 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmarking Methodology to Assess Open-Source Video Large Language Models in Automatic Captioning of News Videos
Mar 29, 2026News videos are among the most prevalent content types produced by television stations and online streaming platforms, yet generating textual descriptions to facilitate indexing and retrieval largely remains a manual process. Video Large Language Models (VidLLMs) offer significant potential to automate this task, but a comprehensive evaluation in the news domain is still lacking. This work presents a comparative study of eight state-of-the-art open-source VidLLMs for automatic news video captioning, evaluated on two complementary benchmark datasets: a Chilean TV news corpus (approximately 1,345 clips) and a BBC News corpus (9,838 clips). We employ lexical metrics (METEOR, ROUGE-L), semantic metrics (BERTScore, CLIPScore, Text Similarity, Mean Reciprocal Rank), and two novel fidelity metrics proposed in this work: the Thematic Fidelity Score (TFS) and Entity Fidelity Score (EFS). Our analysis reveals that standard metrics exhibit limited discriminative power for news video captioning due to surface-form dependence, static-frame insensitivity, and function-word inflation. TFS and EFS address these gaps by directly assessing thematic structure preservation and named-entity coverage in the generated captions. Results show that Gemma~3 achieves the highest overall performance across both datasets and most evaluation dimensions, with Qwen-VL as a consistent runner-up.
Leveraging Unlabeled Data for Sketch-based Understanding
Apr 26, 2022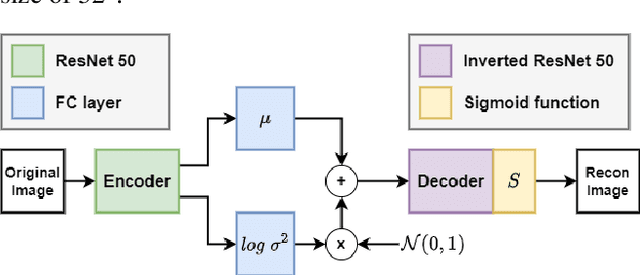
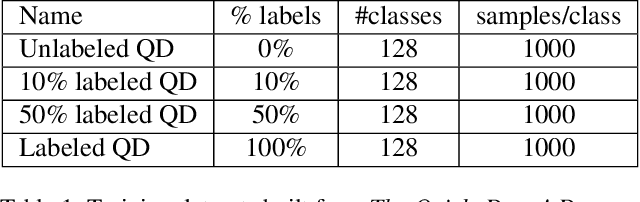
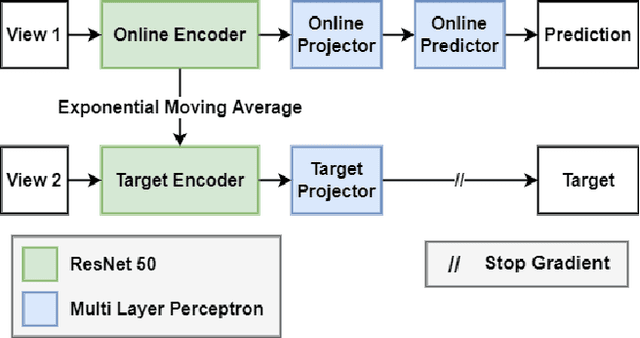
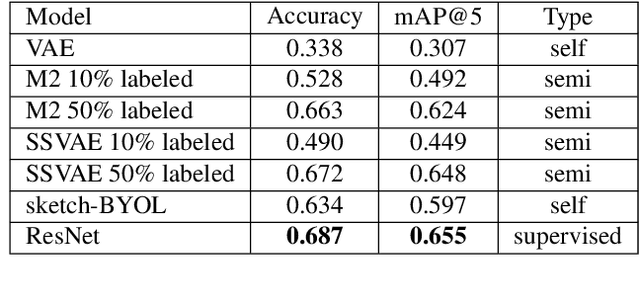
Sketch-based understanding is a critical component of human cognitive learning and is a primitive communication means between humans. This topic has recently attracted the interest of the computer vision community as sketching represents a powerful tool to express static objects and dynamic scenes. Unfortunately, despite its broad application domains, the current sketch-based models strongly rely on labels for supervised training, ignoring knowledge from unlabeled data, thus limiting the underlying generalization and the applicability. Therefore, we present a study about the use of unlabeled data to improve a sketch-based model. To this end, we evaluate variations of VAE and semi-supervised VAE, and present an extension of BYOL to deal with sketches. Our results show the superiority of sketch-BYOL, which outperforms other self-supervised approaches increasing the retrieval performance for known and unknown categories. Furthermore, we show how other tasks can benefit from our proposal.
Sketch-QNet: A Quadruplet ConvNet for Color Sketch-based Image Retrieval
Apr 22, 2021
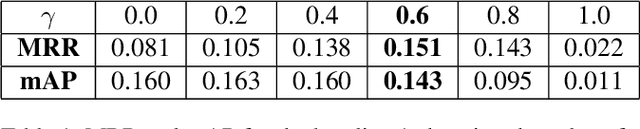
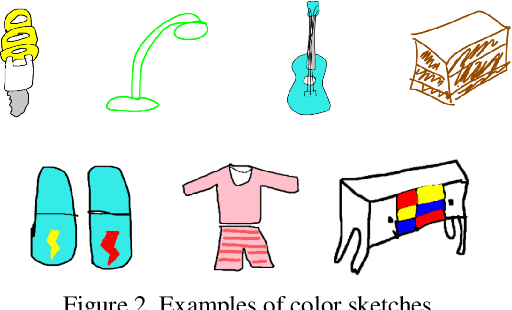
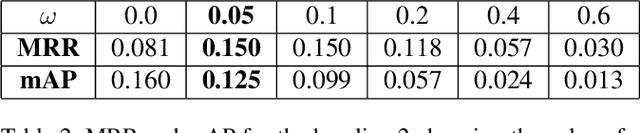
Architectures based on siamese networks with triplet loss have shown outstanding performance on the image-based similarity search problem. This approach attempts to discriminate between positive (relevant) and negative (irrelevant) items. However, it undergoes a critical weakness. Given a query, it cannot discriminate weakly relevant items, for instance, items of the same type but different color or texture as the given query, which could be a serious limitation for many real-world search applications. Therefore, in this work, we present a quadruplet-based architecture that overcomes the aforementioned weakness. Moreover, we present an instance of this quadruplet network, which we call Sketch-QNet, to deal with the color sketch-based image retrieval (CSBIR) problem, achieving new state-of-the-art results.
Compact and Effective Representations for Sketch-based Image Retrieval
Apr 20, 2021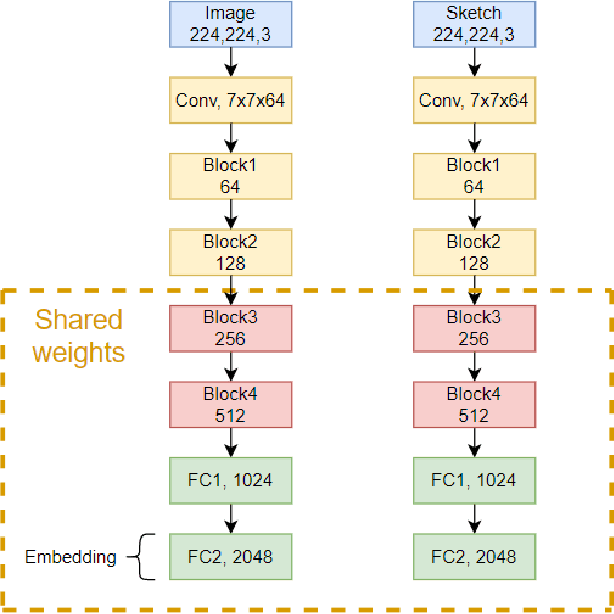
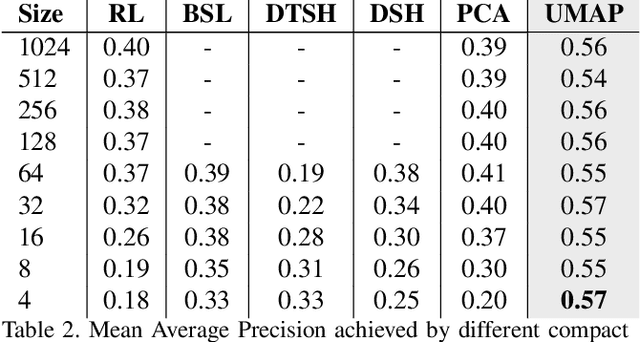

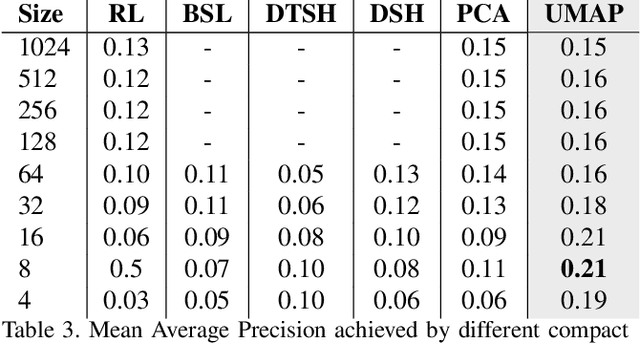
Sketch-based image retrieval (SBIR) has undergone an increasing interest in the community of computer vision bringing high impact in real applications. For instance, SBIR brings an increased benefit to eCommerce search engines because it allows users to formulate a query just by drawing what they need to buy. However, current methods showing high precision in retrieval work in a high dimensional space, which negatively affects aspects like memory consumption and time processing. Although some authors have also proposed compact representations, these drastically degrade the performance in a low dimension. Therefore in this work, we present different results of evaluating methods for producing compact embeddings in the context of sketch-based image retrieval. Our main interest is in strategies aiming to keep the local structure of the original space. The recent unsupervised local-topology preserving dimension reduction method UMAP fits our requirements and shows outstanding performance, improving even the precision achieved by SOTA methods. We evaluate six methods in two different datasets. We use Flickr15K and eCommerce datasets; the latter is another contribution of this work. We show that UMAP allows us to have feature vectors of 16 bytes improving precision by more than 35%.
Scalable Visual Attribute Extraction through Hidden Layers of a Residual ConvNet
Mar 31, 2021
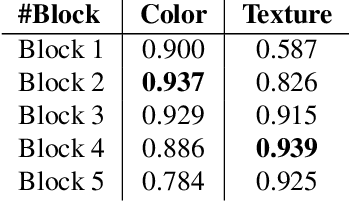


Visual attributes play an essential role in real applications based on image retrieval. For instance, the extraction of attributes from images allows an eCommerce search engine to produce retrieval results with higher precision. The traditional manner to build an attribute extractor is by training a convnet-based classifier with a fixed number of classes. However, this approach does not scale for real applications where the number of attributes changes frequently. Therefore in this work, we propose an approach for extracting visual attributes from images, leveraging the learned capability of the hidden layers of a general convolutional network to discriminate among different visual features. We run experiments with a resnet-50 trained on Imagenet, on which we evaluate the output of its different blocks to discriminate between colors and textures. Our results show that the second block of the resnet is appropriate for discriminating colors, while the fourth block can be used for textures. In both cases, the achieved accuracy of attribute classification is superior to 93%. We also show that the proposed embeddings form local structures in the underlying feature space, which makes it possible to apply reduction techniques like UMAP, maintaining high accuracy and widely reducing the size of the feature space.
A Comprehensive Comparison of End-to-End Approaches for Handwritten Digit String Recognition
Oct 29, 2020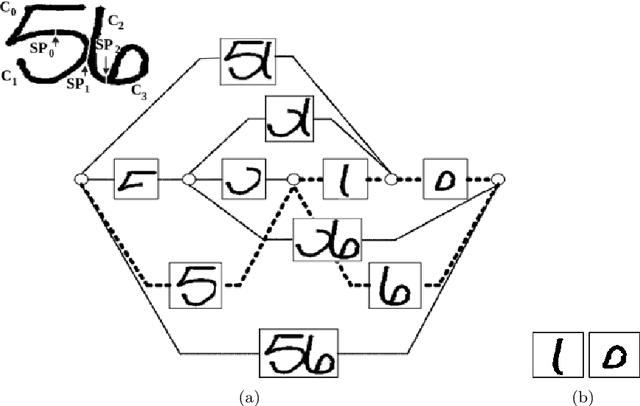
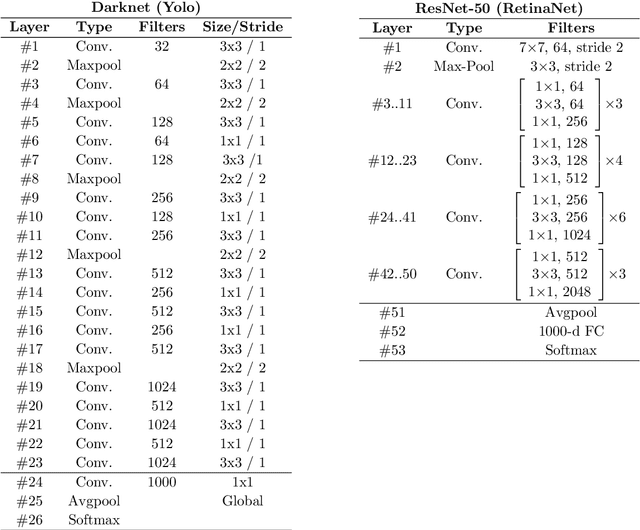
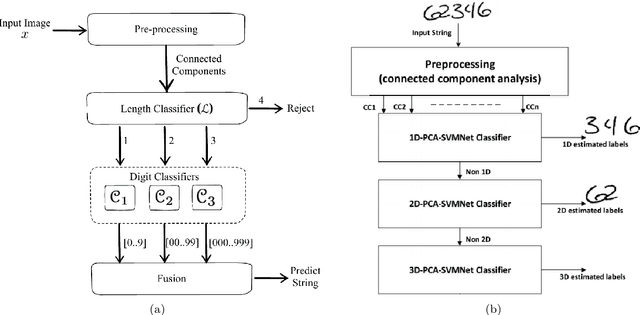
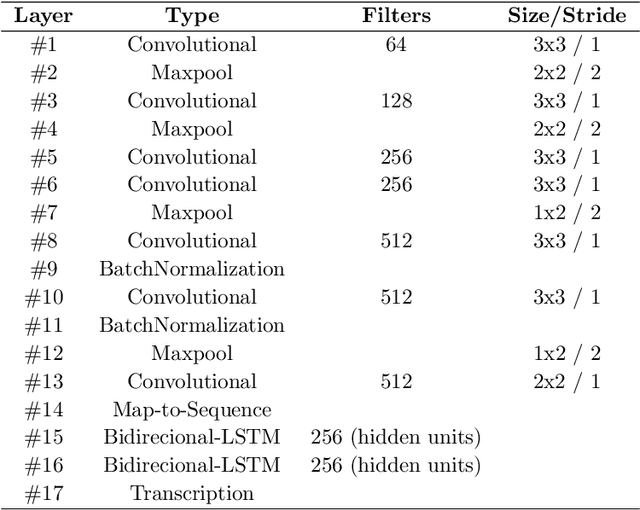
Over the last decades, most approaches proposed for handwritten digit string recognition (HDSR) have resorted to digit segmentation, which is dominated by heuristics, thereby imposing substantial constraints on the final performance. Few of them have been based on segmentation-free strategies where each pixel column has a potential cut location. Recently, segmentation-free strategies has added another perspective to the problem, leading to promising results. However, these strategies still show some limitations when dealing with a large number of touching digits. To bridge the resulting gap, in this paper, we hypothesize that a string of digits can be approached as a sequence of objects. We thus evaluate different end-to-end approaches to solve the HDSR problem, particularly in two verticals: those based on object-detection (e.g., Yolo and RetinaNet) and those based on sequence-to-sequence representation (CRNN). The main contribution of this work lies in its provision of a comprehensive comparison with a critical analysis of the above mentioned strategies on five benchmarks commonly used to assess HDSR, including the challenging Touching Pair dataset, NIST SD19, and two real-world datasets (CAR and CVL) proposed for the ICFHR 2014 competition on HDSR. Our results show that the Yolo model compares favorably against segmentation-free models with the advantage of having a shorter pipeline that minimizes the presence of heuristics-based models. It achieved a 97%, 96%, and 84% recognition rate on the NIST-SD19, CAR, and CVL datasets, respectively.
Pattern Spotting in Historical Documents Using Convolutional Models
Jun 20, 2019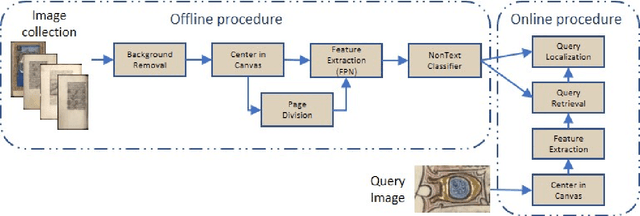
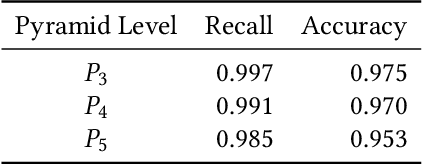


Pattern spotting consists of searching in a collection of historical document images for occurrences of a graphical object using an image query. Contrary to object detection, no prior information nor predefined class is given about the query so training a model of the object is not feasible. In this paper, a convolutional neural network approach is proposed to tackle this problem. We use RetinaNet as a feature extractor to obtain multiscale embeddings of the regions of the documents and also for the queries. Experiments conducted on the DocExplore dataset show that our proposal is better at locating patterns and requires less storage for indexing images than the state-of-the-art system, but fails at retrieving some pages containing multiple instances of the query.