 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoPlant: Spatial Plant Species Prediction Dataset
Aug 25, 2024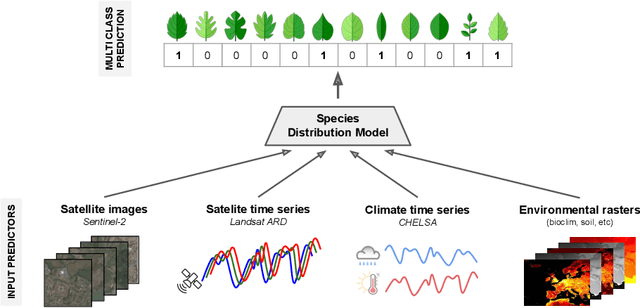
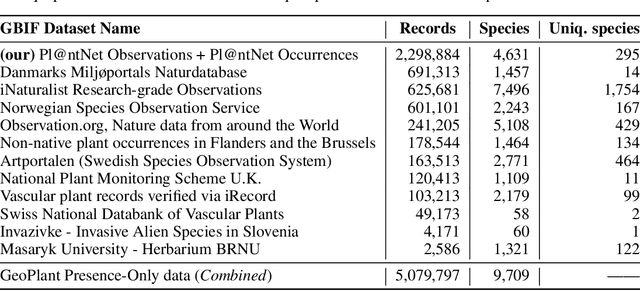
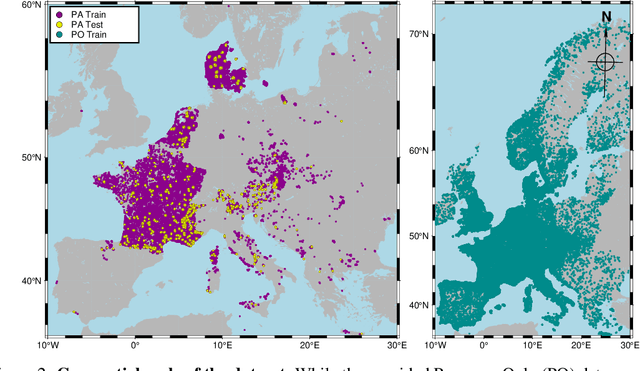
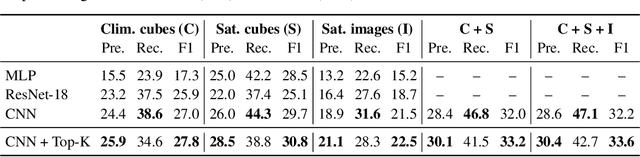
The difficulty of monitoring biodiversity at fine scales and over large areas limits ecological knowledge and conservation efforts. To fill this gap, Species Distribution Models (SDMs) predict species across space from spatially explicit features. Yet, they face the challenge of integrating the rich but heterogeneous data made available over the past decade, notably millions of opportunistic species observations and standardized surveys, as well as multi-modal remote sensing data. In light of that, we have designed and developed a new European-scale dataset for SDMs at high spatial resolution (10-50 m), including more than 10k species (i.e., most of the European flora). The dataset comprises 5M heterogeneous Presence-Only records and 90k exhaustive Presence-Absence survey records, all accompanied by diverse environmental rasters (e.g., elevation, human footprint, and soil) that are traditionally used in SDMs. In addition, it provides Sentinel-2 RGB and NIR satellite images with 10 m resolution, a 20-year time-series of climatic variables, and satellite time-series from the Landsat program. In addition to the data, we provide an openly accessible SDM benchmark (hosted on Kaggle), which has already attracted an active community and a set of strong baselines for single predictor/modality and multimodal approaches. All resources, e.g., the dataset, pre-trained models, and baseline methods (in the form of notebooks), are available on Kaggle, allowing one to start with our dataset literally with two mouse clicks.
End-to-end information extraction in handwritten documents: Understanding Paris marriage records from 1880 to 1940
Apr 30, 2024
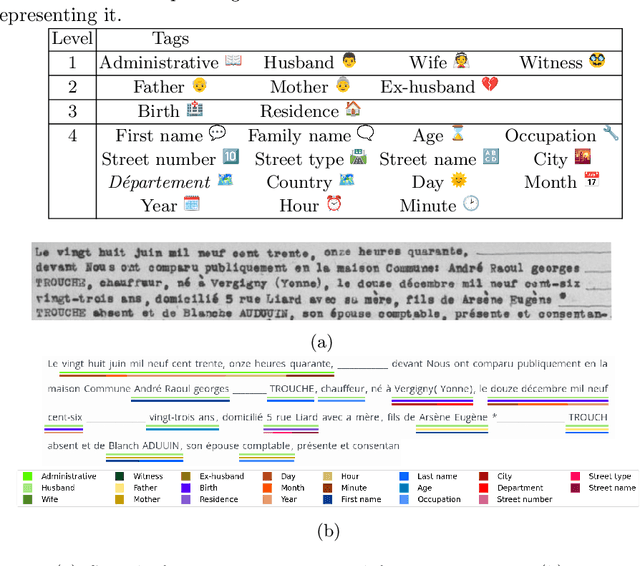


The EXO-POPP project aims to establish a comprehensive database comprising 300,000 marriage records from Paris and its suburbs, spanning the years 1880 to 1940, which are preserved in over 130,000 scans of double pages. Each marriage record may encompass up to 118 distinct types of information that require extraction from plain text. In this paper, we introduce the M-POPP dataset, a subset of the M-POPP database with annotations for full-page text recognition and information extraction in both handwritten and printed documents, and which is now publicly available. We present a fully end-to-end architecture adapted from the DAN, designed to perform both handwritten text recognition and information extraction directly from page images without the need for explicit segmentation. We showcase the information extraction capabilities of this architecture by achieving a new state of the art for full-page Information Extraction on Esposalles and we use this architecture as a baseline for the M-POPP dataset. We also assess and compare how different encoding strategies for named entities in the text affect the performance of jointly recognizing handwritten text and extracting information, from full pages.