 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier Pool Generation based on a Two-level Diversity Approach
Nov 03, 2020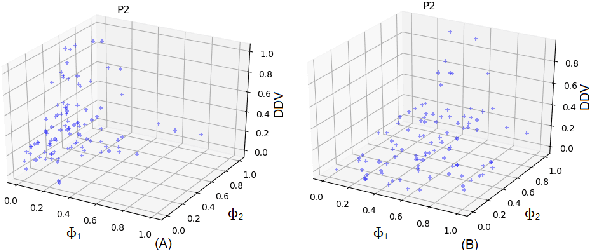
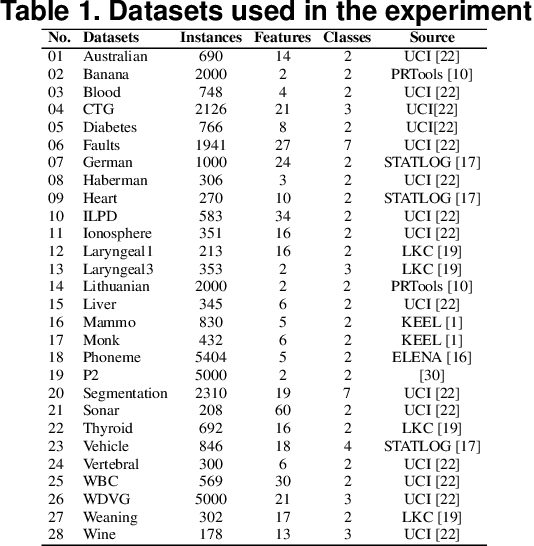
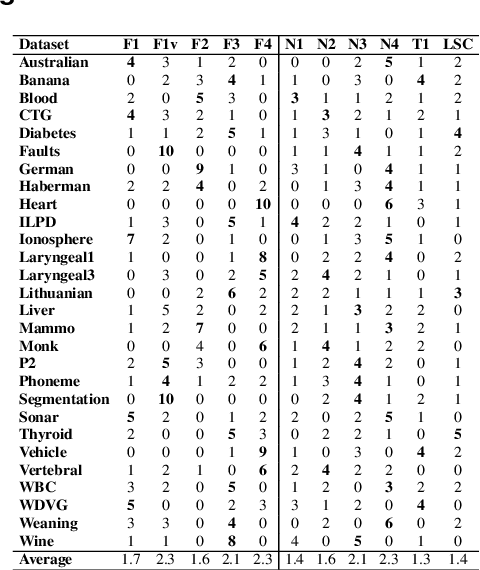
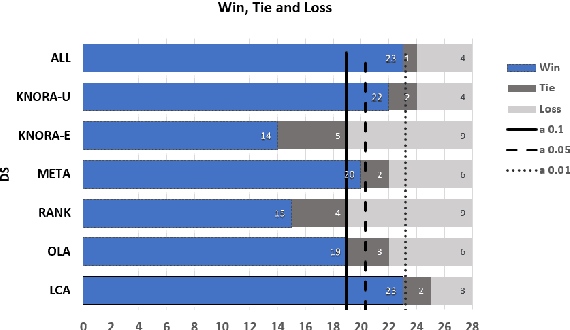
This paper describes a classifier pool generation method guided by the diversity estimated on the data complexity and classifier decisions. First, the behavior of complexity measures is assessed by considering several subsamples of the dataset. The complexity measures with high variability across the subsamples are selected for posterior pool adaptation, where an evolutionary algorithm optimizes diversity in both complexity and decision spaces. A robust experimental protocol with 28 datasets and 20 replications is used to evaluate the proposed method. Results show significant accuracy improvements in 69.4% of the experiments when Dynamic Classifier Selection and Dynamic Ensemble Selection methods are applied.
A Comprehensive Comparison of End-to-End Approaches for Handwritten Digit String Recognition
Oct 29, 2020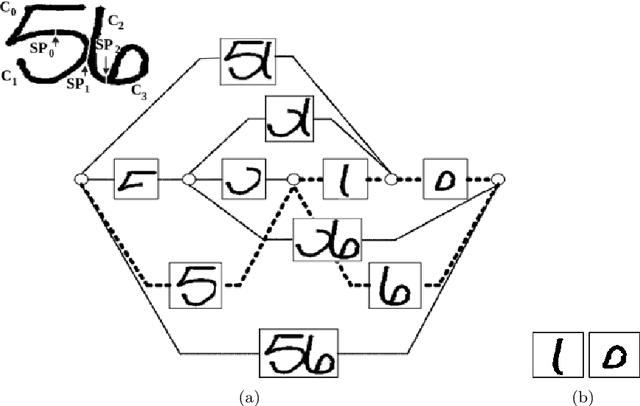
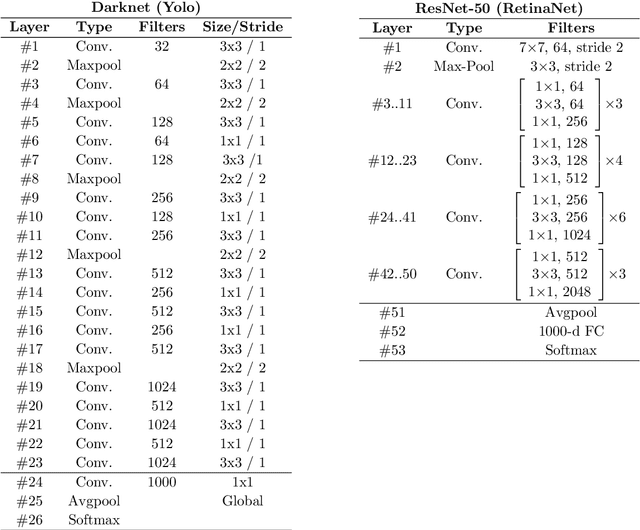
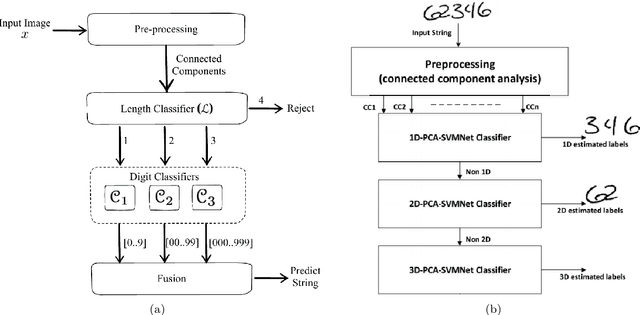
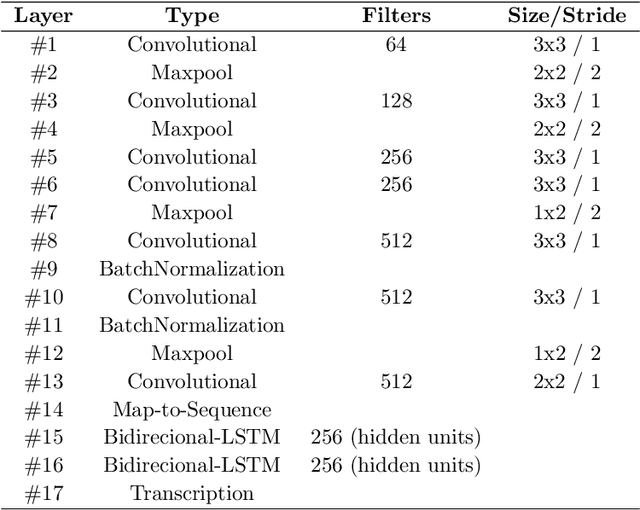
Over the last decades, most approaches proposed for handwritten digit string recognition (HDSR) have resorted to digit segmentation, which is dominated by heuristics, thereby imposing substantial constraints on the final performance. Few of them have been based on segmentation-free strategies where each pixel column has a potential cut location. Recently, segmentation-free strategies has added another perspective to the problem, leading to promising results. However, these strategies still show some limitations when dealing with a large number of touching digits. To bridge the resulting gap, in this paper, we hypothesize that a string of digits can be approached as a sequence of objects. We thus evaluate different end-to-end approaches to solve the HDSR problem, particularly in two verticals: those based on object-detection (e.g., Yolo and RetinaNet) and those based on sequence-to-sequence representation (CRNN). The main contribution of this work lies in its provision of a comprehensive comparison with a critical analysis of the above mentioned strategies on five benchmarks commonly used to assess HDSR, including the challenging Touching Pair dataset, NIST SD19, and two real-world datasets (CAR and CVL) proposed for the ICFHR 2014 competition on HDSR. Our results show that the Yolo model compares favorably against segmentation-free models with the advantage of having a shorter pipeline that minimizes the presence of heuristics-based models. It achieved a 97%, 96%, and 84% recognition rate on the NIST-SD19, CAR, and CVL datasets, respectively.
Intrapersonal Parameter Optimization for Offline Handwritten Signature Augmentation
Oct 13, 2020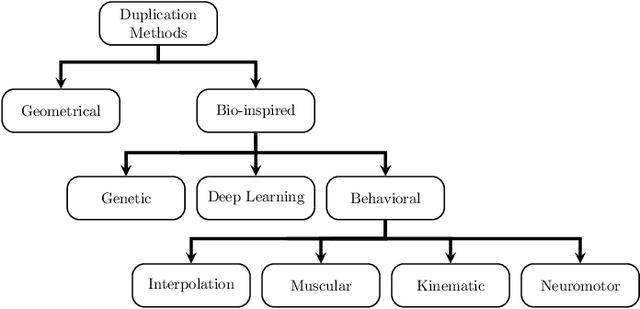
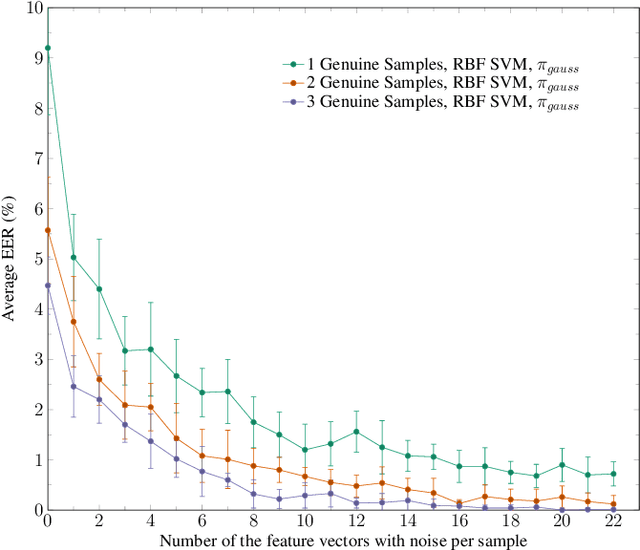
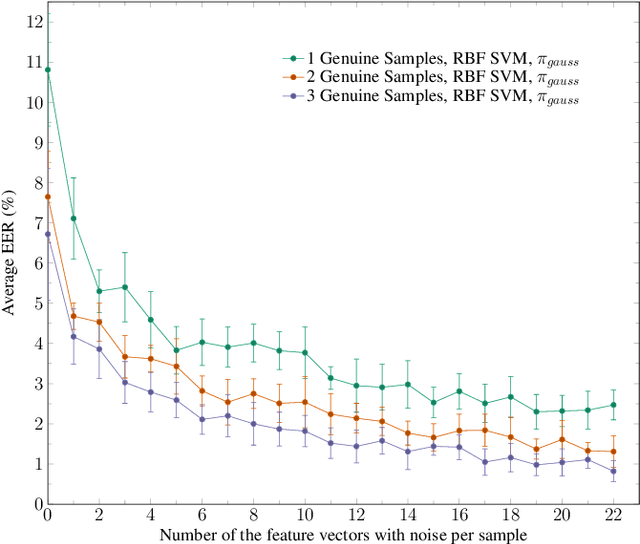
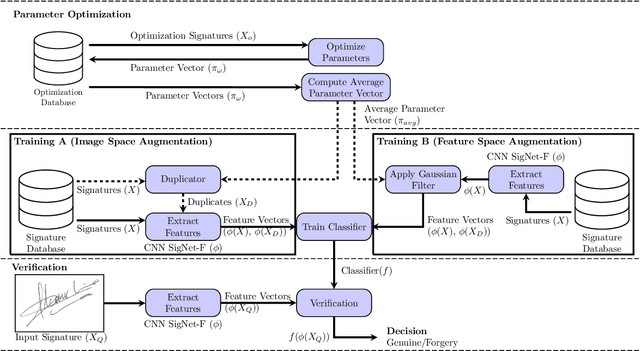
Usually, in a real-world scenario, few signature samples are available to train an automatic signature verification system (ASVS). However, such systems do indeed need a lot of signatures to achieve an acceptable performance. Neuromotor signature duplication methods and feature space augmentation methods may be used to meet the need for an increase in the number of samples. Such techniques manually or empirically define a set of parameters to introduce a degree of writer variability. Therefore, in the present study, a method to automatically model the most common writer variability traits is proposed. The method is used to generate offline signatures in the image and the feature space and train an ASVS. We also introduce an alternative approach to evaluate the quality of samples considering their feature vectors. We evaluated the performance of an ASVS with the generated samples using three well-known offline signature datasets: GPDS, MCYT-75, and CEDAR. In GPDS-300, when the SVM classifier was trained using one genuine signature per writer and the duplicates generated in the image space, the Equal Error Rate (EER) decreased from 5.71% to 1.08%. Under the same conditions, the EER decreased to 1.04% using the feature space augmentation technique. We also verified that the model that generates duplicates in the image space reproduces the most common writer variability traits in the three different datasets.
Single-sample writers -- "Document Filter" and their impacts on writer identification
May 18, 2020



The writing can be used as an important biometric modality which allows to unequivocally identify an individual. It happens because the writing of two different persons present differences that can be explored both in terms of graphometric properties or even by addressing the manuscript as a digital image, taking into account the use of image processing techniques that can properly capture different visual attributes of the image (e.g. texture). In this work, perform a detailed study in which we dissect whether or not the use of a database with only a single sample taken from some writers may skew the results obtained in the experimental protocol. In this sense, we propose here what we call "document filter". The "document filter" protocol is supposed to be used as a preprocessing technique, such a way that all the data taken from fragments of the same document must be placed either into the training or into the test set. The rationale behind it, is that the classifier must capture the features from the writer itself, and not features regarding other particularities which could affect the writing in a specific document (i.e. emotional state of the writer, pen used, paper type, and etc.). By analyzing the literature, one can find several works dealing the writer identification problem. However, the performance of the writer identification systems must be evaluated also taking into account the occurrence of writer volunteers who contributed with a single sample during the creation of the manuscript databases. To address the open issue investigated here, a comprehensive set of experiments was performed on the IAM, BFL and CVL databases. They have shown that, in the most extreme case, the recognition rate obtained using the "document filter" protocol drops from 81.80% to 50.37%.
Style Transfer Applied to Face Liveness Detection with User-Centered Models
Jul 16, 2019

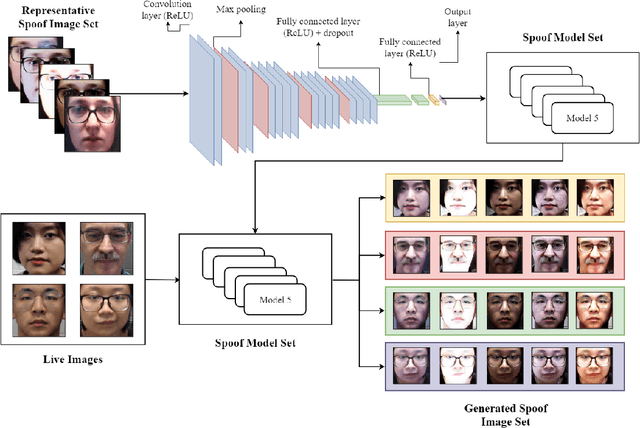
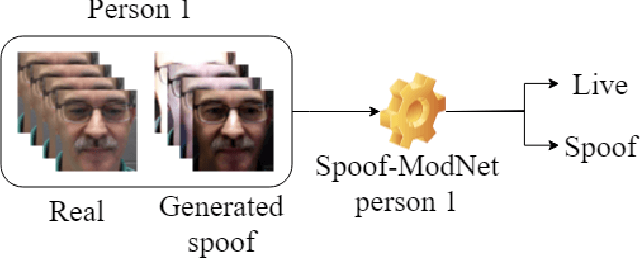
This paper proposes a face anti-spoofing user-centered model (FAS-UCM). The major difficulty, in this case, is obtaining fraudulent images from all users to train the models. To overcome this problem, the proposed method is divided in three main parts: generation of new spoof images, based on style transfer and spoof image representation models; training of a Convolutional Neural Network (CNN) for liveness detection; evaluation of the live and spoof testing images for each subject. The generalization of the CNN to perform style transfer has shown promising qualitative results. Preliminary results have shown that the proposed method is capable of distinguishing between live and spoof images on the SiW database, with an average classification error rate of 0.22.
A Classifier-free Ensemble Selection Method based on Data Diversity in Random Subspaces
Aug 13, 2014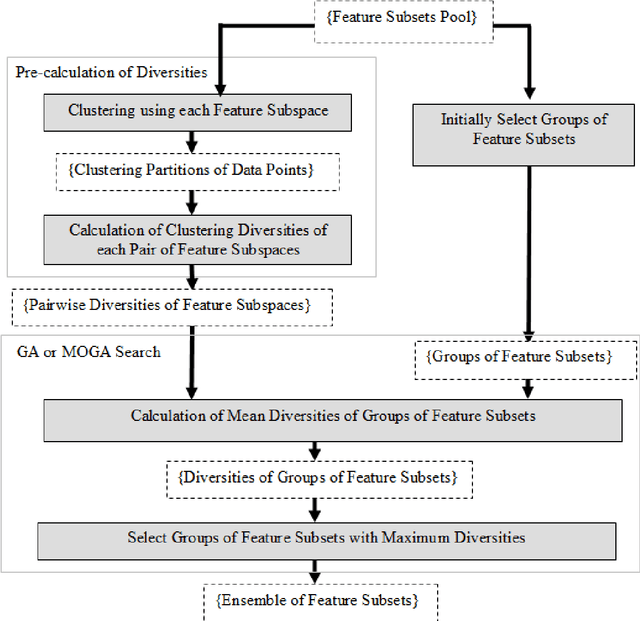

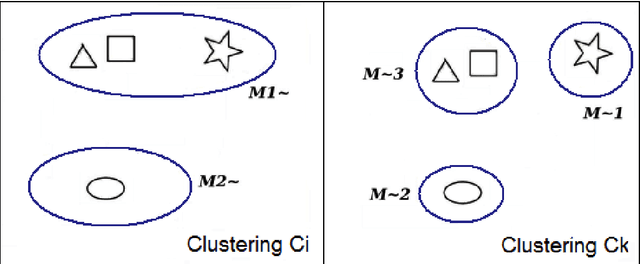

The Ensemble of Classifiers (EoC) has been shown to be effective in improving the performance of single classifiers by combining their outputs, and one of the most important properties involved in the selection of the best EoC from a pool of classifiers is considered to be classifier diversity. In general, classifier diversity does not occur randomly, but is generated systematically by various ensemble creation methods. By using diverse data subsets to train classifiers, these methods can create diverse classifiers for the EoC. In this work, we propose a scheme to measure data diversity directly from random subspaces, and explore the possibility of using it to select the best data subsets for the construction of the EoC. Our scheme is the first ensemble selection method to be presented in the literature based on the concept of data diversity. Its main advantage over the traditional framework (ensemble creation then selection) is that it obviates the need for classifier training prior to ensemble selection. A single Genetic Algorithm (GA) and a Multi-Objective Genetic Algorithm (MOGA) were evaluated to search for the best solutions for the classifier-free ensemble selection. In both cases, objective functions based on different clustering diversity measures were implemented and tested. All the results obtained with the proposed classifier-free ensemble selection method were compared with the traditional classifier-based ensemble selection using Mean Classifier Error (ME) and Majority Voting Error (MVE). The applicability of the method is tested on UCI machine learning problems and NIST SD19 handwritten numerals.