 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Prototypical Signature Approach for Writer-Independent Offline Signature Verification
Jun 16, 2026Offline handwritten signature verification aims to distinguish genuine from forged signatures using static images. Since real forgeries are rarely available, negative samples are usually randomly drawn from genuine signatures of other users to create training data. However, this random selection often lacks diversity, increases redundancy, and escalates computational cost, leading to inefficient training. We propose a data-driven strategy to generate diverse, informative negative samples using prototypical signatures, which are compact, non-identifiable summaries of genuine signature features. Based on the experiments results, we conclude that (i) prototypical signatures yield more informative negative samples, improving the detection of skilled forgeries; (ii) the proposed approach is backbone-agnostic, showing robustness across architectures; and (iii) when combined with a primal-form linear SVM, it serves as an alternative to RBF-based models while significantly improving scalability and computational efficiency. Implementation of the method is available at https://github.com/kdmoura/proto_hsv.
CaDrift: A Time-dependent Causal Generator of Drifting Data Streams
Feb 23, 2026This work presents Causal Drift Generator (CaDrift), a time-dependent synthetic data generator framework based on Structural Causal Models (SCMs). The framework produces a virtually infinite combination of data streams with controlled shift events and time-dependent data, making it a tool to evaluate methods under evolving data. CaDrift synthesizes various distributional and covariate shifts by drifting mapping functions of the SCM, which change underlying cause-and-effect relationships between features and the target. In addition, CaDrift models occasional perturbations by leveraging interventions in causal modeling. Experimental results show that, after distributional shift events, the accuracy of classifiers tends to drop, followed by a gradual retrieval, confirming the generator's effectiveness in simulating shifts. The framework has been made available on GitHub.
Local overlap reduction procedure for dynamic ensemble selection
Jun 16, 2022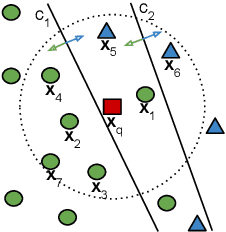
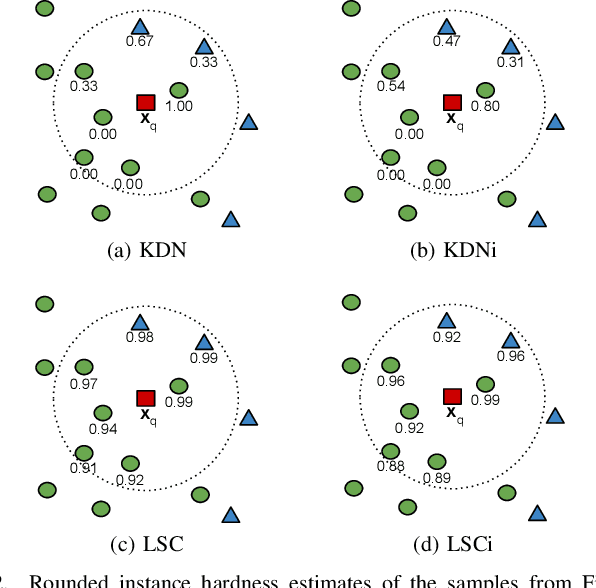
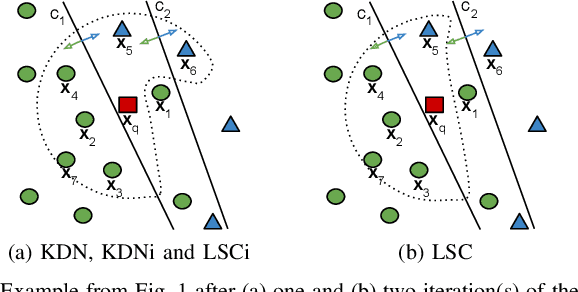
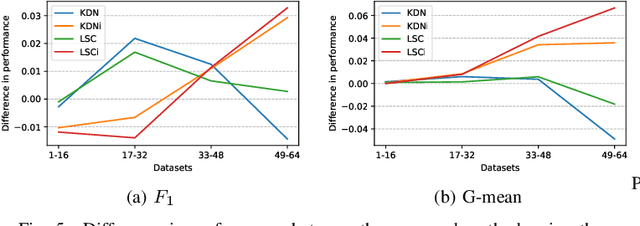
Class imbalance is a characteristic known for making learning more challenging for classification models as they may end up biased towards the majority class. A promising approach among the ensemble-based methods in the context of imbalance learning is Dynamic Selection (DS). DS techniques single out a subset of the classifiers in the ensemble to label each given unknown sample according to their estimated competence in the area surrounding the query. Because only a small region is taken into account in the selection scheme, the global class disproportion may have less impact over the system's performance. However, the presence of local class overlap may severely hinder the DS techniques' performance over imbalanced distributions as it not only exacerbates the effects of the under-representation but also introduces ambiguous and possibly unreliable samples to the competence estimation process. Thus, in this work, we propose a DS technique which attempts to minimize the effects of the local class overlap during the classifier selection procedure. The proposed method iteratively removes from the target region the instance perceived as the hardest to classify until a classifier is deemed competent to label the query sample. The known samples are characterized using instance hardness measures that quantify the local class overlap. Experimental results show that the proposed technique can significantly outperform the baseline as well as several other DS techniques, suggesting its suitability for dealing with class under-representation and overlap. Furthermore, the proposed technique still yielded competitive results when using an under-sampled, less overlapped version of the labelled sets, specially over the problems with a high proportion of minority class samples in overlap areas. Code available at https://github.com/marianaasouza/lords.
Dynamic Ensemble Selection Using Fuzzy Hyperboxes
May 20, 2022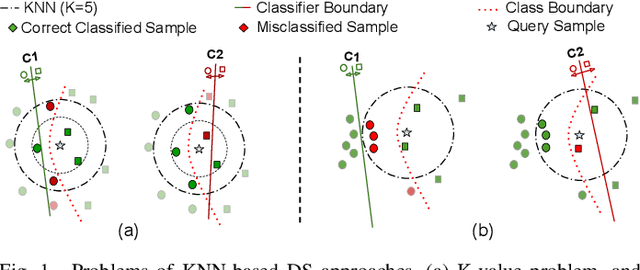
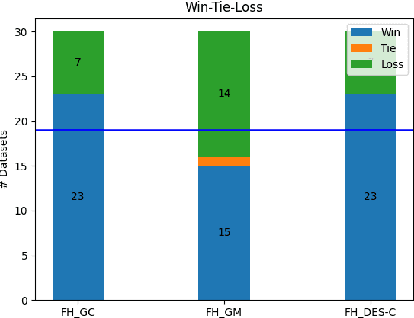
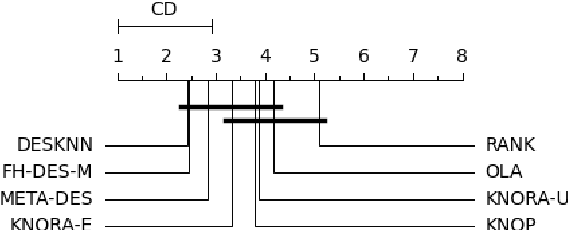
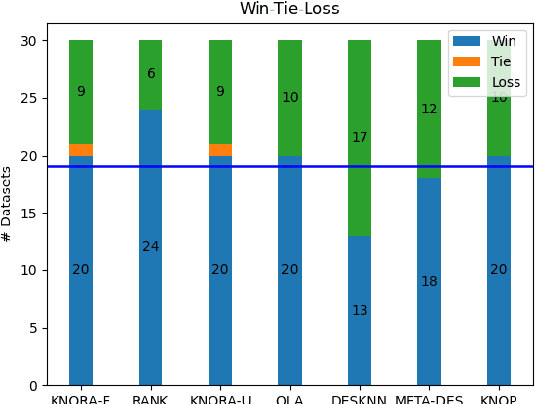
Most dynamic ensemble selection (DES) methods utilize the K-Nearest Neighbors (KNN) algorithm to estimate the competence of classifiers in a small region surrounding the query sample. However, KNN is very sensitive to the local distribution of the data. Moreover, it also has a high computational cost as it requires storing the whole data in memory and performing multiple distance calculations during inference. Hence, the dependency on the KNN algorithm ends up limiting the use of DES techniques for large-scale problems. This paper presents a new DES framework based on fuzzy hyperboxes called FH-DES. Each hyperbox can represent a group of samples using only two data points (Min and Max corners). Thus, the hyperbox-based system will have less computational complexity than other dynamic selection methods. In addition, despite the KNN-based approaches, the fuzzy hyperbox is not sensitive to the local data distribution. Therefore, the local distribution of the samples does not affect the system's performance. Furthermore, in this research, for the first time, misclassified samples are used to estimate the competence of the classifiers, which has not been observed in previous fusion approaches. Experimental results demonstrate that the proposed method has high classification accuracy while having a lower complexity when compared with the state-of-the-art dynamic selection methods. The implemented code is available at https://github.com/redavtalab/FH-DES_IJCNN.git.
Classifier Pool Generation based on a Two-level Diversity Approach
Nov 03, 2020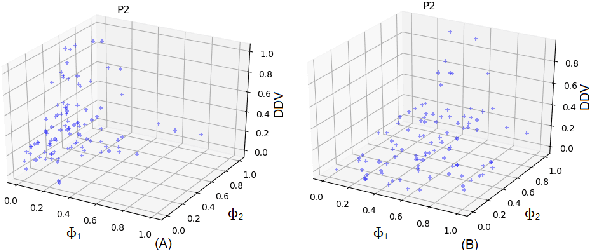
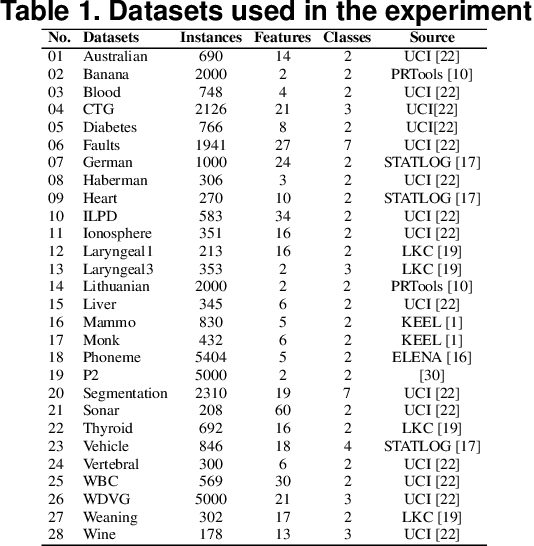
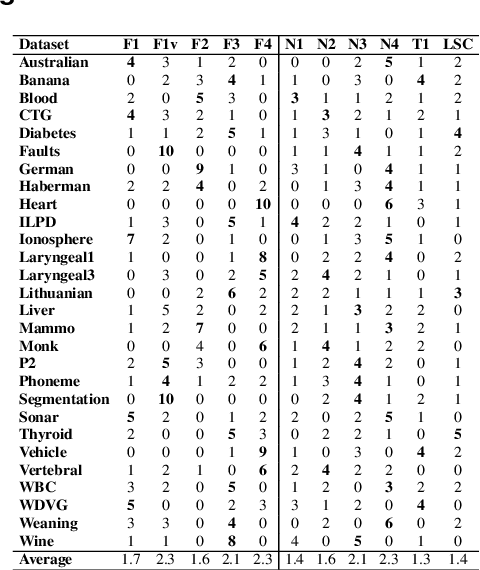
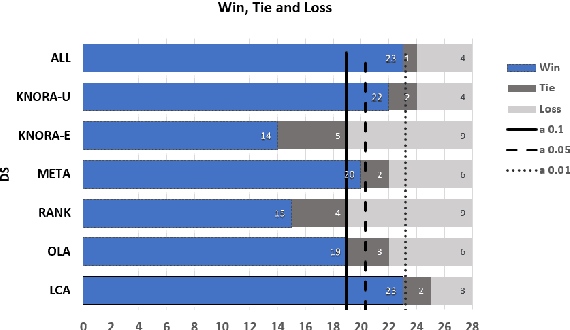
This paper describes a classifier pool generation method guided by the diversity estimated on the data complexity and classifier decisions. First, the behavior of complexity measures is assessed by considering several subsamples of the dataset. The complexity measures with high variability across the subsamples are selected for posterior pool adaptation, where an evolutionary algorithm optimizes diversity in both complexity and decision spaces. A robust experimental protocol with 28 datasets and 20 replications is used to evaluate the proposed method. Results show significant accuracy improvements in 69.4% of the experiments when Dynamic Classifier Selection and Dynamic Ensemble Selection methods are applied.
A Comprehensive Comparison of End-to-End Approaches for Handwritten Digit String Recognition
Oct 29, 2020
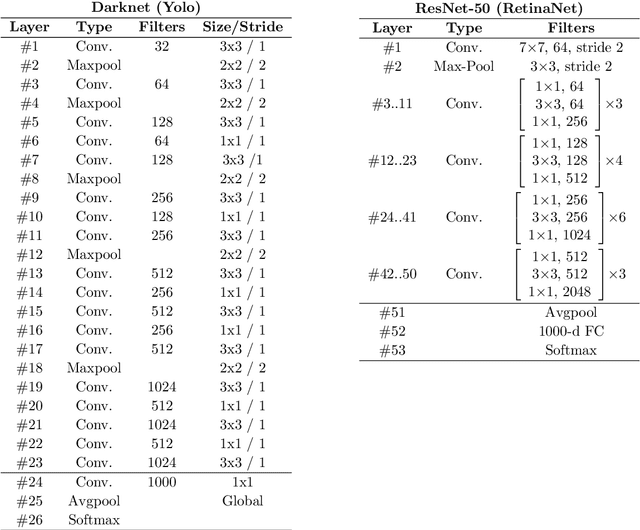
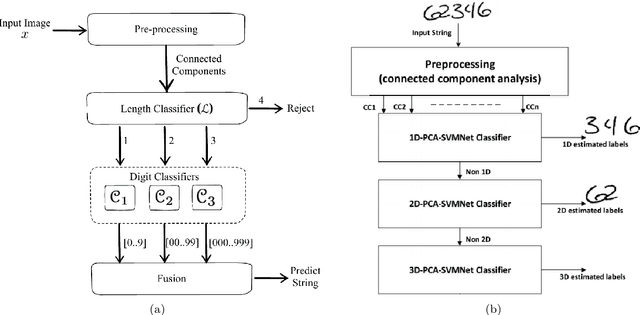
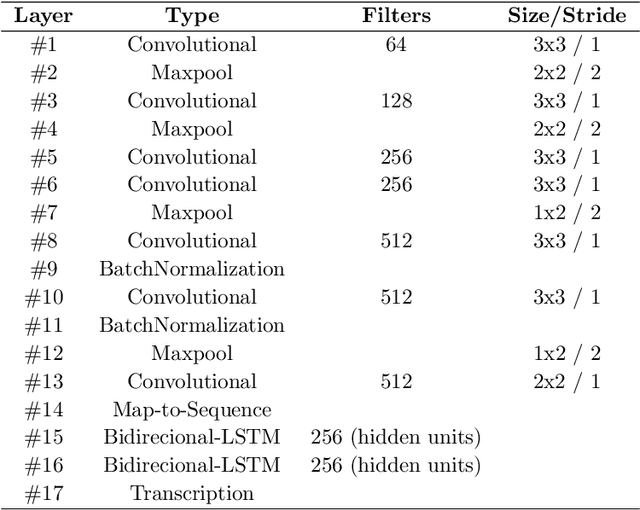
Over the last decades, most approaches proposed for handwritten digit string recognition (HDSR) have resorted to digit segmentation, which is dominated by heuristics, thereby imposing substantial constraints on the final performance. Few of them have been based on segmentation-free strategies where each pixel column has a potential cut location. Recently, segmentation-free strategies has added another perspective to the problem, leading to promising results. However, these strategies still show some limitations when dealing with a large number of touching digits. To bridge the resulting gap, in this paper, we hypothesize that a string of digits can be approached as a sequence of objects. We thus evaluate different end-to-end approaches to solve the HDSR problem, particularly in two verticals: those based on object-detection (e.g., Yolo and RetinaNet) and those based on sequence-to-sequence representation (CRNN). The main contribution of this work lies in its provision of a comprehensive comparison with a critical analysis of the above mentioned strategies on five benchmarks commonly used to assess HDSR, including the challenging Touching Pair dataset, NIST SD19, and two real-world datasets (CAR and CVL) proposed for the ICFHR 2014 competition on HDSR. Our results show that the Yolo model compares favorably against segmentation-free models with the advantage of having a shorter pipeline that minimizes the presence of heuristics-based models. It achieved a 97%, 96%, and 84% recognition rate on the NIST-SD19, CAR, and CVL datasets, respectively.
An Investigation of Feature Selection and Transfer Learning for Writer-Independent Offline Handwritten Signature Verification
Oct 19, 2020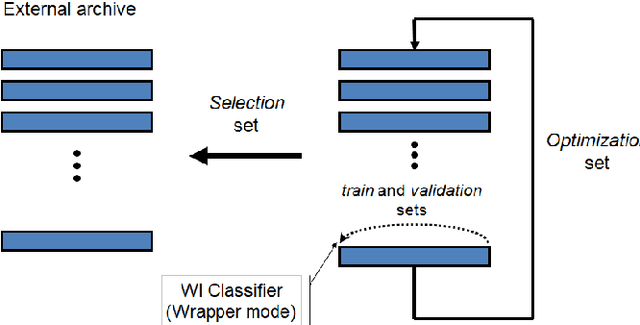
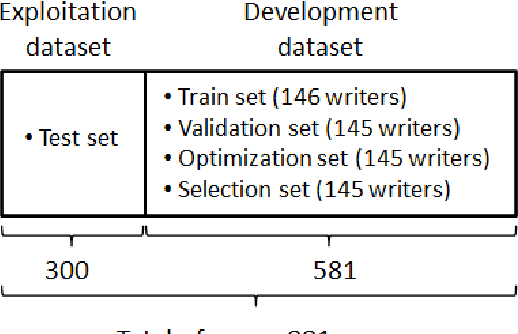
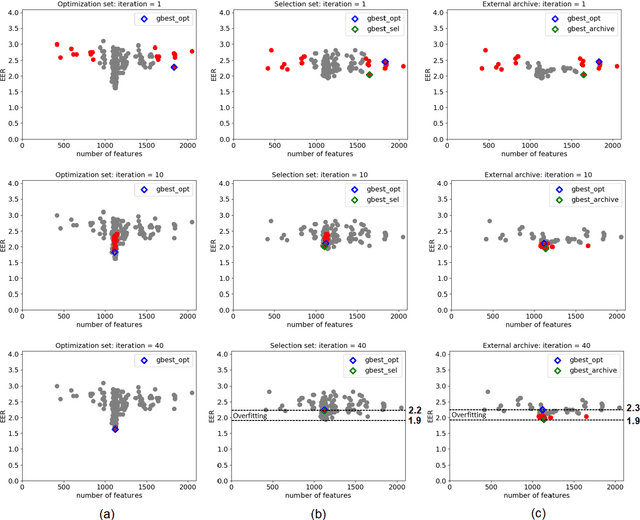

SigNet is a state of the art model for feature representation used for handwritten signature verification (HSV). This representation is based on a Deep Convolutional Neural Network (DCNN) and contains 2048 dimensions. When transposed to a dissimilarity space generated by the dichotomy transformation (DT), related to the writer-independent (WI) approach, these features may include redundant information. This paper investigates the presence of overfitting when using Binary Particle Swarm Optimization (BPSO) to perform the feature selection in a wrapper mode. We proposed a method based on a global validation strategy with an external archive to control overfitting during the search for the most discriminant representation. Moreover, an investigation is also carried out to evaluate the use of the selected features in a transfer learning context. The analysis is carried out on a writer-independent approach on the CEDAR, MCYT and GPDS datasets. The experimental results showed the presence of overfitting when no validation is used during the optimization process and the improvement when the global validation strategy with an external archive is used. Also, the space generated after feature selection can be used in a transfer learning context.
Intrapersonal Parameter Optimization for Offline Handwritten Signature Augmentation
Oct 13, 2020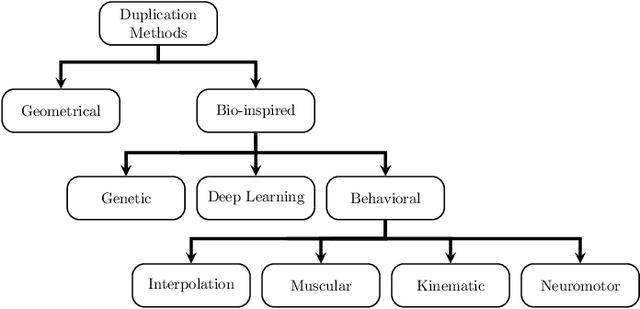
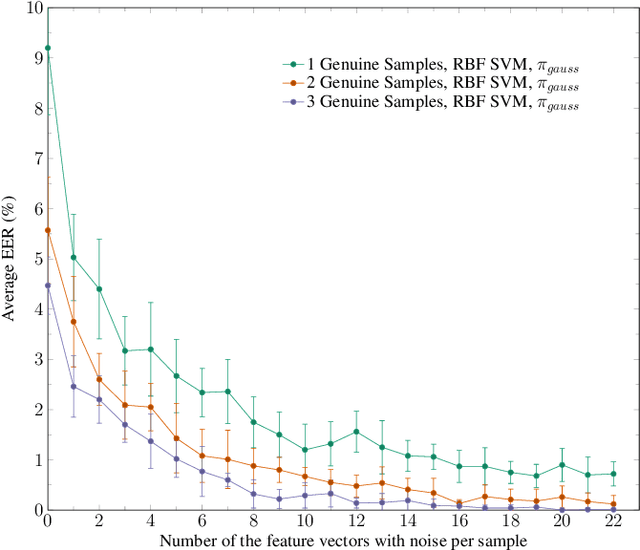
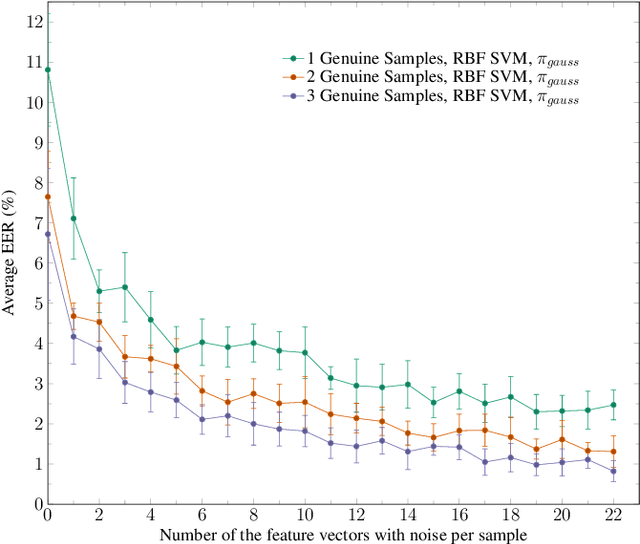
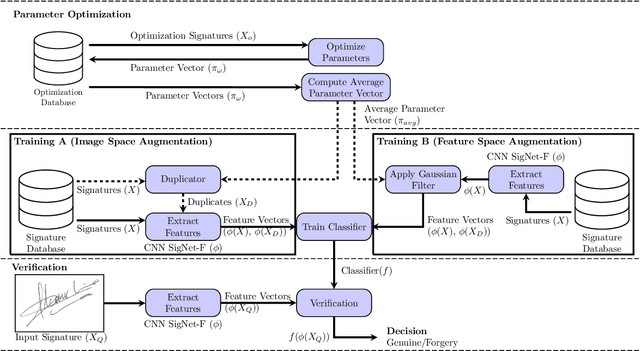
Usually, in a real-world scenario, few signature samples are available to train an automatic signature verification system (ASVS). However, such systems do indeed need a lot of signatures to achieve an acceptable performance. Neuromotor signature duplication methods and feature space augmentation methods may be used to meet the need for an increase in the number of samples. Such techniques manually or empirically define a set of parameters to introduce a degree of writer variability. Therefore, in the present study, a method to automatically model the most common writer variability traits is proposed. The method is used to generate offline signatures in the image and the feature space and train an ASVS. We also introduce an alternative approach to evaluate the quality of samples considering their feature vectors. We evaluated the performance of an ASVS with the generated samples using three well-known offline signature datasets: GPDS, MCYT-75, and CEDAR. In GPDS-300, when the SVM classifier was trained using one genuine signature per writer and the duplicates generated in the image space, the Equal Error Rate (EER) decreased from 5.71% to 1.08%. Under the same conditions, the EER decreased to 1.04% using the feature space augmentation technique. We also verified that the model that generates duplicates in the image space reproduces the most common writer variability traits in the three different datasets.
Random Forest for Dissimilarity-based Multi-view Learning
Jul 16, 2020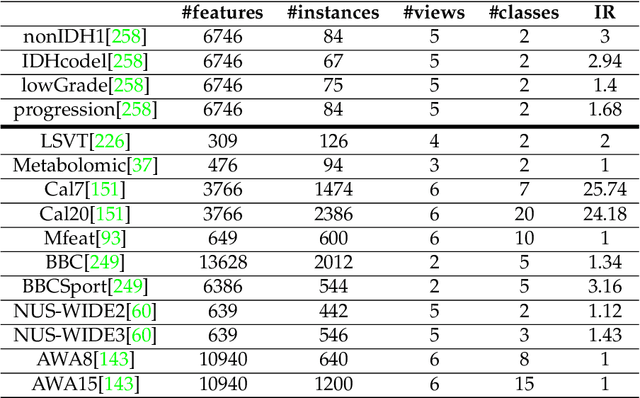
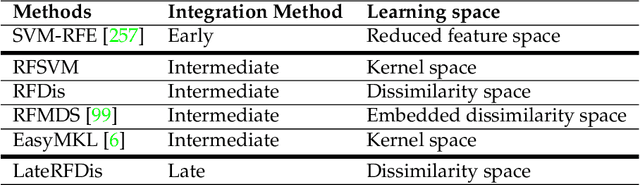
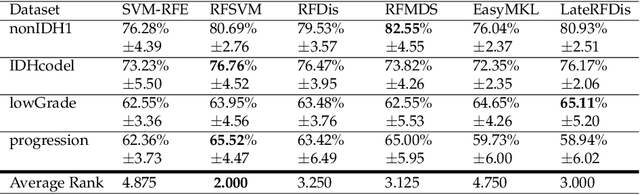
Many classification problems are naturally multi-view in the sense their data are described through multiple heterogeneous descriptions. For such tasks, dissimilarity strategies are effective ways to make the different descriptions comparable and to easily merge them, by (i) building intermediate dissimilarity representations for each view and (ii) fusing these representations by averaging the dissimilarities over the views. In this work, we show that the Random Forest proximity measure can be used to build the dissimilarity representations, since this measure reflects similarities between features but also class membership. We then propose a Dynamic View Selection method to better combine the view-specific dissimilarity representations. This allows to take a decision, on each instance to predict, with only the most relevant views for that instance. Experiments are conducted on several real-world multi-view datasets, and show that the Dynamic View Selection offers a significant improvement in performance compared to the simple average combination and two state-of-the-art static view combinations.
A Novel Random Forest Dissimilarity Measure for Multi-View Learning
Jul 06, 2020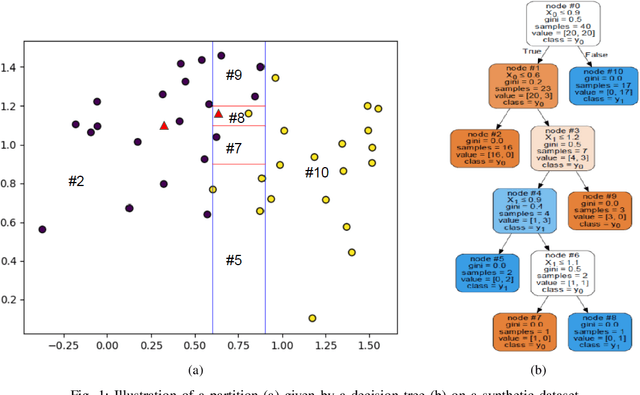
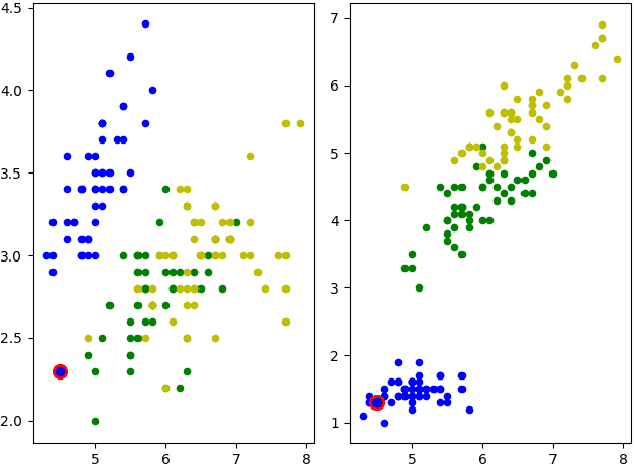
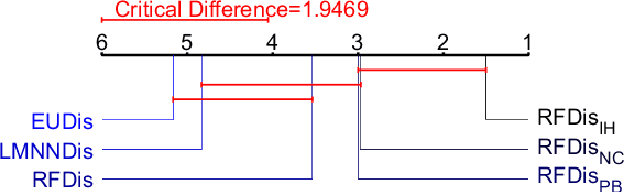
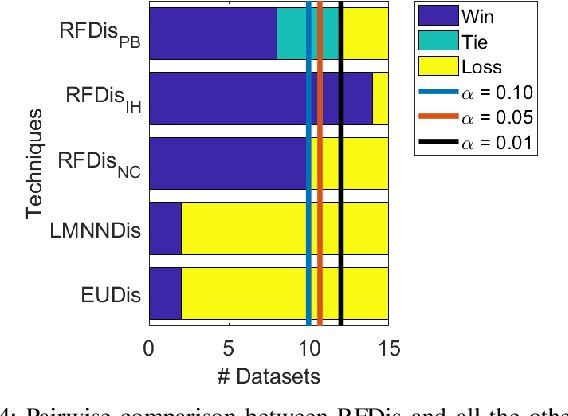
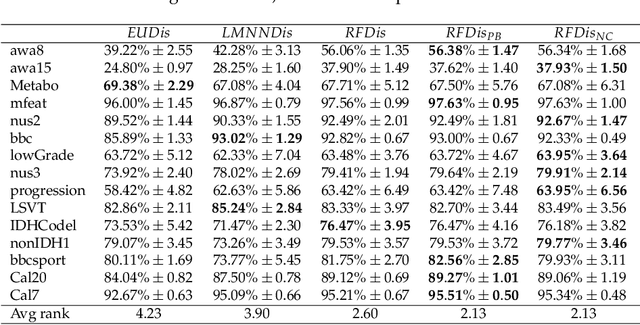
Multi-view learning is a learning task in which data is described by several concurrent representations. Its main challenge is most often to exploit the complementarities between these representations to help solve a classification/regression task. This is a challenge that can be met nowadays if there is a large amount of data available for learning. However, this is not necessarily true for all real-world problems, where data are sometimes scarce (e.g. problems related to the medical environment). In these situations, an effective strategy is to use intermediate representations based on the dissimilarities between instances. This work presents new ways of constructing these dissimilarity representations, learning them from data with Random Forest classifiers. More precisely, two methods are proposed, which modify the Random Forest proximity measure, to adapt it to the context of High Dimension Low Sample Size (HDLSS) multi-view classification problems. The second method, based on an Instance Hardness measurement, is significantly more accurate than other state-of-the-art measurements including the original RF Proximity measurement and the Large Margin Nearest Neighbor (LMNN) metric learning measurement.