 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Chronic Degenerative Diseases Identification Using Enteric Nervous System Images
Oct 31, 2020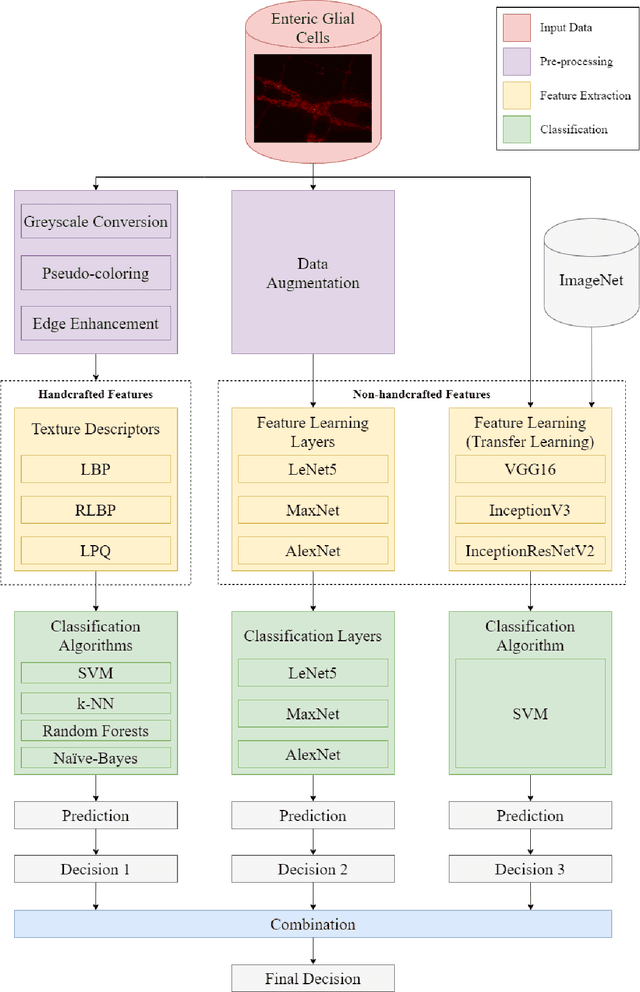

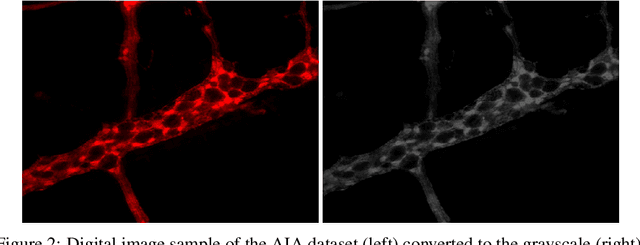
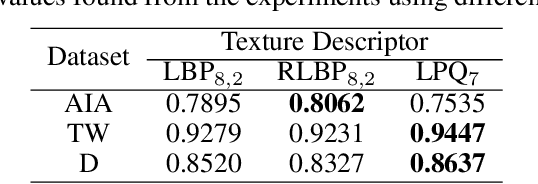
Studies recently accomplished on the Enteric Nervous System have shown that chronic degenerative diseases affect the Enteric Glial Cells (EGC) and, thus, the development of recognition methods able to identify whether or not the EGC are affected by these type of diseases may be helpful in its diagnoses. In this work, we propose the use of pattern recognition and machine learning techniques to evaluate if a given animal EGC image was obtained from a healthy individual or one affect by a chronic degenerative disease. In the proposed approach, we have performed the classification task with handcrafted features and deep learning based techniques, also known as non-handcrafted features. The handcrafted features were obtained from the textural content of the ECG images using texture descriptors, such as the Local Binary Pattern (LBP). Moreover, the representation learning techniques employed in the approach are based on different Convolutional Neural Network (CNN) architectures, such as AlexNet and VGG16, with and without transfer learning. The complementarity between the handcrafted and non-handcrafted features was also evaluated with late fusion techniques. The datasets of EGC images used in the experiments, which are also contributions of this paper, are composed of three different chronic degenerative diseases: Cancer, Diabetes Mellitus, and Rheumatoid Arthritis. The experimental results, supported by statistical analysis, shown that the proposed approach can distinguish healthy cells from the sick ones with a recognition rate of 89.30% (Rheumatoid Arthritis), 98.45% (Cancer), and 95.13% (Diabetes Mellitus), being achieved by combining classifiers obtained both feature scenarios.
Impact of lung segmentation on the diagnosis and explanation of COVID-19 in chest X-ray images
Sep 21, 2020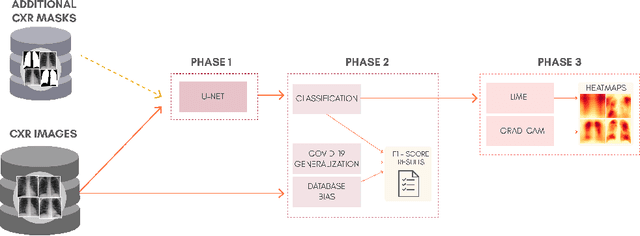
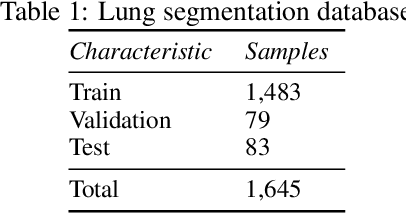
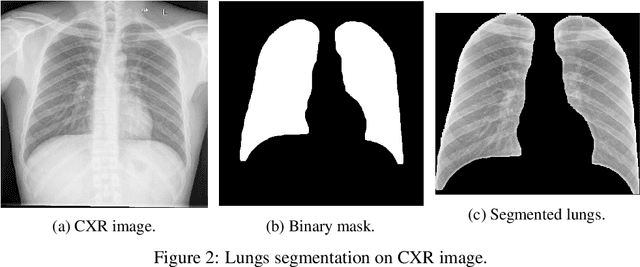
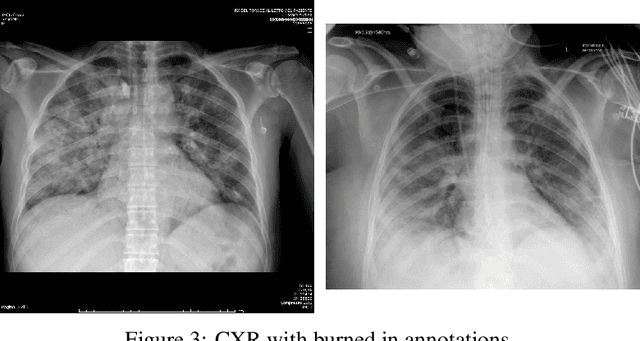
The COVID-19 pandemic is undoubtedly one of the biggest public health crises our society has ever faced. This paper's main objectives are to demonstrate the impact of lung segmentation in COVID-19 automatic identification using CXR images and evaluate which contents of the image decisively contribute to the identification. We have performed lung segmentation using a U-Net CNN architecture, and the classification using three well-known CNN architectures: VGG, ResNet, and Inception. To estimate the impact of lung segmentation, we applied some Explainable Artificial Intelligence (XAI), such as LIME and Grad-CAM. To evaluate our approach, we built a database named RYDLS-20-v2, following our previous publication and the COVIDx database guidelines. We evaluated the impact of creating a COVID-19 CXR image database from different sources, called database bias, and the COVID-19 generalization from one database to another, representing our less biased scenario. The experimental results of the segmentation achieved a Jaccard distance of 0.034 and a Dice coefficient of 0.982. In the best and more realistic scenario, we achieved an F1-Score of 0.74 and an area under the ROC curve of 0.9 for COVID-19 identification using segmented CXR images. Further testing and XAI techniques suggest that segmented CXR images represent a much more realistic and less biased performance. More importantly, the experiments conducted show that even after segmentation, there is a strong bias introduced by underlying factors from the data sources, and more efforts regarding the creation of a more significant and comprehensive database still need to be done.
A multimodal approach for multi-label movie genre classification
Jun 01, 2020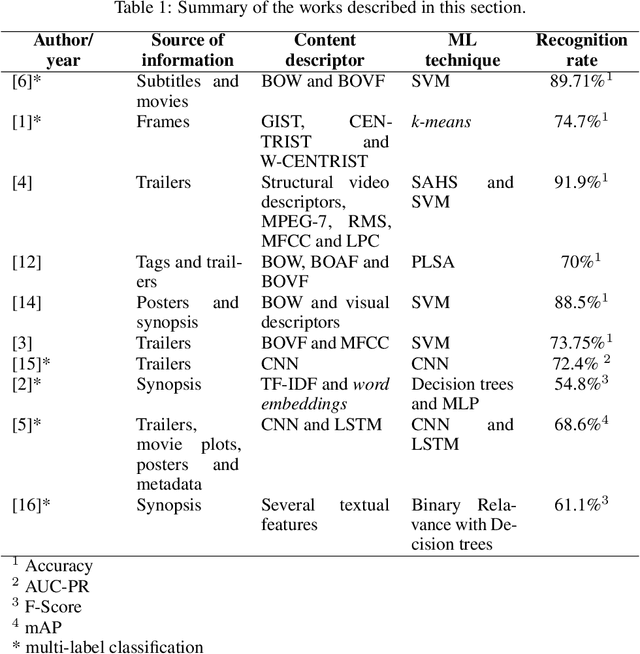

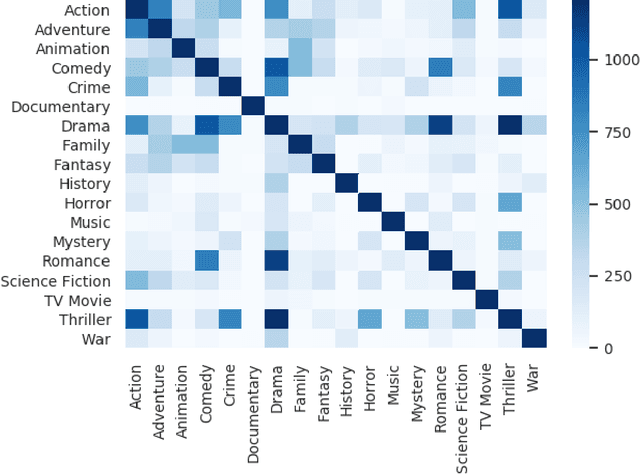
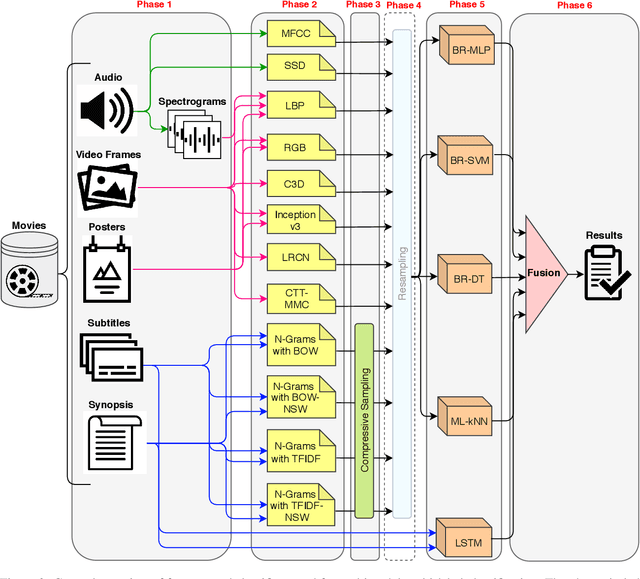
Movie genre classification is a challenging task that has increasingly attracted the attention of researchers. In this paper, we addressed the multi-label classification of the movie genres in a multimodal way. For this purpose, we created a dataset composed of trailer video clips, subtitles, synopses, and movie posters taken from 152,622 movie titles from The Movie Database. The dataset was carefully curated and organized, and it was also made available as a contribution of this work. Each movie of the dataset was labeled according to a set of eighteen genre labels. We extracted features from these data using different kinds of descriptors, namely Mel Frequency Cepstral Coefficients, Statistical Spectrum Descriptor , Local Binary Pattern with spectrograms, Long-Short Term Memory, and Convolutional Neural Networks. The descriptors were evaluated using different classifiers, such as BinaryRelevance and ML-kNN. We have also investigated the performance of the combination of different classifiers/features using a late fusion strategy, which obtained encouraging results. Based on the F-Score metric, our best result, 0.628, was obtained by the fusion of a classifier created using LSTM on the synopses, and a classifier created using CNN on movie trailer frames. When considering the AUC-PR metric, the best result, 0.673, was also achieved by combining those representations, but in addition, a classifier based on LSTM created from the subtitles was used. These results corroborate the existence of complementarity among classifiers based on different sources of information in this field of application. As far as we know, this is the most comprehensive study developed in terms of the diversity of multimedia sources of information to perform movie genre classification.
Single-sample writers -- "Document Filter" and their impacts on writer identification
May 18, 2020



The writing can be used as an important biometric modality which allows to unequivocally identify an individual. It happens because the writing of two different persons present differences that can be explored both in terms of graphometric properties or even by addressing the manuscript as a digital image, taking into account the use of image processing techniques that can properly capture different visual attributes of the image (e.g. texture). In this work, perform a detailed study in which we dissect whether or not the use of a database with only a single sample taken from some writers may skew the results obtained in the experimental protocol. In this sense, we propose here what we call "document filter". The "document filter" protocol is supposed to be used as a preprocessing technique, such a way that all the data taken from fragments of the same document must be placed either into the training or into the test set. The rationale behind it, is that the classifier must capture the features from the writer itself, and not features regarding other particularities which could affect the writing in a specific document (i.e. emotional state of the writer, pen used, paper type, and etc.). By analyzing the literature, one can find several works dealing the writer identification problem. However, the performance of the writer identification systems must be evaluated also taking into account the occurrence of writer volunteers who contributed with a single sample during the creation of the manuscript databases. To address the open issue investigated here, a comprehensive set of experiments was performed on the IAM, BFL and CVL databases. They have shown that, in the most extreme case, the recognition rate obtained using the "document filter" protocol drops from 81.80% to 50.37%.
COVID-19 identification in chest X-ray images on flat and hierarchical classification scenarios
May 06, 2020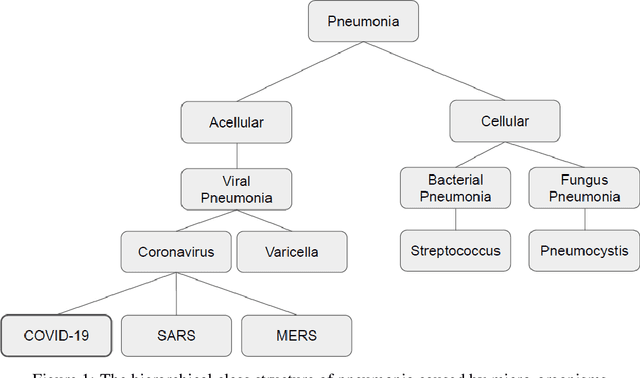

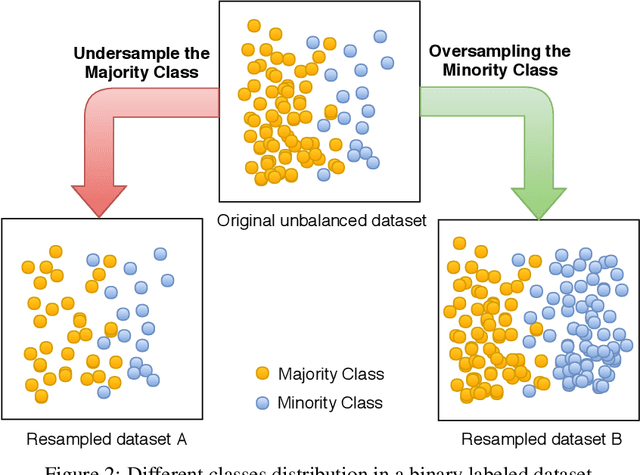
The COVID-19 can cause severe pneumonia and is estimated to have a high impact on the healthcare system. The standard image diagnosis tests for pneumonia are chest X-ray (CXR) and computed tomography (CT) scan. CXR are useful in because it is cheaper, faster and more widespread than CT. This study aims to identify pneumonia caused by COVID-19 from other types and also healthy lungs using only CXR images. In order to achieve the objectives, we have proposed a classification schema considering the multi-class and hierarchical perspectives, since pneumonia can be structured as a hierarchy. Given the natural data imbalance in this domain, we also proposed the use of resampling algorithms in order to re-balance the classes distribution. Our classification schema extract features using some well-known texture descriptors and also using a pre-trained CNN model. We also explored early and late fusion techniques in order to leverage the strength of multiple texture descriptors and base classifiers at once. To evaluate the approach, we composed a database, named RYDLS-20, containing CXR images of pneumonia caused by different pathogens as well as CXR images of healthy lungs. The classes distribution follows a real-world scenario in which some pathogens are more common than others. The proposed approach achieved a macro-avg F1-Score of 0.65 using a multi-class approach and a F1-Score of 0.89 for the COVID-19 identification in the hierarchical classification scenario. As far as we know, we achieved the best nominal rate obtained for COVID-19 identification in an unbalanced environment with more than three classes. We must also highlight the novel proposed hierarchical classification approach for this task, which considers the types of pneumonia caused by the different pathogens and lead us to the best COVID-19 recognition rate obtained here.