 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciTweets -- A Dataset and Annotation Framework for Detecting Scientific Online Discourse
Jun 15, 2022
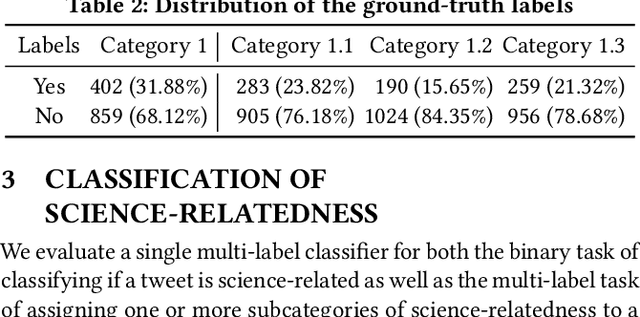
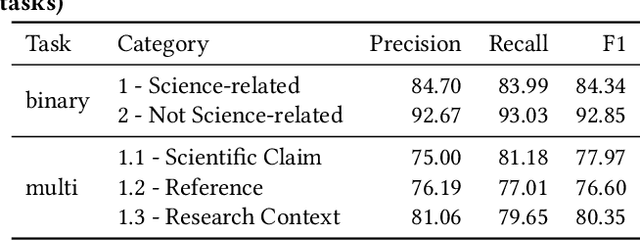
Scientific topics, claims and resources are increasingly debated as part of online discourse, where prominent examples include discourse related to COVID-19 or climate change. This has led to both significant societal impact and increased interest in scientific online discourse from various disciplines. For instance, communication studies aim at a deeper understanding of biases, quality or spreading pattern of scientific information whereas computational methods have been proposed to extract, classify or verify scientific claims using NLP and IR techniques. However, research across disciplines currently suffers from both a lack of robust definitions of the various forms of science-relatedness as well as appropriate ground truth data for distinguishing them. In this work, we contribute (a) an annotation framework and corresponding definitions for different forms of scientific relatedness of online discourse in Tweets, (b) an expert-annotated dataset of 1261 tweets obtained through our labeling framework reaching an average Fleiss Kappa $\kappa$ of 0.63, (c) a multi-label classifier trained on our data able to detect science-relatedness with 89% F1 and also able to detect distinct forms of scientific knowledge (claims, references). With this work we aim to lay the foundation for developing and evaluating robust methods for analysing science as part of large-scale online discourse.
Controversy Detection: a Text and Graph Neural Network Based Approach
Dec 03, 2021



Controversial content refers to any content that attracts both positive and negative feedback. Its automatic identification, especially on social media, is a challenging task as it should be done on a large number of continuously evolving posts, covering a large variety of topics. Most of the existing approaches rely on the graph structure of a topic-discussion and/or the content of messages. This paper proposes a controversy detection approach based on both graph structure of a discussion and text features. Our proposed approach relies on Graph Neural Network (gnn) to encode the graph representation (including its texts) in an embedding vector before performing a graph classification task. The latter will classify the post as controversial or not. Two controversy detection strategies are proposed. The first one is based on a hierarchical graph representation learning. Graph user nodes are embedded hierarchically and iteratively to compute the whole graph embedding vector. The second one is based on the attention mechanism, which allows each user node to give more or less importance to its neighbors when computing node embeddings. We conduct experiments to evaluate our approach using different real-world datasets. Conducted experiments show the positive impact of combining textual features and structural information in terms of performance.
Attention-based Modeling for Emotion Detection and Classification in Textual Conversations
Jun 14, 2019
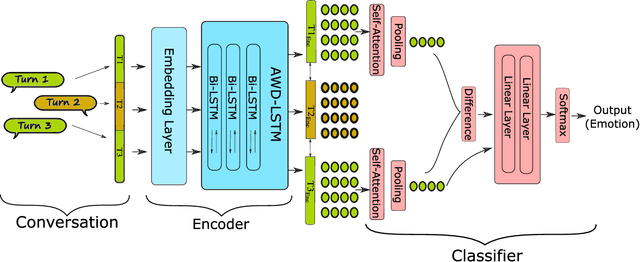
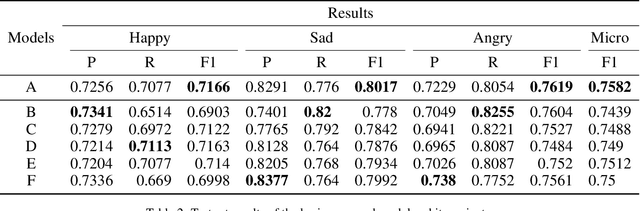
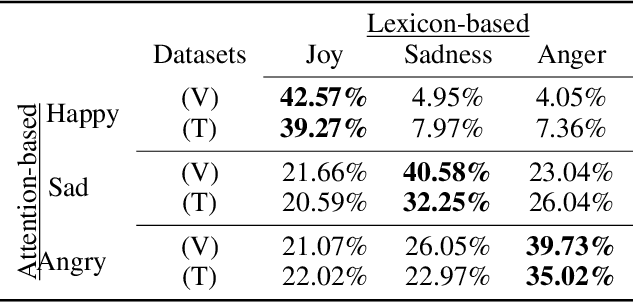
This paper addresses the problem of modeling textual conversations and detecting emotions. Our proposed model makes use of 1) deep transfer learning rather than the classical shallow methods of word embedding; 2) self-attention mechanisms to focus on the most important parts of the texts and 3) turn-based conversational modeling for classifying the emotions. The approach does not rely on any hand-crafted features or lexicons. Our model was evaluated on the data provided by the SemEval-2019 shared task on contextual emotion detection in text. The model shows very competitive results.