 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANIEL: A fast Document Attention Network for Information Extraction and Labelling of handwritten documents
Jul 12, 2024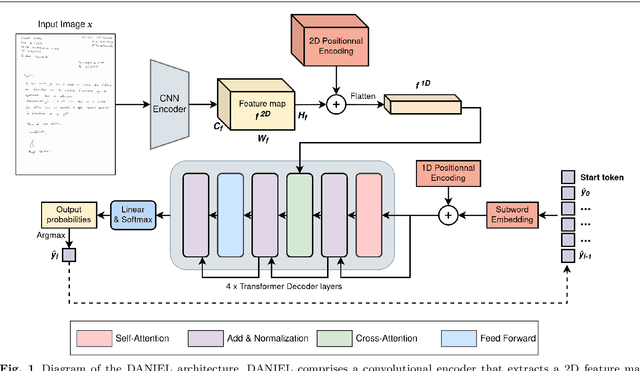
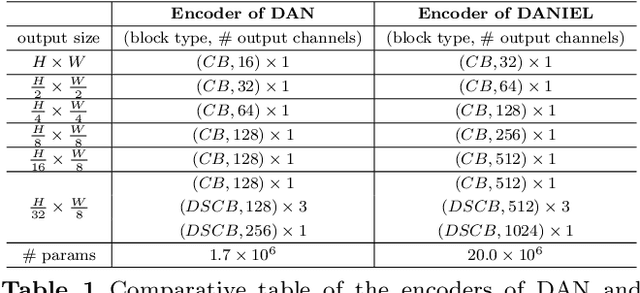
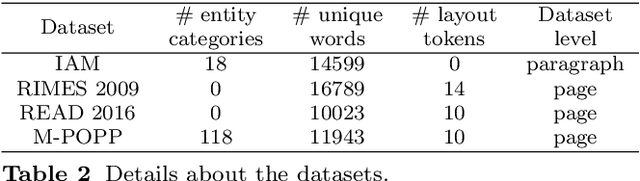

Information extraction from handwritten documents involves traditionally three distinct steps: Document Layout Analysis, Handwritten Text Recognition, and Named Entity Recognition. Recent approaches have attempted to integrate these steps into a single process using fully end-to-end architectures. Despite this, these integrated approaches have not yet matched the performance of language models, when applied to information extraction in plain text. In this paper, we introduce DANIEL (Document Attention Network for Information Extraction and Labelling), a fully end-to-end architecture integrating a language model and designed for comprehensive handwritten document understanding. DANIEL performs layout recognition, handwriting recognition, and named entity recognition on full-page documents. Moreover, it can simultaneously learn across multiple languages, layouts, and tasks. For named entity recognition, the ontology to be applied can be specified via the input prompt. The architecture employs a convolutional encoder capable of processing images of any size without resizing, paired with an autoregressive decoder based on a transformer-based language model. DANIEL achieves competitive results on four datasets, including a new state-of-the-art performance on RIMES 2009 and M-POPP for Handwriting Text Recognition, and IAM NER for Named Entity Recognition. Furthermore, DANIEL is much faster than existing approaches. We provide the source code and the weights of the trained models at \url{https://github.com/Shulk97/daniel}.
End-to-end information extraction in handwritten documents: Understanding Paris marriage records from 1880 to 1940
Apr 30, 2024
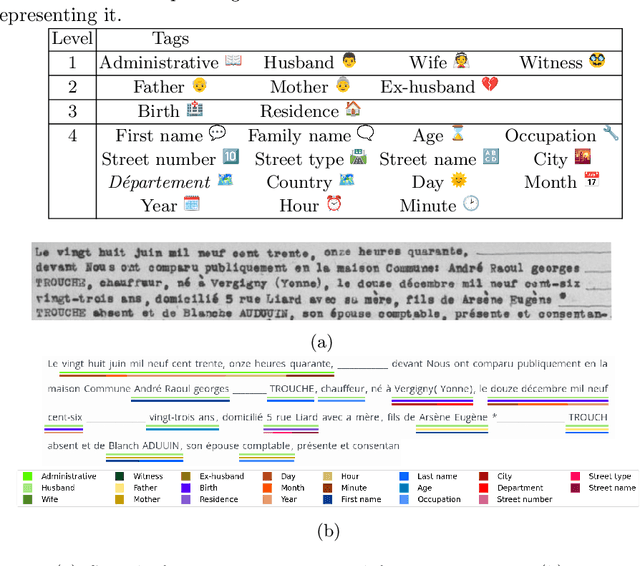


The EXO-POPP project aims to establish a comprehensive database comprising 300,000 marriage records from Paris and its suburbs, spanning the years 1880 to 1940, which are preserved in over 130,000 scans of double pages. Each marriage record may encompass up to 118 distinct types of information that require extraction from plain text. In this paper, we introduce the M-POPP dataset, a subset of the M-POPP database with annotations for full-page text recognition and information extraction in both handwritten and printed documents, and which is now publicly available. We present a fully end-to-end architecture adapted from the DAN, designed to perform both handwritten text recognition and information extraction directly from page images without the need for explicit segmentation. We showcase the information extraction capabilities of this architecture by achieving a new state of the art for full-page Information Extraction on Esposalles and we use this architecture as a baseline for the M-POPP dataset. We also assess and compare how different encoding strategies for named entities in the text affect the performance of jointly recognizing handwritten text and extracting information, from full pages.