 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Forest Dissimilarity for High-Dimension Low Sample Size Classification
Oct 23, 2023High dimension, low sample size (HDLSS) problems are numerous among real-world applications of machine learning. From medical images to text processing, traditional machine learning algorithms are usually unsuccessful in learning the best possible concept from such data. In a previous work, we proposed a dissimilarity-based approach for multi-view classification, the Random Forest Dissimilarity (RFD), that perfoms state-of-the-art results for such problems. In this work, we transpose the core principle of this approach to solving HDLSS classification problems, by using the RF similarity measure as a learned precomputed SVM kernel (RFSVM). We show that such a learned similarity measure is particularly suited and accurate for this classification context. Experiments conducted on 40 public HDLSS classification datasets, supported by rigorous statistical analyses, show that the RFSVM method outperforms existing methods for the majority of HDLSS problems and remains at the same time very competitive for low or non-HDLSS problems.
* 23 pages. To be published in statistics and computing (accepted September 26, 2023)
Approximating DTW with a convolutional neural network on EEG data
Jan 30, 2023



Dynamic Time Wrapping (DTW) is a widely used algorithm for measuring similarities between two time series. It is especially valuable in a wide variety of applications, such as clustering, anomaly detection, classification, or video segmentation, where the time-series have different timescales, are irregularly sampled, or are shifted. However, it is not prone to be considered as a loss function in an end-to-end learning framework because of its non-differentiability and its quadratic temporal complexity. While differentiable variants of DTW have been introduced by the community, they still present some drawbacks: computing the distance is still expensive and this similarity tends to blur some differences in the time-series. In this paper, we propose a fast and differentiable approximation of DTW by comparing two architectures: the first one for learning an embedding in which the Euclidean distance mimics the DTW, and the second one for directly predicting the DTW output using regression. We build the former by training a siamese neural network to regress the DTW value between two time-series. Depending on the nature of the activation function, this approximation naturally supports differentiation, and it is efficient to compute. We show, in a time-series retrieval context on EEG datasets, that our methods achieve at least the same level of accuracy as other DTW main approximations with higher computational efficiency. We also show that it can be used to learn in an end-to-end setting on long time series by proposing generative models of EEGs.
Pattern Spotting and Image Retrieval in Historical Documents using Deep Hashing
Aug 04, 2022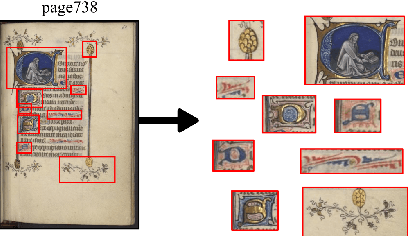
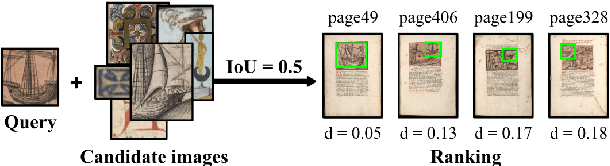


This paper presents a deep learning approach for image retrieval and pattern spotting in digital collections of historical documents. First, a region proposal algorithm detects object candidates in the document page images. Next, deep learning models are used for feature extraction, considering two distinct variants, which provide either real-valued or binary code representations. Finally, candidate images are ranked by computing the feature similarity with a given input query. A robust experimental protocol evaluates the proposed approach considering each representation scheme (real-valued and binary code) on the DocExplore image database. The experimental results show that the proposed deep models compare favorably to the state-of-the-art image retrieval approaches for images of historical documents, outperforming other deep models by 2.56 percentage points using the same techniques for pattern spotting. Besides, the proposed approach also reduces the search time by up to 200x and the storage cost up to 6,000x when compared to related works based on real-valued representations.
scikit-dyn2sel -- A Dynamic Selection Framework for Data Streams
Aug 17, 2020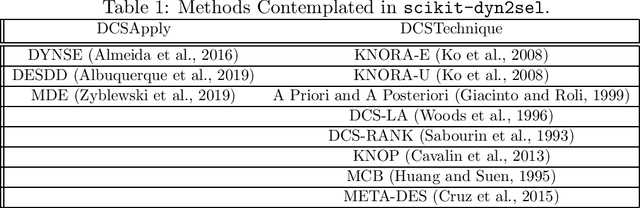

Mining data streams is a challenge per se. It must be ready to deal with an enormous amount of data and with problems not present in batch machine learning, such as concept drift. Therefore, applying a batch-designed technique, such as dynamic selection of classifiers (DCS) also presents a challenge. The dynamic characteristic of ensembles that deal with streams presents barriers to the application of traditional DCS techniques in such classifiers. scikit-dyn2sel is an open-source python library tailored for dynamic selection techniques in streaming data. scikit-dyn2sel's development follows code quality and testing standards, including PEP8 compliance and automated high test coverage using codecov.io and circleci.com. Source code, documentation, and examples are made available on GitHub at https://github.com/luccaportes/Scikit-DYN2SEL.
Random Forest for Dissimilarity-based Multi-view Learning
Jul 16, 2020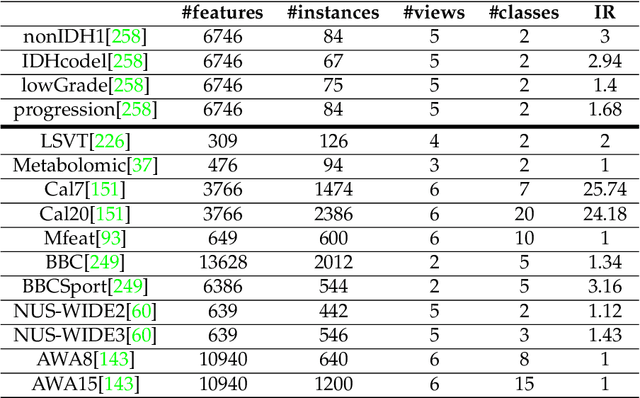
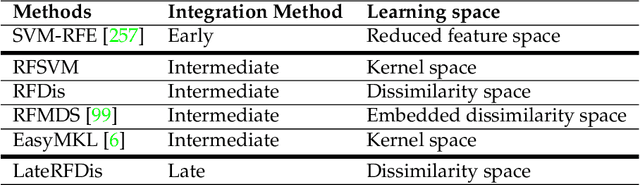
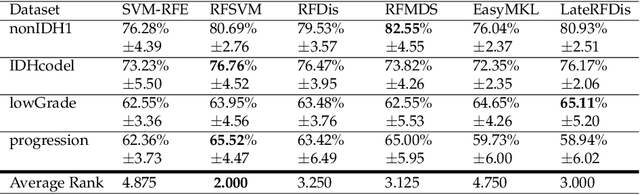
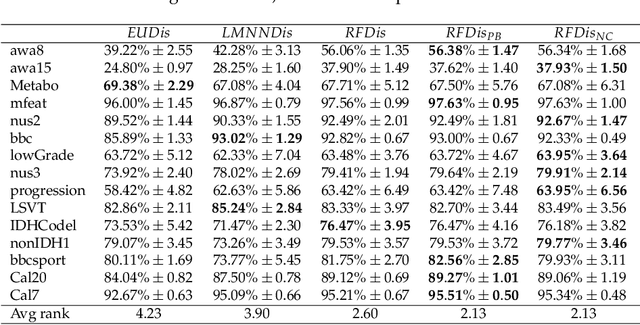
Many classification problems are naturally multi-view in the sense their data are described through multiple heterogeneous descriptions. For such tasks, dissimilarity strategies are effective ways to make the different descriptions comparable and to easily merge them, by (i) building intermediate dissimilarity representations for each view and (ii) fusing these representations by averaging the dissimilarities over the views. In this work, we show that the Random Forest proximity measure can be used to build the dissimilarity representations, since this measure reflects similarities between features but also class membership. We then propose a Dynamic View Selection method to better combine the view-specific dissimilarity representations. This allows to take a decision, on each instance to predict, with only the most relevant views for that instance. Experiments are conducted on several real-world multi-view datasets, and show that the Dynamic View Selection offers a significant improvement in performance compared to the simple average combination and two state-of-the-art static view combinations.
A Novel Random Forest Dissimilarity Measure for Multi-View Learning
Jul 06, 2020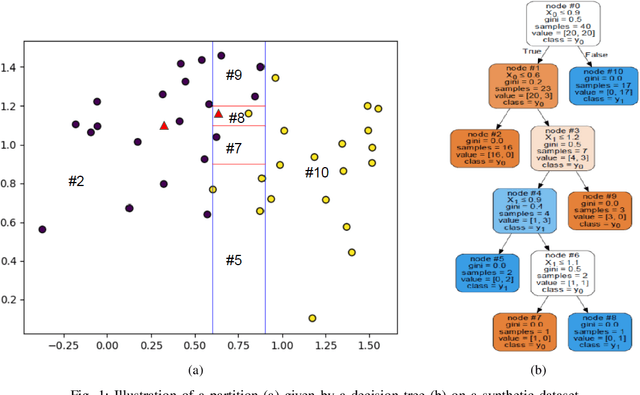
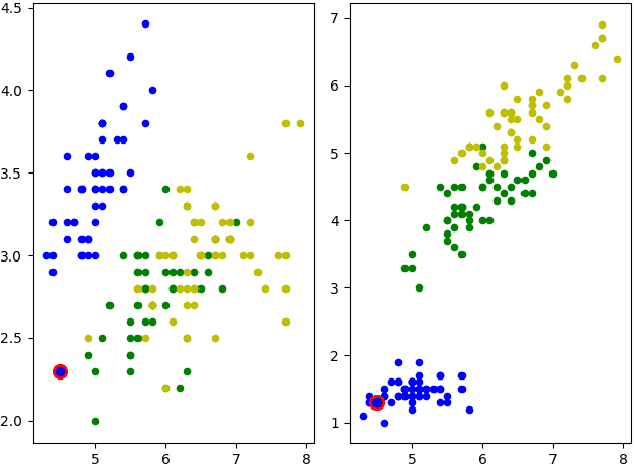
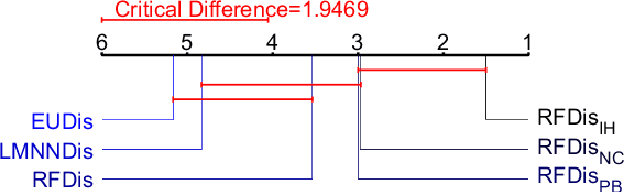
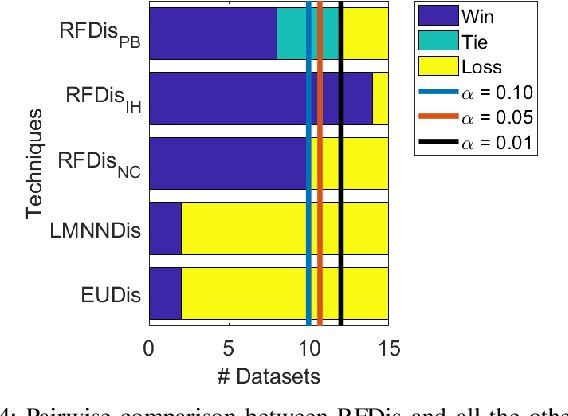
Multi-view learning is a learning task in which data is described by several concurrent representations. Its main challenge is most often to exploit the complementarities between these representations to help solve a classification/regression task. This is a challenge that can be met nowadays if there is a large amount of data available for learning. However, this is not necessarily true for all real-world problems, where data are sometimes scarce (e.g. problems related to the medical environment). In these situations, an effective strategy is to use intermediate representations based on the dissimilarities between instances. This work presents new ways of constructing these dissimilarity representations, learning them from data with Random Forest classifiers. More precisely, two methods are proposed, which modify the Random Forest proximity measure, to adapt it to the context of High Dimension Low Sample Size (HDLSS) multi-view classification problems. The second method, based on an Instance Hardness measurement, is significantly more accurate than other state-of-the-art measurements including the original RF Proximity measurement and the Large Margin Nearest Neighbor (LMNN) metric learning measurement.
Deep Learning Approaches for Image Retrieval and Pattern Spotting in Ancient Documents
Jul 22, 2019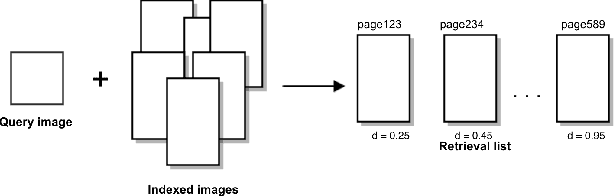
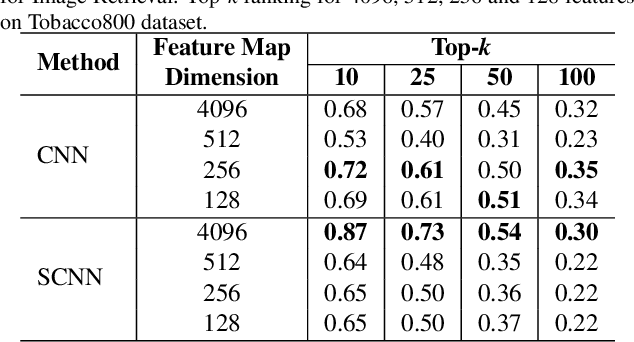
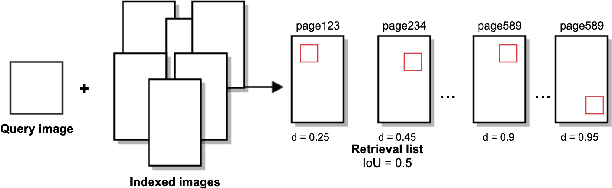
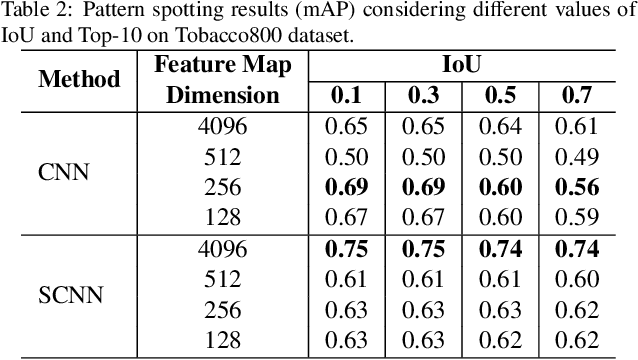
This paper describes two approaches for content-based image retrieval and pattern spotting in document images using deep learning. The first approach uses a pre-trained CNN model to cope with the lack of training data, which is fine-tuned to achieve a compact yet discriminant representation of queries and image candidates. The second approach uses a Siamese Convolution Neural Network trained on a previously prepared subset of image pairs from the ImageNet dataset to provide the similarity-based feature maps. In both methods, the learned representation scheme considers feature maps of different sizes which are evaluated in terms of retrieval performance. A robust experimental protocol using two public datasets (Tobacoo-800 and DocExplore) has shown that the proposed methods compare favorably against state-of-the-art document image retrieval and pattern spotting methods.
Image Retrieval and Pattern Spotting using Siamese Neural Network
Jun 22, 2019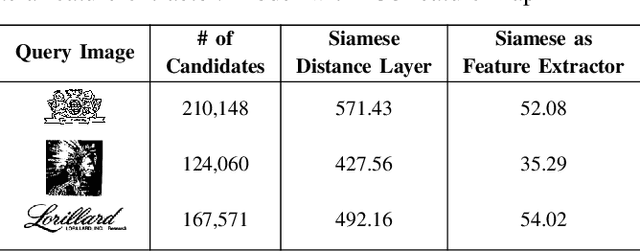
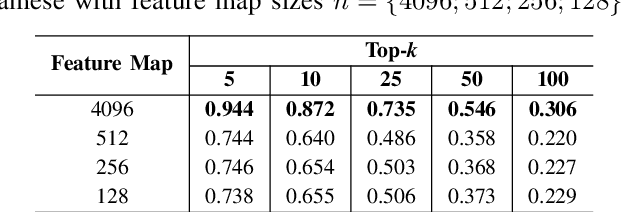
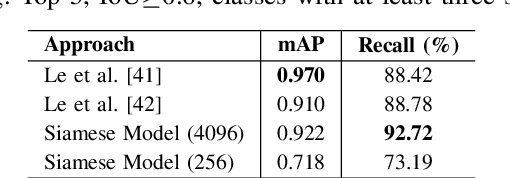

This paper presents a novel approach for image retrieval and pattern spotting in document image collections. The manual feature engineering is avoided by learning a similarity-based representation using a Siamese Neural Network trained on a previously prepared subset of image pairs from the ImageNet dataset. The learned representation is used to provide the similarity-based feature maps used to find relevant image candidates in the data collection given an image query. A robust experimental protocol based on the public Tobacco800 document image collection shows that the proposed method compares favorably against state-of-the-art document image retrieval methods, reaching 0.94 and 0.83 of mean average precision (mAP) for retrieval and pattern spotting (IoU=0.7), respectively. Besides, we have evaluated the proposed method considering feature maps of different sizes, showing the impact of reducing the number of features in the retrieval performance and time-consuming.
Pattern Spotting in Historical Documents Using Convolutional Models
Jun 20, 2019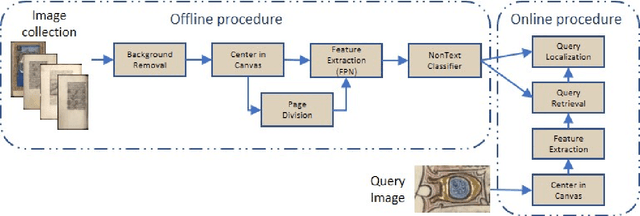
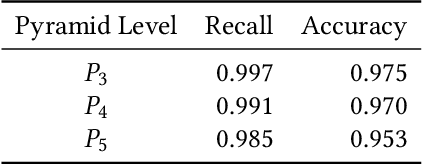


Pattern spotting consists of searching in a collection of historical document images for occurrences of a graphical object using an image query. Contrary to object detection, no prior information nor predefined class is given about the query so training a model of the object is not feasible. In this paper, a convolutional neural network approach is proposed to tackle this problem. We use RetinaNet as a feature extractor to obtain multiscale embeddings of the regions of the documents and also for the queries. Experiments conducted on the DocExplore dataset show that our proposal is better at locating patterns and requires less storage for indexing images than the state-of-the-art system, but fails at retrieving some pages containing multiple instances of the query.
Dynamic voting in multi-view learning for radiomics applications
Jun 26, 2018
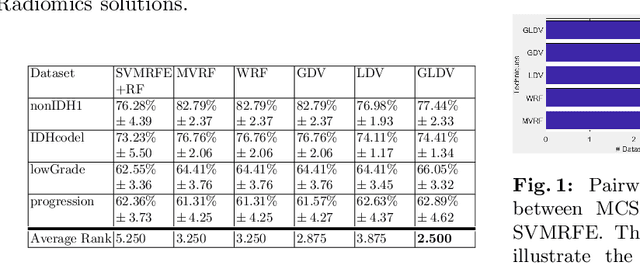
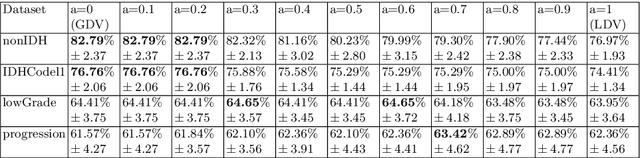
Cancer diagnosis and treatment often require a personalized analysis for each patient nowadays, due to the heterogeneity among the different types of tumor and among patients. Radiomics is a recent medical imaging field that has shown during the past few years to be promising for achieving this personalization. However, a recent study shows that most of the state-of-the-art works in Radiomics fail to identify this problem as a multi-view learning task and that multi-view learning techniques are generally more efficient. In this work, we propose to further investigate the potential of one family of multi-view learning methods based on Multiple Classifiers Systems where one classifier is learnt on each view and all classifiers are combined afterwards. In particular, we propose a random forest based dynamic weighted voting scheme, which personalizes the combination of views for each new patient for classification tasks. The proposed method is validated on several real-world Radiomics problems.