 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Train on Test Data? The Impact of Near-Duplicates on License Plate Recognition
Apr 10, 2023



This work draws attention to the large fraction of near-duplicates in the training and test sets of datasets widely adopted in License Plate Recognition (LPR) research. These duplicates refer to images that, although different, show the same license plate. Our experiments, conducted on the two most popular datasets in the field, show a substantial decrease in recognition rate when six well-known models are trained and tested under fair splits, that is, in the absence of duplicates in the training and test sets. Moreover, in one of the datasets, the ranking of models changed considerably when they were trained and tested under duplicate-free splits. These findings suggest that such duplicates have significantly biased the evaluation and development of deep learning-based models for LPR. The list of near-duplicates we have found and proposals for fair splits are publicly available for further research at https://raysonlaroca.github.io/supp/lpr-train-on-test/
Evaluation of Different Annotation Strategies for Deployment of Parking Spaces Classification Systems
Jul 22, 2022

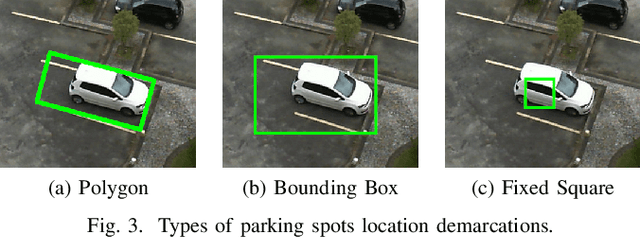
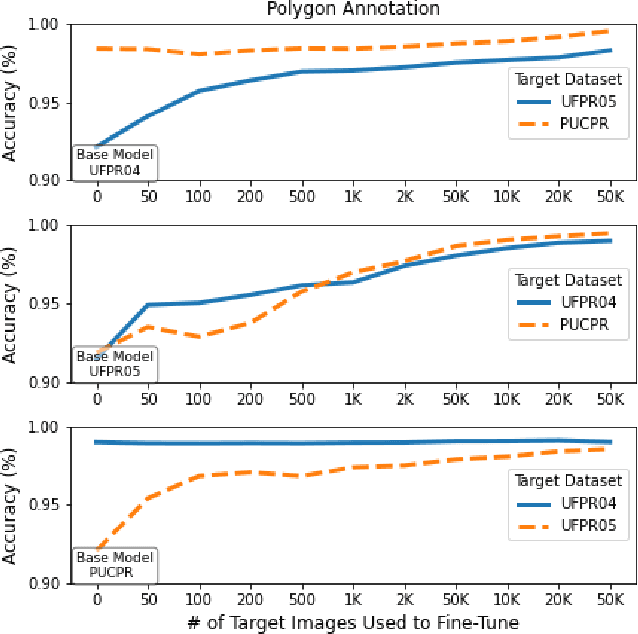
When using vision-based approaches to classify individual parking spaces between occupied and empty, human experts often need to annotate the locations and label a training set containing images collected in the target parking lot to fine-tune the system. We propose investigating three annotation types (polygons, bounding boxes, and fixed-size squares), providing different data representations of the parking spaces. The rationale is to elucidate the best trade-off between handcraft annotation precision and model performance. We also investigate the number of annotated parking spaces necessary to fine-tune a pre-trained model in the target parking lot. Experiments using the PKLot dataset show that it is possible to fine-tune a model to the target parking lot with less than 1,000 labeled samples, using low precision annotations such as fixed-size squares.
Multiscale Analysis for Improving Texture Classification
Apr 21, 2022

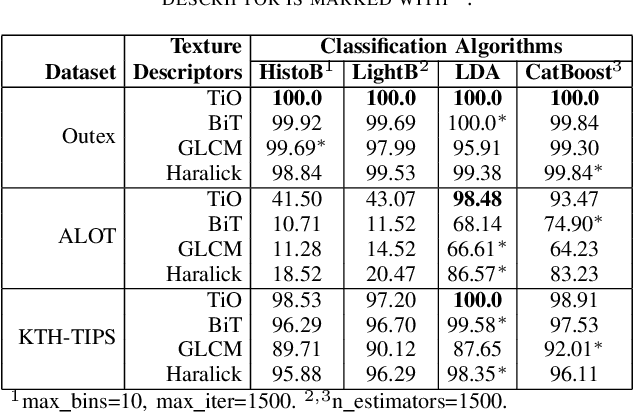

Information from an image occurs over multiple and distinct spatial scales. Image pyramid multiresolution representations are a useful data structure for image analysis and manipulation over a spectrum of spatial scales. This paper employs the Gaussian-Laplacian pyramid to treat different spatial frequency bands of a texture separately. First, we generate three images corresponding to three levels of the Gaussian-Laplacian pyramid for an input image to capture intrinsic details. Then we aggregate features extracted from gray and color texture images using bio-inspired texture descriptors, information-theoretic measures, gray-level co-occurrence matrix features, and Haralick statistical features into a single feature vector. Such an aggregation aims at producing features that characterize textures to their maximum extent, unlike employing each descriptor separately, which may lose some relevant textural information and reduce the classification performance. The experimental results on texture and histopathologic image datasets have shown the advantages of the proposed method compared to state-of-the-art approaches. Such findings emphasize the importance of multiscale image analysis and corroborate that the descriptors mentioned above are complementary.
UFPR-Periocular: A Periocular Dataset Collected by Mobile Devices in Unconstrained Scenarios
Nov 24, 2020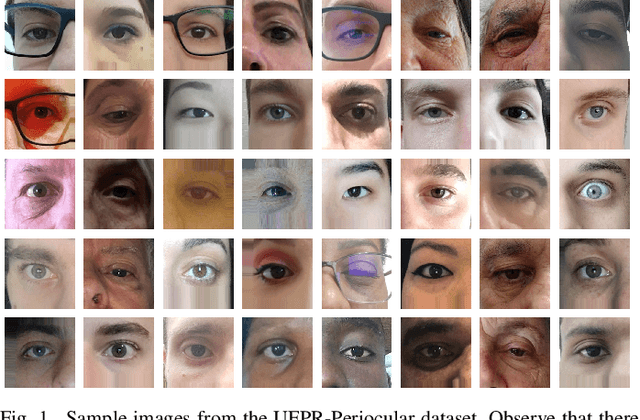
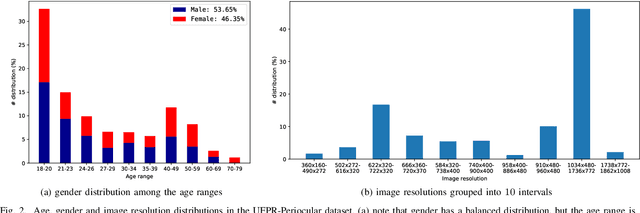
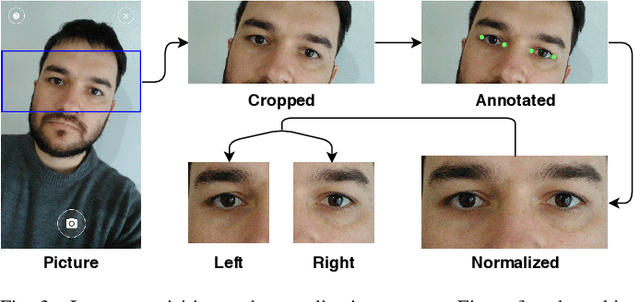
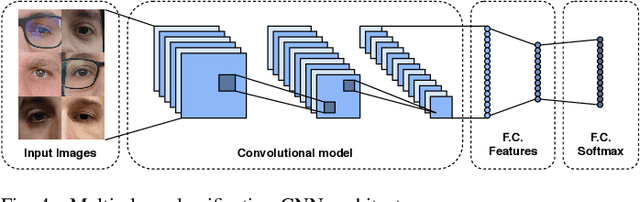
Recently, ocular biometrics in unconstrained environments using images obtained at visible wavelength have gained the researchers' attention, especially with images captured by mobile devices. Periocular recognition has been demonstrated to be an alternative when the iris trait is not available due to occlusions or low image resolution. However, the periocular trait does not have the high uniqueness presented in the iris trait. Thus, the use of datasets containing many subjects is essential to assess biometric systems' capacity to extract discriminating information from the periocular region. Also, to address the within-class variability caused by lighting and attributes in the periocular region, it is of paramount importance to use datasets with images of the same subject captured in distinct sessions. As the datasets available in the literature do not present all these factors, in this work, we present a new periocular dataset containing samples from 1,122 subjects, acquired in 3 sessions by 196 different mobile devices. The images were captured under unconstrained environments with just a single instruction to the participants: to place their eyes on a region of interest. We also performed an extensive benchmark with several Convolutional Neural Network (CNN) architectures and models that have been employed in state-of-the-art approaches based on Multi-class Classification, Multitask Learning, Pairwise Filters Network, and Siamese Network. The results achieved in the closed- and open-world protocol, considering the identification and verification tasks, show that this area still needs research and development.
A multimodal approach for multi-label movie genre classification
Jun 01, 2020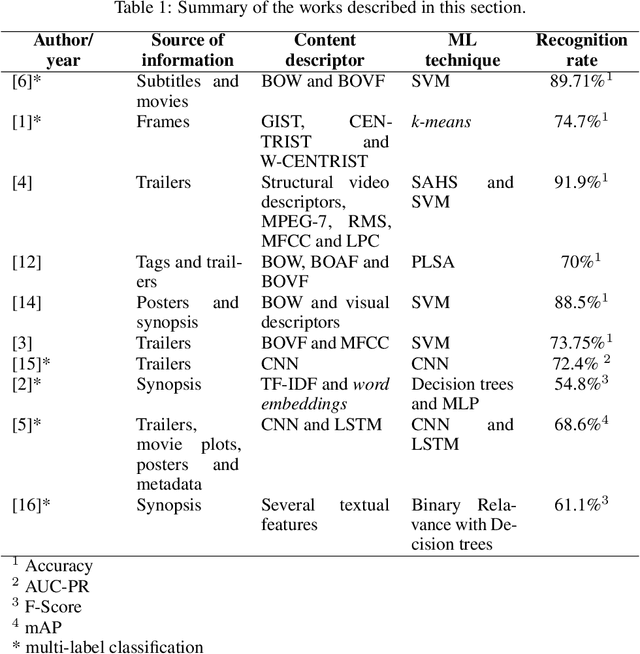

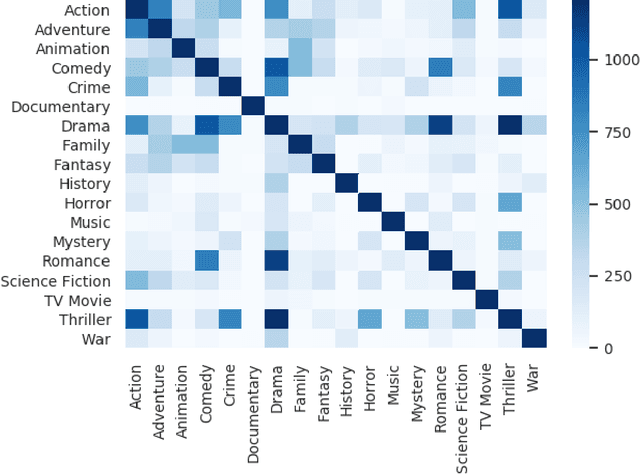
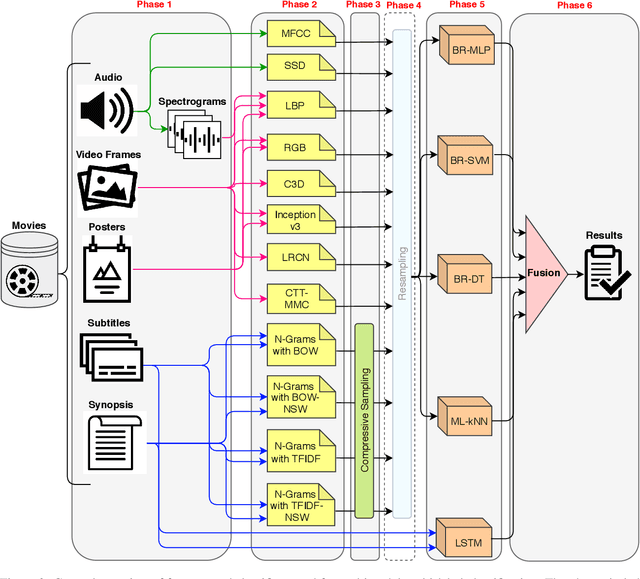
Movie genre classification is a challenging task that has increasingly attracted the attention of researchers. In this paper, we addressed the multi-label classification of the movie genres in a multimodal way. For this purpose, we created a dataset composed of trailer video clips, subtitles, synopses, and movie posters taken from 152,622 movie titles from The Movie Database. The dataset was carefully curated and organized, and it was also made available as a contribution of this work. Each movie of the dataset was labeled according to a set of eighteen genre labels. We extracted features from these data using different kinds of descriptors, namely Mel Frequency Cepstral Coefficients, Statistical Spectrum Descriptor , Local Binary Pattern with spectrograms, Long-Short Term Memory, and Convolutional Neural Networks. The descriptors were evaluated using different classifiers, such as BinaryRelevance and ML-kNN. We have also investigated the performance of the combination of different classifiers/features using a late fusion strategy, which obtained encouraging results. Based on the F-Score metric, our best result, 0.628, was obtained by the fusion of a classifier created using LSTM on the synopses, and a classifier created using CNN on movie trailer frames. When considering the AUC-PR metric, the best result, 0.673, was also achieved by combining those representations, but in addition, a classifier based on LSTM created from the subtitles was used. These results corroborate the existence of complementarity among classifiers based on different sources of information in this field of application. As far as we know, this is the most comprehensive study developed in terms of the diversity of multimedia sources of information to perform movie genre classification.
Two-View Fine-grained Classification of Plant Species
May 18, 2020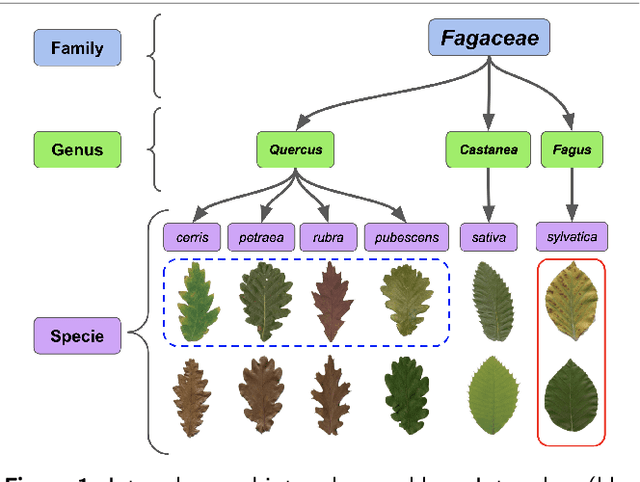
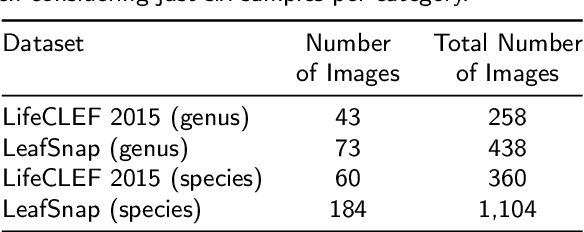
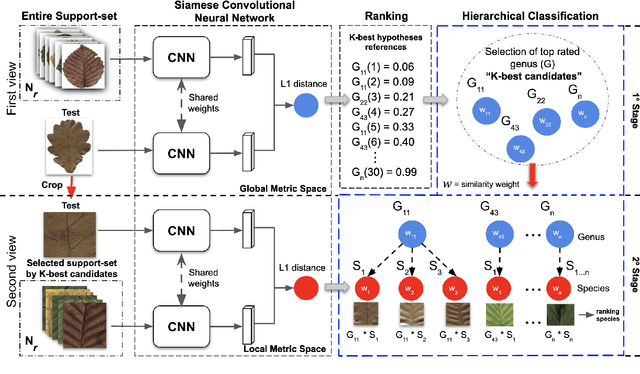
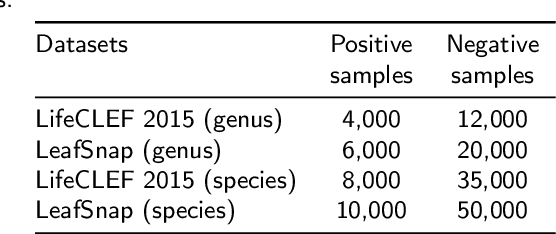
Automatic plant classification is a challenging problem due to the wide biodiversity of the existing plant species in a fine-grained scenario. Powerful deep learning architectures have been used to improve the classification performance in such a fine-grained problem, but usually building models that are highly dependent on a large training dataset and which are not scalable. In this paper, we propose a novel method based on a two-view leaf image representation and a hierarchical classification strategy for fine-grained recognition of plant species. It uses the botanical taxonomy as a basis for a coarse-to-fine strategy applied to identify the plant genus and species. The two-view representation provides complementary global and local features of leaf images. A deep metric based on Siamese convolutional neural networks is used to reduce the dependence on a large number of training samples and make the method scalable to new plant species. The experimental results on two challenging fine-grained datasets of leaf images (i.e. LifeCLEF 2015 and LeafSnap) have shown the effectiveness of the proposed method, which achieved recognition accuracy of 0.87 and 0.96 respectively.
An End-to-End Approach for Recognition of Modern and Historical Handwritten Numeral Strings
Mar 28, 2020


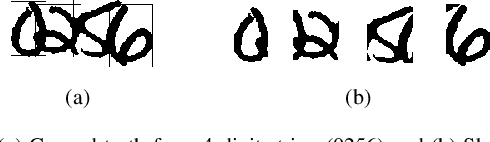
An end-to-end solution for handwritten numeral string recognition is proposed, in which the numeral string is considered as composed of objects automatically detected and recognized by a YoLo-based model. The main contribution of this paper is to avoid heuristic-based methods for string preprocessing and segmentation, the need for task-oriented classifiers, and also the use of specific constraints related to the string length. A robust experimental protocol based on several numeral string datasets, including one composed of historical documents, has shown that the proposed method is a feasible end-to-end solution for numeral string recognition. Besides, it reduces the complexity of the string recognition task considerably since it drops out classical steps, in special preprocessing, segmentation, and a set of classifiers devoted to strings with a specific length.
CNN Hyperparameter tuning applied to Iris Liveness Detection
Feb 12, 2020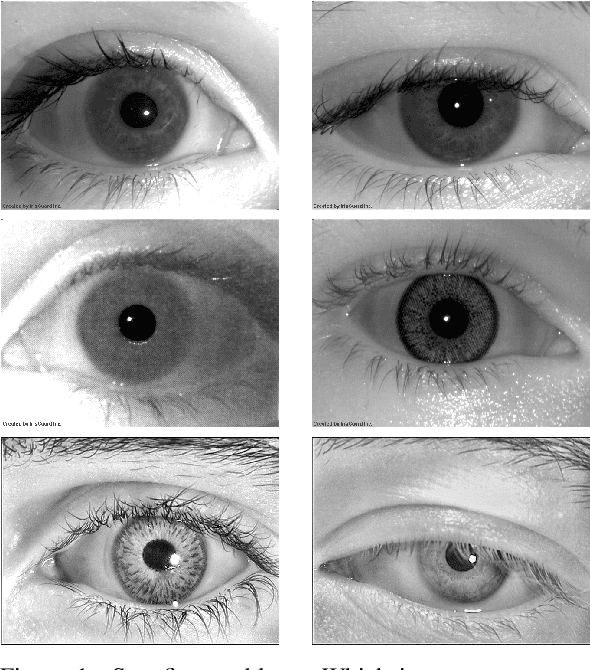

The iris pattern has significantly improved the biometric recognition field due to its high level of stability and uniqueness. Such physical feature has played an important role in security and other related areas. However, presentation attacks, also known as spoofing techniques, can be used to bypass the biometric system with artifacts such as printed images, artificial eyes, and textured contact lenses. To improve the security of these systems, many liveness detection methods have been proposed, and the first Internacional Iris Liveness Detection competition was launched in 2013 to evaluate their effectiveness. In this paper, we propose a hyperparameter tuning of the CASIA algorithm, submitted by the Chinese Academy of Sciences to the third competition of Iris Liveness Detection, in 2017. The modifications proposed promoted an overall improvement, with an 8.48% Attack Presentation Classification Error Rate (APCER) and 0.18% Bonafide Presentation Classification Error Rate (BPCER) for the evaluation of the combined datasets. Other threshold values were evaluated in an attempt to reduce the trade-off between the APCER and the BPCER on the evaluated datasets and worked out successfully.
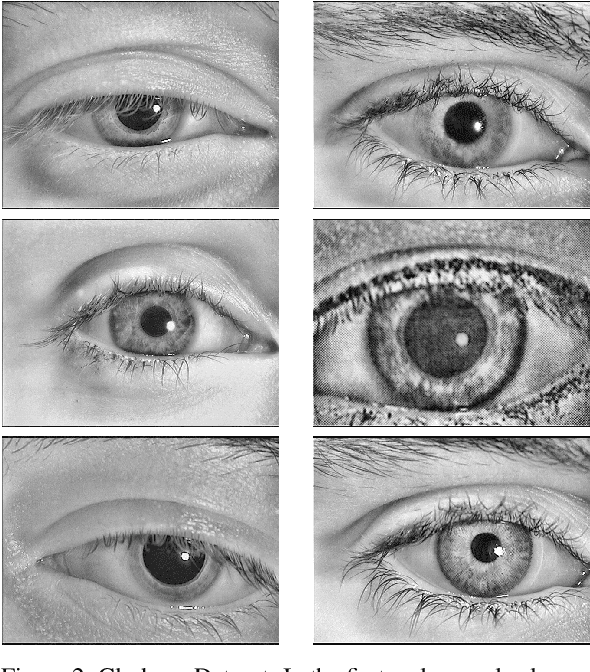
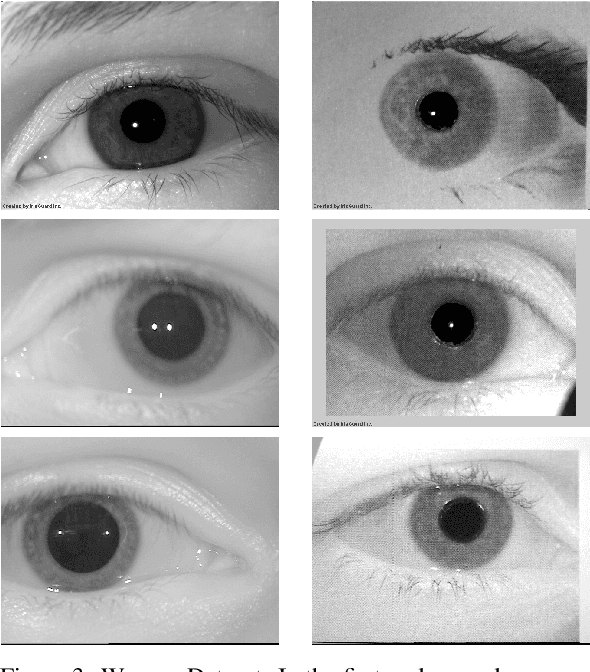
Ocular Recognition Databases and Competitions: A Survey
Nov 21, 2019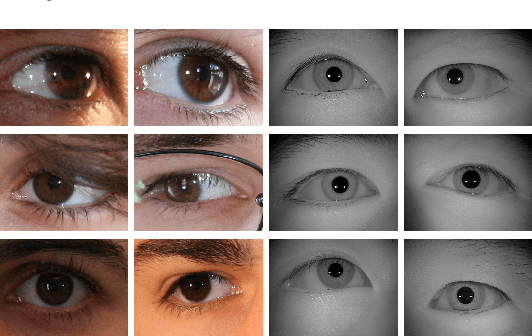
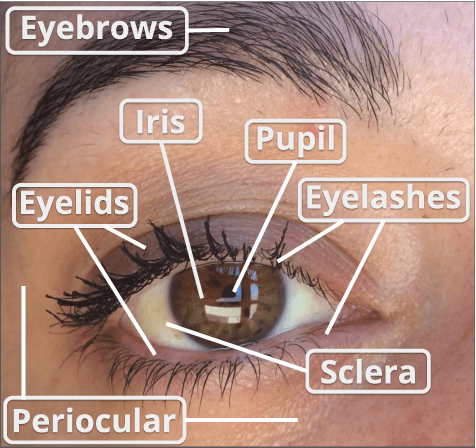
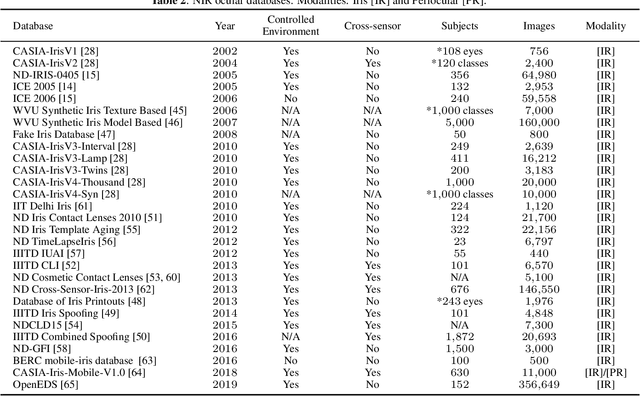
The use of the iris and periocular region as biometric traits has been extensively investigated, mainly due to the singularity of the iris features and the use of the periocular region when the image resolution is not sufficient to extract iris information. In addition to providing information about an individual's identity, features extracted from these traits can also be explored to obtain other information such as the individual's gender, the influence of drug use, the use of contact lenses, spoofing, among others. This work presents a survey of the databases created for ocular recognition, detailing their protocols and how their images were acquired. We also describe and discuss the most popular ocular recognition competitions (contests), highlighting the submitted algorithms that achieved the best results using only iris trait and also fusing iris and periocular region information. Finally, we describe some relevant works applying deep learning techniques to ocular recognition and point out new challenges and future directions. Considering that there are a large number of ocular databases, and each one is usually designed for a specific problem, we believe this survey can provide a broad overview of the challenges in ocular biometrics.
Deep Representations for Cross-spectral Ocular Biometrics
Nov 21, 2019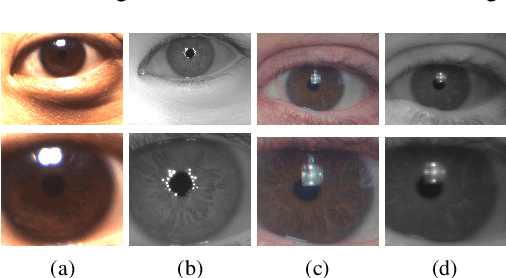


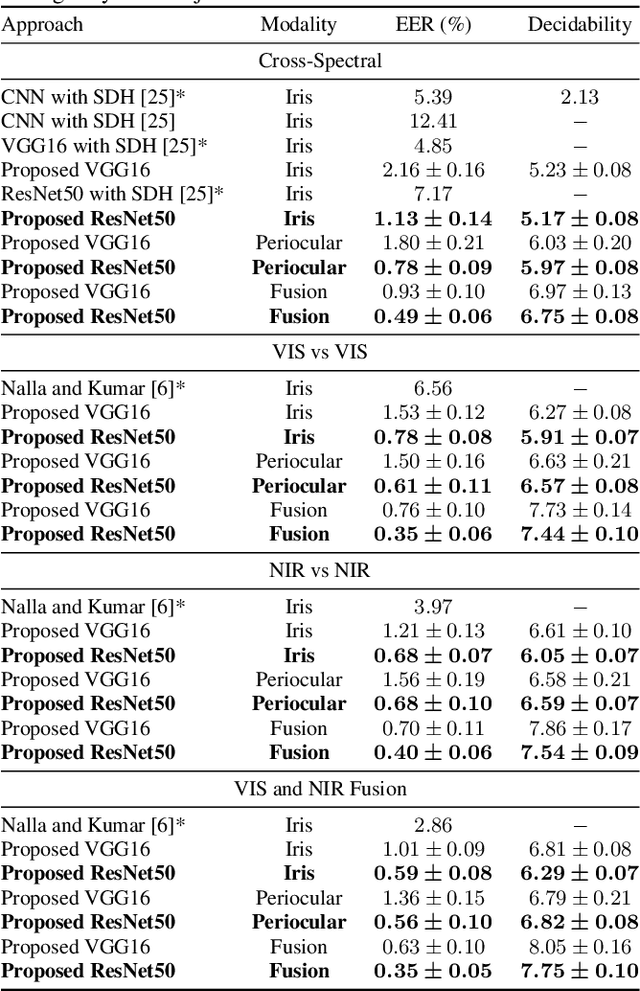
One of the major challenges in ocular biometrics is the cross-spectral scenario, i.e., how to match images acquired in different wavelengths (typically visible (VIS) against near-infrared (NIR)). This article designs and extensively evaluates cross-spectral ocular verification methods, for both the closed and open-world settings, using well known deep learning representations based on the iris and periocular regions. Using as inputs the bounding boxes of non-normalized iris/periocular regions, we fine-tune Convolutional Neural Network(CNN) models (based either on VGG16 or ResNet-50 architectures), originally trained for face recognition. Based on the experiments carried out in two publicly available cross-spectral ocular databases, we report results for intra-spectral and cross-spectral scenarios, with the best performance being observed when fusing ResNet-50 deep representations from both the periocular and iris regions. When compared to the state-of-the-art, we observed that the proposed solution consistently reduces the Equal Error Rate(EER) values by 90% / 93% / 96% and 61% / 77% / 83% on the cross-spectral scenario and in the PolyU Bi-spectral and Cross-eye-cross-spectral datasets. Lastly, we evaluate the effect that the "deepness" factor of feature representations has in recognition effectiveness, and - based on a subjective analysis of the most problematic pairwise comparisons - we point out further directions for this field of research.