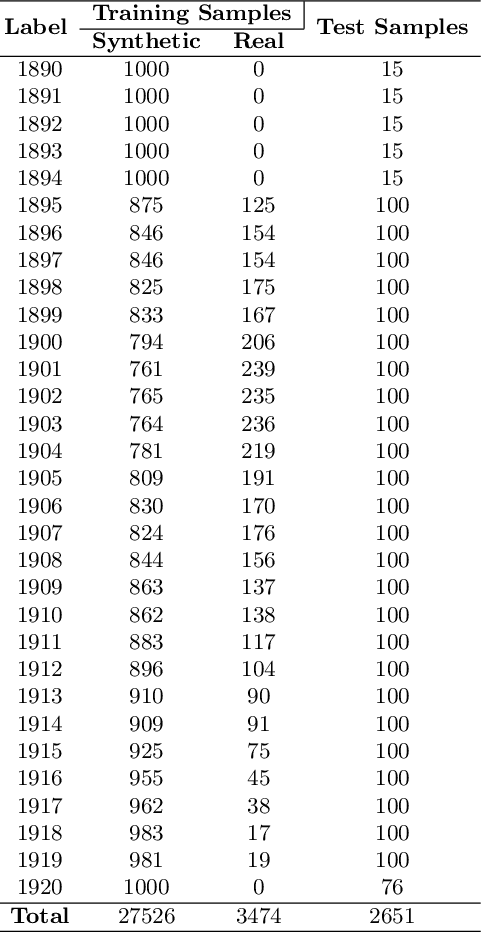
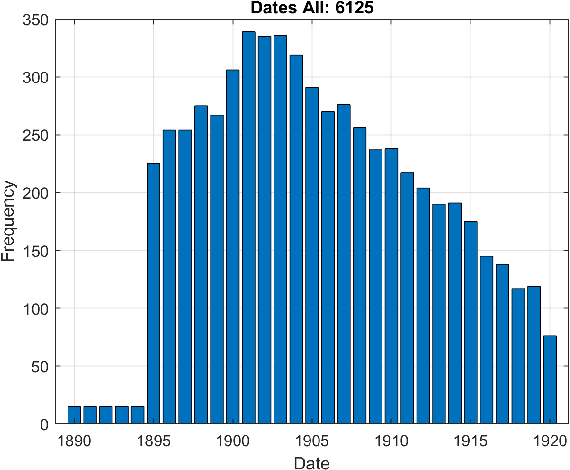

The plethora of digitalised historical document datasets released in recent years has rekindled interest in advancing the field of handwriting pattern recognition. In the same vein, a recently published data set, known as ARDIS, presents handwritten digits manually cropped from 15.000 scanned documents of Swedish church books and exhibiting various handwriting styles. To this end, we propose an end-to-end segmentation-free deep learning approach to handle this challenging ancient handwriting style of dates present in the ARDIS dataset (4-digits long strings). We show that with slight modifications in the VGG-16 deep model, the framework can achieve a recognition rate of 93.2%, resulting in a feasible solution free of heuristic methods, segmentation, and fusion methods. Moreover, the proposed approach outperforms the well-known CRNN method (a model widely applied in handwriting recognition tasks).
A Comprehensive Comparison of End-to-End Approaches for Handwritten Digit String Recognition
Oct 29, 2020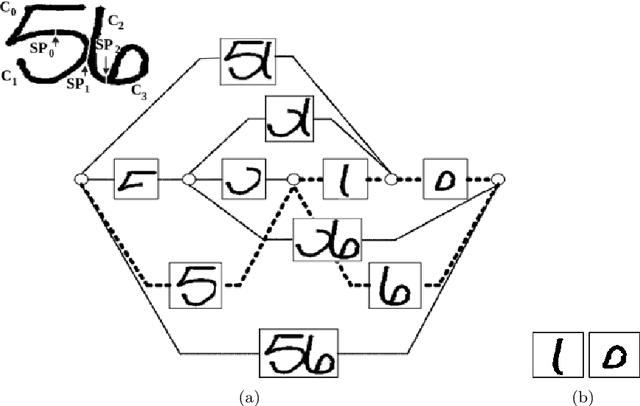
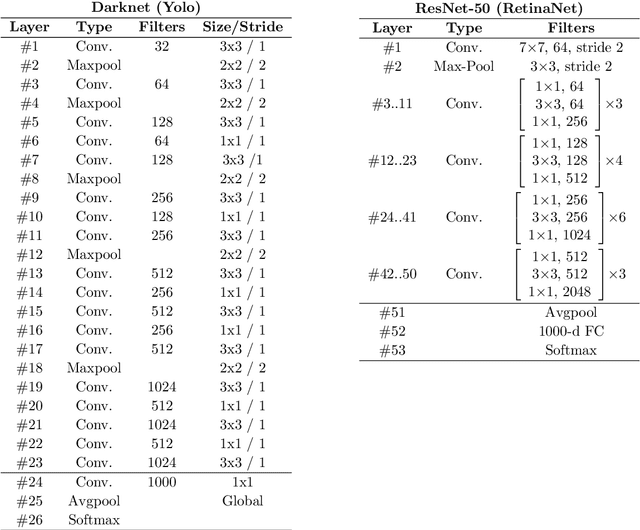
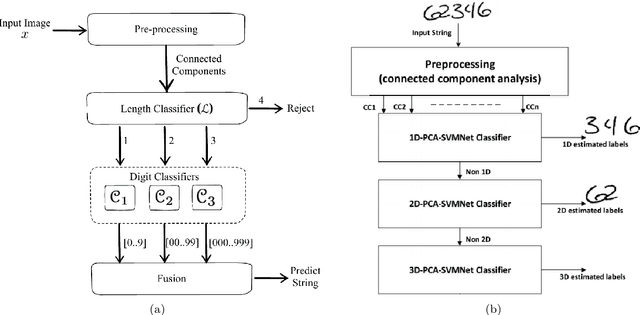
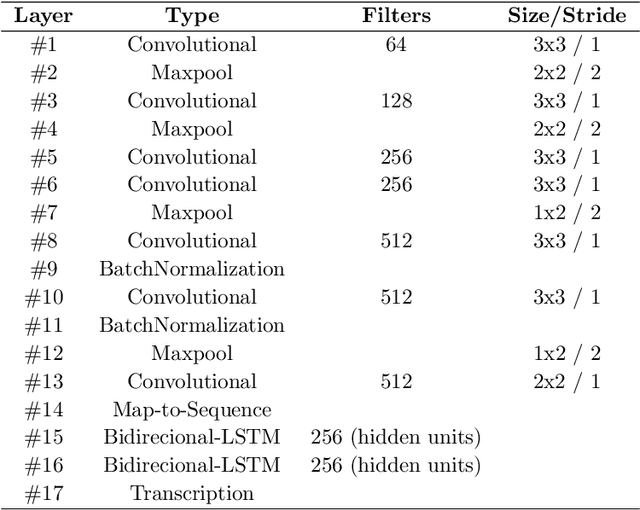
Over the last decades, most approaches proposed for handwritten digit string recognition (HDSR) have resorted to digit segmentation, which is dominated by heuristics, thereby imposing substantial constraints on the final performance. Few of them have been based on segmentation-free strategies where each pixel column has a potential cut location. Recently, segmentation-free strategies has added another perspective to the problem, leading to promising results. However, these strategies still show some limitations when dealing with a large number of touching digits. To bridge the resulting gap, in this paper, we hypothesize that a string of digits can be approached as a sequence of objects. We thus evaluate different end-to-end approaches to solve the HDSR problem, particularly in two verticals: those based on object-detection (e.g., Yolo and RetinaNet) and those based on sequence-to-sequence representation (CRNN). The main contribution of this work lies in its provision of a comprehensive comparison with a critical analysis of the above mentioned strategies on five benchmarks commonly used to assess HDSR, including the challenging Touching Pair dataset, NIST SD19, and two real-world datasets (CAR and CVL) proposed for the ICFHR 2014 competition on HDSR. Our results show that the Yolo model compares favorably against segmentation-free models with the advantage of having a shorter pipeline that minimizes the presence of heuristics-based models. It achieved a 97%, 96%, and 84% recognition rate on the NIST-SD19, CAR, and CVL datasets, respectively.
An End-to-End Approach for Recognition of Modern and Historical Handwritten Numeral Strings
Mar 28, 2020


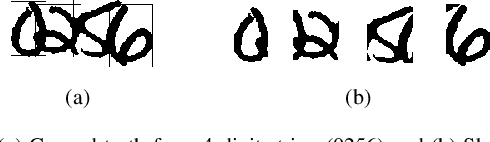
An end-to-end solution for handwritten numeral string recognition is proposed, in which the numeral string is considered as composed of objects automatically detected and recognized by a YoLo-based model. The main contribution of this paper is to avoid heuristic-based methods for string preprocessing and segmentation, the need for task-oriented classifiers, and also the use of specific constraints related to the string length. A robust experimental protocol based on several numeral string datasets, including one composed of historical documents, has shown that the proposed method is a feasible end-to-end solution for numeral string recognition. Besides, it reduces the complexity of the string recognition task considerably since it drops out classical steps, in special preprocessing, segmentation, and a set of classifiers devoted to strings with a specific length.