 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark of State-Space Models vs. Transformers and BiLSTM-based Models for Historical Newspaper OCR
Apr 01, 2026End-to-end OCR for historical newspapers remains challenging, as models must handle long text sequences, degraded print quality, and complex layouts. While Transformer-based recognizers dominate current research, their quadratic complexity limits efficient paragraph-level transcription and large-scale deployment. We investigate linear-time State-Space Models (SSMs), specifically Mamba, as a scalable alternative to Transformer-based sequence modeling for OCR. We present to our knowledge, the first OCR architecture based on SSMs, combining a CNN visual encoder with bi-directional and autoregressive Mamba sequence modeling, and conduct a large-scale benchmark comparing SSMs with Transformer- and BiLSTM-based recognizers. Multiple decoding strategies (CTC, autoregressive, and non-autoregressive) are evaluated under identical training conditions alongside strong neural baselines (VAN, DAN, DANIEL) and widely used off-the-shelf OCR engines (PERO-OCR, Tesseract OCR, TrOCR, Gemini). Experiments on historical newspapers from the Bibliothèque nationale du Luxembourg, with newly released >99% verified gold-standard annotations, and cross-dataset tests on Fraktur and Antiqua lines, show that all neural models achieve low error rates (~2% CER), making computational efficiency the main differentiator. Mamba-based models maintain competitive accuracy while halving inference time and exhibiting superior memory scaling (1.26x vs 2.30x growth at 1000 chars), reaching 6.07% CER at the severely degraded paragraph level compared to 5.24% for DAN, while remaining 2.05x faster. We release code, trained models, and standardized evaluation protocols to enable reproducible research and guide practitioners in large-scale cultural heritage OCR.
Few-shot Writer Adaptation via Multimodal In-Context Learning
Mar 31, 2026While state-of-the-art Handwritten Text Recognition (HTR) models perform well on standard benchmarks, they frequently struggle with writers exhibiting highly specific styles that are underrepresented in the training data. To handle unseen and atypical writers, writer adaptation techniques personalize HTR models to individual handwriting styles. Leading writer adaptation methods require either offline fine-tuning or parameter updates at inference time, both involving gradient computation and backpropagation, which increase computational costs and demand careful hyperparameter tuning. In this work, we propose a novel context-driven HTR framework3 inspired by multimodal in-context learning, enabling inference-time writer adaptation using only a few examples from the target writer without any parameter updates. We further demonstrate the impact of context length, design a compact 8M-parameter CNN-Transformer that enables few-shot in-context adaptation, and show that combining context-driven and standard OCR training strategies leads to complementary improvements. Experiments on IAM and RIMES validate our approach with Character Error Rates of 3.92% and 2.34%, respectively, surpassing all writer-independent HTR models without requiring any parameter updates at inference time.
Classifying the Unknown: In-Context Learning for Open-Vocabulary Text and Symbol Recognition
Apr 09, 2025We introduce Rosetta, a multimodal model that leverages Multimodal In-Context Learning (MICL) to classify sequences of novel script patterns in documents by leveraging minimal examples, thus eliminating the need for explicit retraining. To enhance contextual learning, we designed a dataset generation process that ensures varying degrees of contextual informativeness, improving the model's adaptability in leveraging context across different scenarios. A key strength of our method is the use of a Context-Aware Tokenizer (CAT), which enables open-vocabulary classification. This allows the model to classify text and symbol patterns across an unlimited range of classes, extending its classification capabilities beyond the scope of its training alphabet of patterns. As a result, it unlocks applications such as the recognition of new alphabets and languages. Experiments on synthetic datasets demonstrate the potential of Rosetta to successfully classify Out-Of-Distribution visual patterns and diverse sets of alphabets and scripts, including but not limited to Chinese, Greek, Russian, French, Spanish, and Japanese.
DANIEL: A fast Document Attention Network for Information Extraction and Labelling of handwritten documents
Jul 12, 2024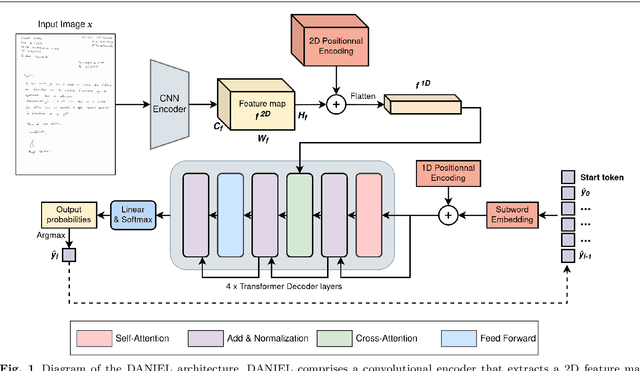
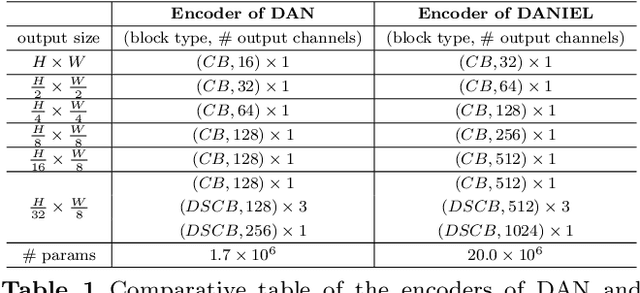

Information extraction from handwritten documents involves traditionally three distinct steps: Document Layout Analysis, Handwritten Text Recognition, and Named Entity Recognition. Recent approaches have attempted to integrate these steps into a single process using fully end-to-end architectures. Despite this, these integrated approaches have not yet matched the performance of language models, when applied to information extraction in plain text. In this paper, we introduce DANIEL (Document Attention Network for Information Extraction and Labelling), a fully end-to-end architecture integrating a language model and designed for comprehensive handwritten document understanding. DANIEL performs layout recognition, handwriting recognition, and named entity recognition on full-page documents. Moreover, it can simultaneously learn across multiple languages, layouts, and tasks. For named entity recognition, the ontology to be applied can be specified via the input prompt. The architecture employs a convolutional encoder capable of processing images of any size without resizing, paired with an autoregressive decoder based on a transformer-based language model. DANIEL achieves competitive results on four datasets, including a new state-of-the-art performance on RIMES 2009 and M-POPP for Handwriting Text Recognition, and IAM NER for Named Entity Recognition. Furthermore, DANIEL is much faster than existing approaches. We provide the source code and the weights of the trained models at \url{https://github.com/Shulk97/daniel}.
End-to-end information extraction in handwritten documents: Understanding Paris marriage records from 1880 to 1940
Apr 30, 2024
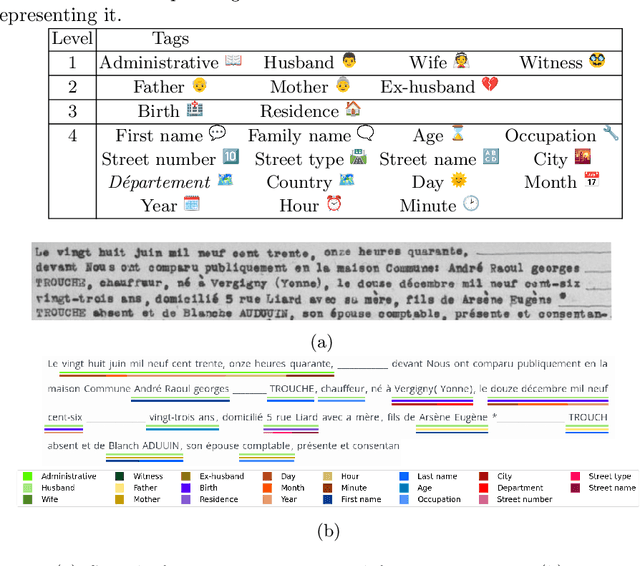


The EXO-POPP project aims to establish a comprehensive database comprising 300,000 marriage records from Paris and its suburbs, spanning the years 1880 to 1940, which are preserved in over 130,000 scans of double pages. Each marriage record may encompass up to 118 distinct types of information that require extraction from plain text. In this paper, we introduce the M-POPP dataset, a subset of the M-POPP database with annotations for full-page text recognition and information extraction in both handwritten and printed documents, and which is now publicly available. We present a fully end-to-end architecture adapted from the DAN, designed to perform both handwritten text recognition and information extraction directly from page images without the need for explicit segmentation. We showcase the information extraction capabilities of this architecture by achieving a new state of the art for full-page Information Extraction on Esposalles and we use this architecture as a baseline for the M-POPP dataset. We also assess and compare how different encoding strategies for named entities in the text affect the performance of jointly recognizing handwritten text and extracting information, from full pages.
Logical segmentation for article extraction in digitized old newspapers
Oct 03, 2012
Newspapers are documents made of news item and informative articles. They are not meant to be red iteratively: the reader can pick his items in any order he fancies. Ignoring this structural property, most digitized newspaper archives only offer access by issue or at best by page to their content. We have built a digitization workflow that automatically extracts newspaper articles from images, which allows indexing and retrieval of information at the article level. Our back-end system extracts the logical structure of the page to produce the informative units: the articles. Each image is labelled at the pixel level, through a machine learning based method, then the page logical structure is constructed up from there by the detection of structuring entities such as horizontal and vertical separators, titles and text lines. This logical structure is stored in a METS wrapper associated to the ALTO file produced by the system including the OCRed text. Our front-end system provides a web high definition visualisation of images, textual indexing and retrieval facilities, searching and reading at the article level. Articles transcriptions can be collaboratively corrected, which as a consequence allows for better indexing. We are currently testing our system on the archives of the Journal de Rouen, one of France eldest local newspaper. These 250 years of publication amount to 300 000 pages of very variable image quality and layout complexity. Test year 1808 can be consulted at plair.univ-rouen.fr.
A multiagent urban traffic simulation
Jan 26, 2012
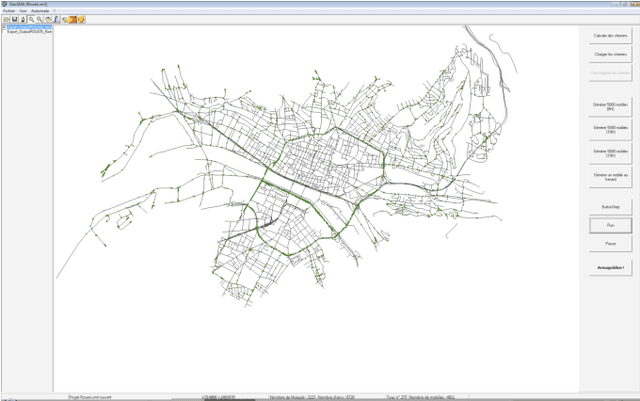
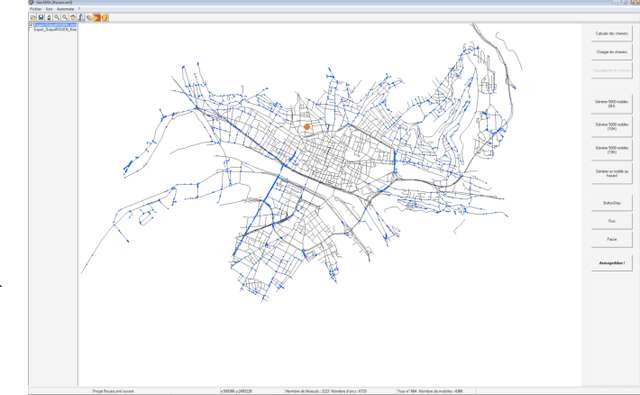
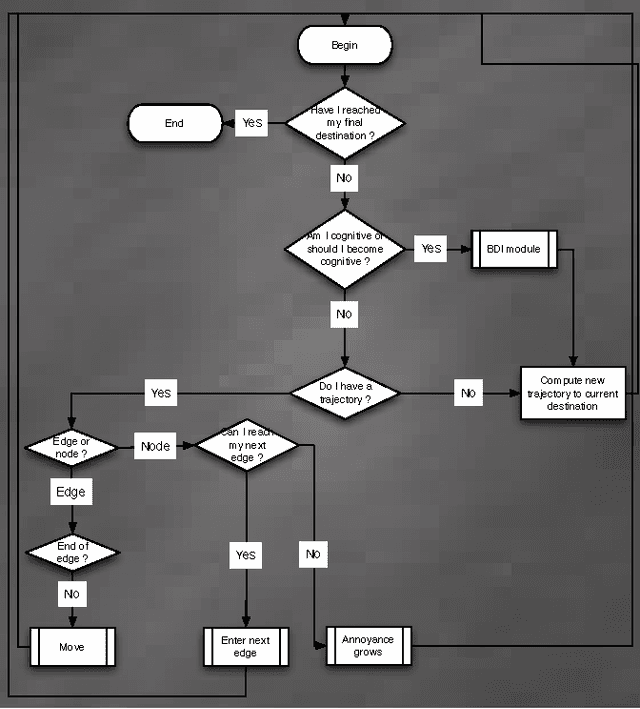
We built a multiagent simulation of urban traffic to model both ordinary traffic and emergency or crisis mode traffic. This simulation first builds a modeled road network based on detailed geographical information. On this network, the simulation creates two populations of agents: the Transporters and the Mobiles. Transporters embody the roads themselves; they are utilitarian and meant to handle the low level realism of the simulation. Mobile agents embody the vehicles that circulate on the network. They have one or several destinations they try to reach using initially their beliefs of the structure of the network (length of the edges, speed limits, number of lanes etc.). Nonetheless, when confronted to a dynamic, emergent prone environment (other vehicles, unexpectedly closed ways or lanes, traffic jams etc.), the rather reactive agent will activate more cognitive modules to adapt its beliefs, desires and intentions. It may change its destination(s), change the tactics used to reach the destination (favoring less used roads, following other agents, using general headings), etc. We describe our current validation of our model and the next planned improvements, both in validation and in functionalities.
* arXiv admin note: significant text overlap with arXiv:0909.1021 and arXiv:0910.1026
Different goals in multiscale simulations and how to reach them
Nov 09, 2009
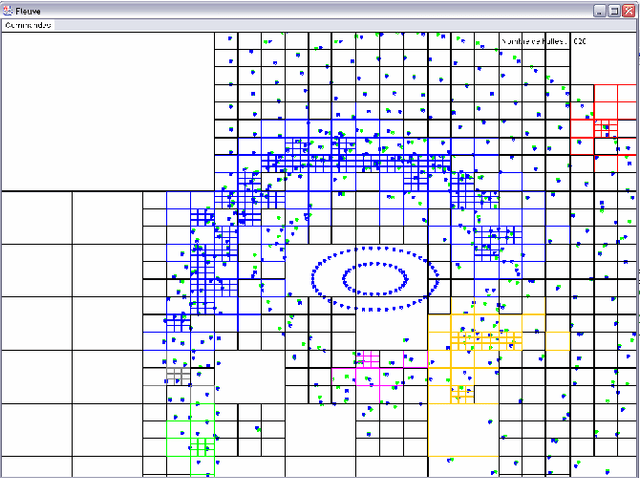
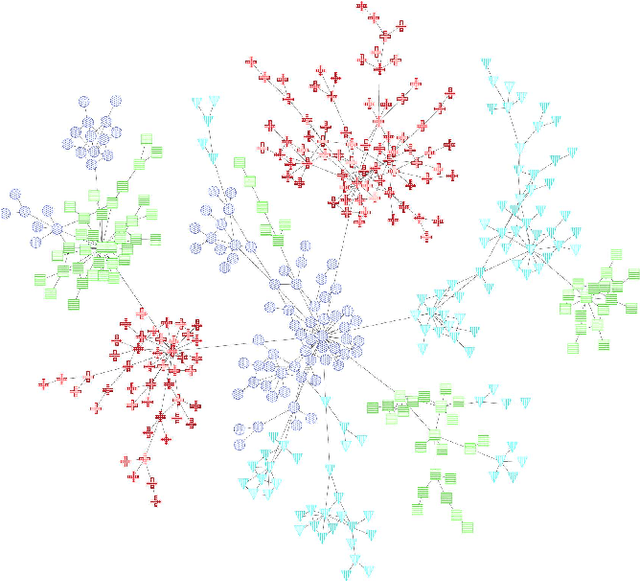

In this paper we sum up our works on multiscale programs, mainly simulations. We first start with describing what multiscaling is about, how it helps perceiving signal from a background noise in a ?ow of data for example, for a direct perception by a user or for a further use by another program. We then give three examples of multiscale techniques we used in the past, maintaining a summary, using an environmental marker introducing an history in the data and finally using a knowledge on the behavior of the different scales to really handle them at the same time.
Building upon Fast Multipole Methods to Detect and Model Organizations
Oct 08, 2009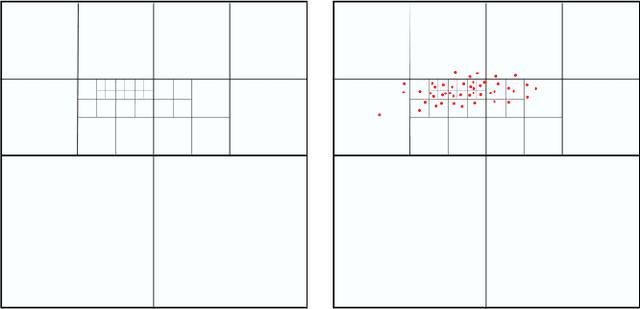
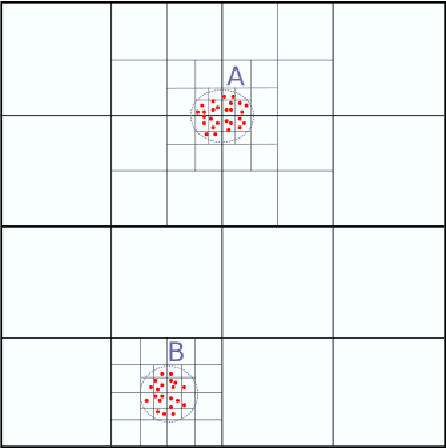
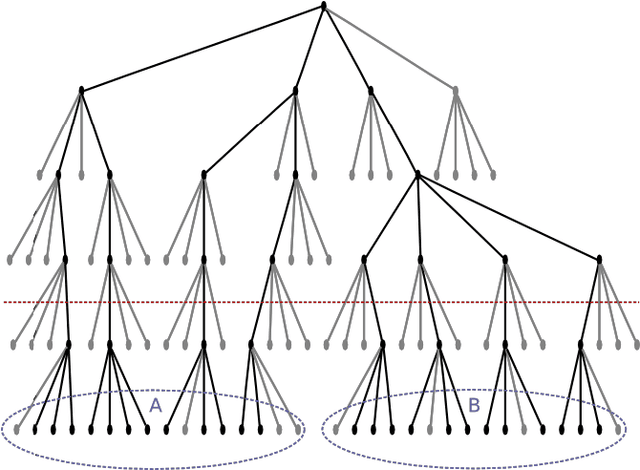
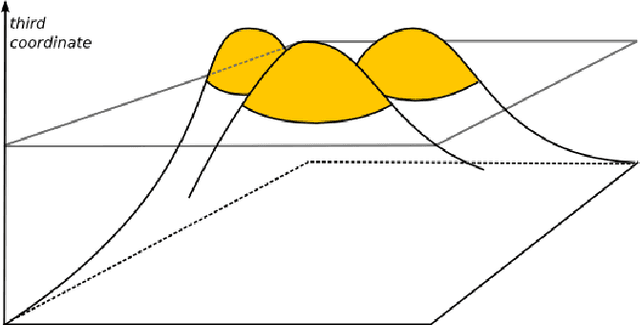
Many models in natural and social sciences are comprised of sets of inter-acting entities whose intensity of interaction decreases with distance. This often leads to structures of interest in these models composed of dense packs of entities. Fast Multipole Methods are a family of methods developed to help with the calculation of a number of computable models such as described above. We propose a method that builds upon FMM to detect and model the dense structures of these systems.
A multiagent urban traffic simulation. Part II: dealing with the extraordinary
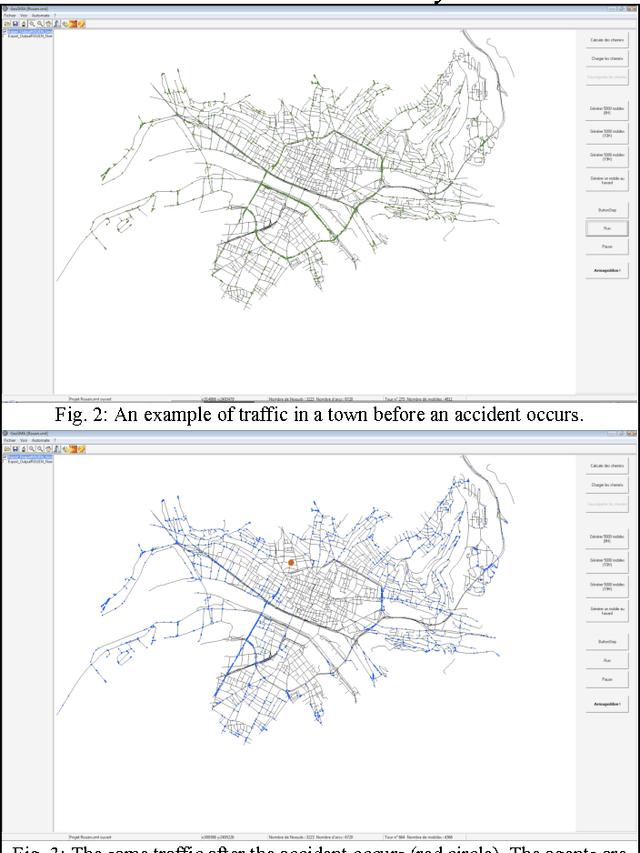
Oct 06, 2009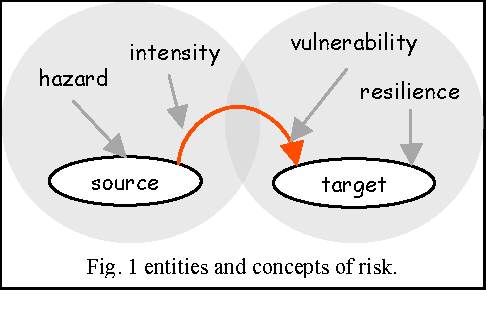
In Probabilistic Risk Management, risk is characterized by two quantities: the magnitude (or severity) of the adverse consequences that can potentially result from the given activity or action, and by the likelihood of occurrence of the given adverse consequences. But a risk seldom exists in isolation: chain of consequences must be examined, as the outcome of one risk can increase the likelihood of other risks. Systemic theory must complement classic PRM. Indeed these chains are composed of many different elements, all of which may have a critical importance at many different levels. Furthermore, when urban catastrophes are envisioned, space and time constraints are key determinants of the workings and dynamics of these chains of catastrophes: models must include a correct spatial topology of the studied risk. Finally, literature insists on the importance small events can have on the risk on a greater scale: urban risks management models belong to self-organized criticality theory. We chose multiagent systems to incorporate this property in our model: the behavior of an agent can transform the dynamics of important groups of them.