 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern Spotting in Historical Documents Using Convolutional Models
Jun 20, 2019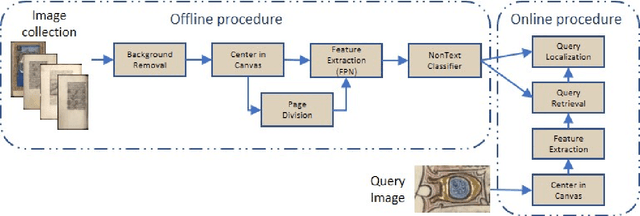
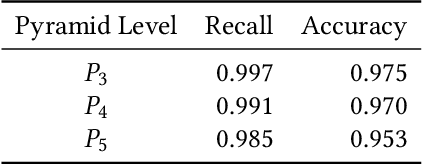


Pattern spotting consists of searching in a collection of historical document images for occurrences of a graphical object using an image query. Contrary to object detection, no prior information nor predefined class is given about the query so training a model of the object is not feasible. In this paper, a convolutional neural network approach is proposed to tackle this problem. We use RetinaNet as a feature extractor to obtain multiscale embeddings of the regions of the documents and also for the queries. Experiments conducted on the DocExplore dataset show that our proposal is better at locating patterns and requires less storage for indexing images than the state-of-the-art system, but fails at retrieving some pages containing multiple instances of the query.
Logical segmentation for article extraction in digitized old newspapers
Oct 03, 2012
Newspapers are documents made of news item and informative articles. They are not meant to be red iteratively: the reader can pick his items in any order he fancies. Ignoring this structural property, most digitized newspaper archives only offer access by issue or at best by page to their content. We have built a digitization workflow that automatically extracts newspaper articles from images, which allows indexing and retrieval of information at the article level. Our back-end system extracts the logical structure of the page to produce the informative units: the articles. Each image is labelled at the pixel level, through a machine learning based method, then the page logical structure is constructed up from there by the detection of structuring entities such as horizontal and vertical separators, titles and text lines. This logical structure is stored in a METS wrapper associated to the ALTO file produced by the system including the OCRed text. Our front-end system provides a web high definition visualisation of images, textual indexing and retrieval facilities, searching and reading at the article level. Articles transcriptions can be collaboratively corrected, which as a consequence allows for better indexing. We are currently testing our system on the archives of the Journal de Rouen, one of France eldest local newspaper. These 250 years of publication amount to 300 000 pages of very variable image quality and layout complexity. Test year 1808 can be consulted at plair.univ-rouen.fr.