 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Optimize Multispecies Set Predictions in Presence-Absence Modeling ?
Feb 12, 2026Species distribution models (SDMs) commonly produce probabilistic occurrence predictions that must be converted into binary presence-absence maps for ecological inference and conservation planning. However, this binarization step is typically heuristic and can substantially distort estimates of species prevalence and community composition. We present MaxExp, a decision-driven binarization framework that selects the most probable species assemblage by directly maximizing a chosen evaluation metric. MaxExp requires no calibration data and is flexible across several scores. We also introduce the Set Size Expectation (SSE) method, a computationally efficient alternative that predicts assemblages based on expected species richness. Using three case studies spanning diverse taxa, species counts, and performance metrics, we show that MaxExp consistently matches or surpasses widely used thresholding and calibration methods, especially under strong class imbalance and high rarity. SSE offers a simpler yet competitive option. Together, these methods provide robust, reproducible tools for multispecies SDM binarization.
GeoPl@ntNet: A Platform for Exploring Essential Biodiversity Variables
Nov 16, 2025This paper describes GeoPl@ntNet, an interactive web application designed to make Essential Biodiversity Variables accessible and understandable to everyone through dynamic maps and fact sheets. Its core purpose is to allow users to explore high-resolution AI-generated maps of species distributions, habitat types, and biodiversity indicators across Europe. These maps, developed through a cascading pipeline involving convolutional neural networks and large language models, provide an intuitive yet information-rich interface to better understand biodiversity, with resolutions as precise as 50x50 meters. The website also enables exploration of specific regions, allowing users to select areas of interest on the map (e.g., urban green spaces, protected areas, or riverbanks) to view local species and their coverage. Additionally, GeoPl@ntNet generates comprehensive reports for selected regions, including insights into the number of protected species, invasive species, and endemic species.
Mapping biodiversity at very-high resolution in Europe
Apr 07, 2025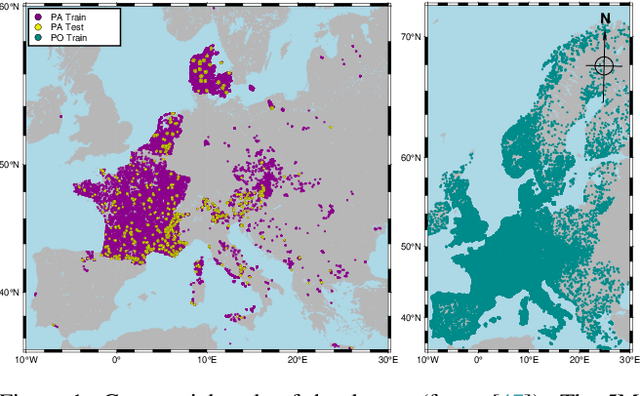
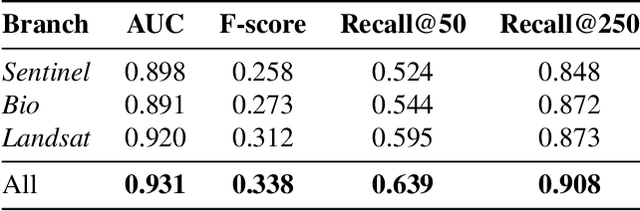
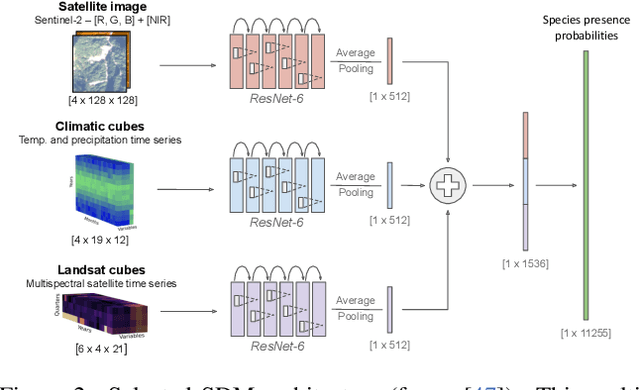

This paper describes a cascading multimodal pipeline for high-resolution biodiversity mapping across Europe, integrating species distribution modeling, biodiversity indicators, and habitat classification. The proposed pipeline first predicts species compositions using a deep-SDM, a multimodal model trained on remote sensing, climate time series, and species occurrence data at 50x50m resolution. These predictions are then used to generate biodiversity indicator maps and classify habitats with Pl@ntBERT, a transformer-based LLM designed for species-to-habitat mapping. With this approach, continental-scale species distribution maps, biodiversity indicator maps, and habitat maps are produced, providing fine-grained ecological insights. Unlike traditional methods, this framework enables joint modeling of interspecies dependencies, bias-aware training with heterogeneous presence-absence data, and large-scale inference from multi-source remote sensing inputs.
Applying the maximum entropy principle to multi-species neural networks improves species distribution models
Dec 26, 2024



The rapid expansion of citizen science initiatives has led to a significant growth of biodiversity databases, and particularly presence-only (PO) observations. PO data are invaluable for understanding species distributions and their dynamics, but their use in Species Distribution Models (SDM) is curtailed by sampling biases and the lack of information on absences. Poisson point processes are widely used for SDMs, with Maxent being one of the most popular methods. Maxent maximises the entropy of a probability distribution across sites as a function of predefined transformations of environmental variables, called features. In contrast, neural networks and deep learning have emerged as a promising technique for automatic feature extraction from complex input variables. In this paper, we propose DeepMaxent, which harnesses neural networks to automatically learn shared features among species, using the maximum entropy principle. To do so, it employs a normalised Poisson loss where for each species, presence probabilities across sites are modelled by a neural network. We evaluate DeepMaxent on a benchmark dataset known for its spatial sampling biases, using PO data for calibration and presence-absence (PA) data for validation across six regions with different biological groups and environmental covariates. Our results indicate that DeepMaxent improves model performance over Maxent and other state-of-the-art SDMs across regions and taxonomic groups. The method performs particularly well in regions of uneven sampling, demonstrating substantial potential to improve species distribution modelling. The method opens the possibility to learn more robust environmental features predicting jointly many species and scales to arbitrary large numbers of sites without an increased memory demand.
MALPOLON: A Framework for Deep Species Distribution Modeling
Sep 26, 2024This paper describes a deep-SDM framework, MALPOLON. Written in Python and built upon the PyTorch library, this framework aims to facilitate training and inferences of deep species distribution models (deep-SDM) and sharing for users with only general Python language skills (e.g., modeling ecologists) who are interested in testing deep learning approaches to build new SDMs. More advanced users can also benefit from the framework's modularity to run more specific experiments by overriding existing classes while taking advantage of press-button examples to train neural networks on multiple classification tasks using custom or provided raw and pre-processed datasets. The framework is open-sourced on GitHub and PyPi along with extensive documentation and examples of use in various scenarios. MALPOLON offers straightforward installation, YAML-based configuration, parallel computing, multi-GPU utilization, baseline and foundational models for benchmarking, and extensive tutorials/documentation, aiming to enhance accessibility and performance scalability for ecologists and researchers.
GeoPlant: Spatial Plant Species Prediction Dataset
Aug 25, 2024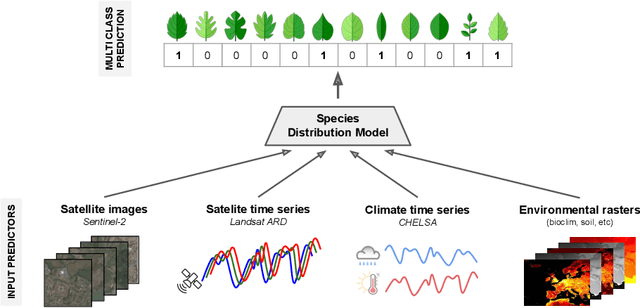
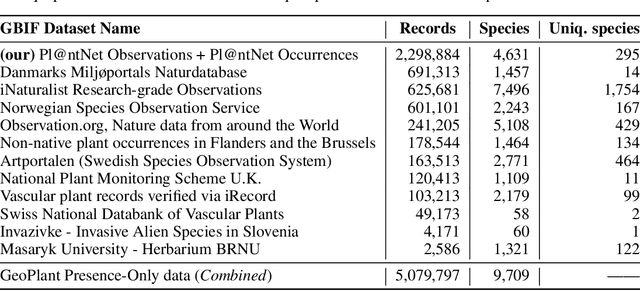
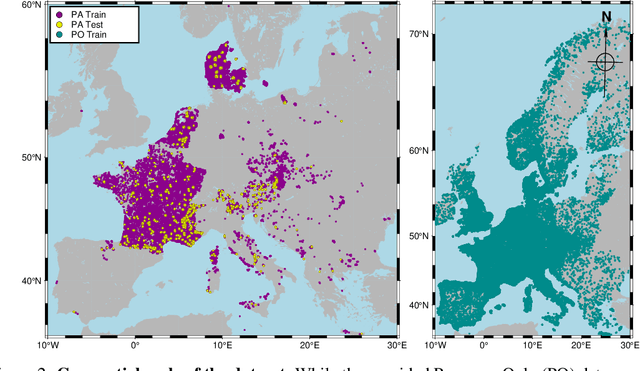
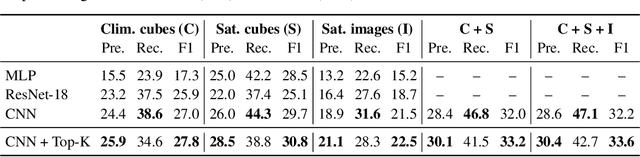
The difficulty of monitoring biodiversity at fine scales and over large areas limits ecological knowledge and conservation efforts. To fill this gap, Species Distribution Models (SDMs) predict species across space from spatially explicit features. Yet, they face the challenge of integrating the rich but heterogeneous data made available over the past decade, notably millions of opportunistic species observations and standardized surveys, as well as multi-modal remote sensing data. In light of that, we have designed and developed a new European-scale dataset for SDMs at high spatial resolution (10-50 m), including more than 10k species (i.e., most of the European flora). The dataset comprises 5M heterogeneous Presence-Only records and 90k exhaustive Presence-Absence survey records, all accompanied by diverse environmental rasters (e.g., elevation, human footprint, and soil) that are traditionally used in SDMs. In addition, it provides Sentinel-2 RGB and NIR satellite images with 10 m resolution, a 20-year time-series of climatic variables, and satellite time-series from the Landsat program. In addition to the data, we provide an openly accessible SDM benchmark (hosted on Kaggle), which has already attracted an active community and a set of strong baselines for single predictor/modality and multimodal approaches. All resources, e.g., the dataset, pre-trained models, and baseline methods (in the form of notebooks), are available on Kaggle, allowing one to start with our dataset literally with two mouse clicks.
Modelling Species Distributions with Deep Learning to Predict Plant Extinction Risk and Assess Climate Change Impacts
Jan 10, 2024The post-2020 global biodiversity framework needs ambitious, research-based targets. Estimating the accelerated extinction risk due to climate change is critical. The International Union for Conservation of Nature (IUCN) measures the extinction risk of species. Automatic methods have been developed to provide information on the IUCN status of under-assessed taxa. However, these compensatory methods are based on current species characteristics, mainly geographical, which precludes their use in future projections. Here, we evaluate a novel method for classifying the IUCN status of species benefiting from the generalisation power of species distribution models based on deep learning. Our method matches state-of-the-art classification performance while relying on flexible SDM-based features that capture species' environmental preferences. Cross-validation yields average accuracies of 0.61 for status classification and 0.78 for binary classification. Climate change will reshape future species distributions. Under the species-environment equilibrium hypothesis, SDM projections approximate plausible future outcomes. Two extremes of species dispersal capacity are considered: unlimited or null. The projected species distributions are translated into features feeding our IUCN classification method. Finally, trends in threatened species are analysed over time and i) by continent and as a function of average ii) latitude or iii) altitude. The proportion of threatened species is increasing globally, with critical rates in Africa, Asia and South America. Furthermore, the proportion of threatened species is predicted to peak around the two Tropics, at the Equator, in the lowlands and at altitudes of 800-1,500 m.
AI-based Mapping of the Conservation Status of Orchid Assemblages at Global Scale
Jan 09, 2024



Although increasing threats on biodiversity are now widely recognised, there are no accurate global maps showing whether and where species assemblages are at risk. We hereby assess and map at kilometre resolution the conservation status of the iconic orchid family, and discuss the insights conveyed at multiple scales. We introduce a new Deep Species Distribution Model trained on 1M occurrences of 14K orchid species to predict their assemblages at global scale and at kilometre resolution. We propose two main indicators of the conservation status of the assemblages: (i) the proportion of threatened species, and (ii) the status of the most threatened species in the assemblage. We show and analyze the variation of these indicators at World scale and in relation to currently protected areas in Sumatra island. Global and interactive maps available online show the indicators of conservation status of orchid assemblages, with sharp spatial variations at all scales. The highest level of threat is found at Madagascar and the neighbouring islands. In Sumatra, we found good correspondence of protected areas with our indicators, but supplementing current IUCN assessments with status predictions results in alarming levels of species threat across the island. Recent advances in deep learning enable reliable mapping of the conservation status of species assemblages on a global scale. As an umbrella taxon, orchid family provides a reference for identifying vulnerable ecosystems worldwide, and prioritising conservation actions both at international and local levels.
A two-head loss function for deep Average-K classification
Mar 31, 2023


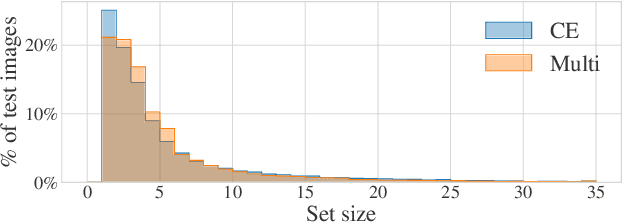
Average-K classification is an alternative to top-K classification in which the number of labels returned varies with the ambiguity of the input image but must average to K over all the samples. A simple method to solve this task is to threshold the softmax output of a model trained with the cross-entropy loss. This approach is theoretically proven to be asymptotically consistent, but it is not guaranteed to be optimal for a finite set of samples. In this paper, we propose a new loss function based on a multi-label classification head in addition to the classical softmax. This second head is trained using pseudo-labels generated by thresholding the softmax head while guaranteeing that K classes are returned on average. We show that this approach allows the model to better capture ambiguities between classes and, as a result, to return more consistent sets of possible classes. Experiments on two datasets from the literature demonstrate that our approach outperforms the softmax baseline, as well as several other loss functions more generally designed for weakly supervised multi-label classification. The gains are larger the higher the uncertainty, especially for classes with few samples.
Stochastic smoothing of the top-K calibrated hinge loss for deep imbalanced classification
Feb 04, 2022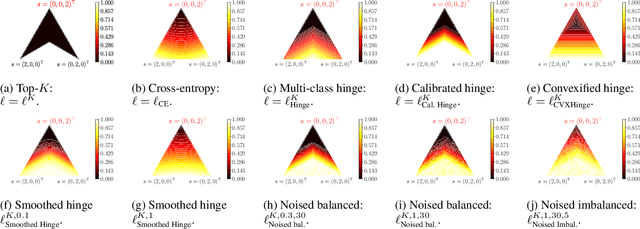

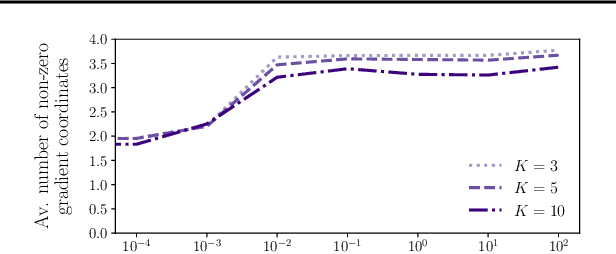

In modern classification tasks, the number of labels is getting larger and larger, as is the size of the datasets encountered in practice. As the number of classes increases, class ambiguity and class imbalance become more and more problematic to achieve high top-1 accuracy. Meanwhile, Top-K metrics (metrics allowing K guesses) have become popular, especially for performance reporting. Yet, proposing top-K losses tailored for deep learning remains a challenge, both theoretically and practically. In this paper we introduce a stochastic top-K hinge loss inspired by recent developments on top-K calibrated losses. Our proposal is based on the smoothing of the top-K operator building on the flexible "perturbed optimizer" framework. We show that our loss function performs very well in the case of balanced datasets, while benefiting from a significantly lower computational time than the state-of-the-art top-K loss function. In addition, we propose a simple variant of our loss for the imbalanced case. Experiments on a heavy-tailed dataset show that our loss function significantly outperforms other baseline loss functions.