 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CLEF-2026 CheckThat! Lab: Advancing Multilingual Fact-Checking
Feb 10, 2026The CheckThat! lab aims to advance the development of innovative technologies combating disinformation and manipulation efforts in online communication across a multitude of languages and platforms. While in early editions the focus has been on core tasks of the verification pipeline (check-worthiness, evidence retrieval, and verification), in the past three editions, the lab added additional tasks linked to the verification process. In this year's edition, the verification pipeline is at the center again with the following tasks: Task 1 on source retrieval for scientific web claims (a follow-up of the 2025 edition), Task 2 on fact-checking numerical and temporal claims, which adds a reasoning component to the 2025 edition, and Task 3, which expands the verification pipeline with generation of full-fact-checking articles. These tasks represent challenging classification and retrieval problems as well as generation challenges at the document and span level, including multilingual settings.
The CLEF-2025 CheckThat! Lab: Subjectivity, Fact-Checking, Claim Normalization, and Retrieval
Mar 19, 2025The CheckThat! lab aims to advance the development of innovative technologies designed to identify and counteract online disinformation and manipulation efforts across various languages and platforms. The first five editions focused on key tasks in the information verification pipeline, including check-worthiness, evidence retrieval and pairing, and verification. Since the 2023 edition, the lab has expanded its scope to address auxiliary tasks that support research and decision-making in verification. In the 2025 edition, the lab revisits core verification tasks while also considering auxiliary challenges. Task 1 focuses on the identification of subjectivity (a follow-up from CheckThat! 2024), Task 2 addresses claim normalization, Task 3 targets fact-checking numerical claims, and Task 4 explores scientific web discourse processing. These tasks present challenging classification and retrieval problems at both the document and span levels, including multilingual settings.
"Only ChatGPT gets me": An Empirical Analysis of GPT versus other Large Language Models for Emotion Detection in Text
Mar 05, 2025This work investigates the capabilities of large language models (LLMs) in detecting and understanding human emotions through text. Drawing upon emotion models from psychology, we adopt an interdisciplinary perspective that integrates computational and affective sciences insights. The main goal is to assess how accurately they can identify emotions expressed in textual interactions and compare different models on this specific task. This research contributes to broader efforts to enhance human-computer interaction, making artificial intelligence technologies more responsive and sensitive to users' emotional nuances. By employing a methodology that involves comparisons with a state-of-the-art model on the GoEmotions dataset, we aim to gauge LLMs' effectiveness as a system for emotional analysis, paving the way for potential applications in various fields that require a nuanced understanding of human language.
Improving (Re-)Usability of Musical Datasets: An Overview of the DOREMUS Project
May 06, 2024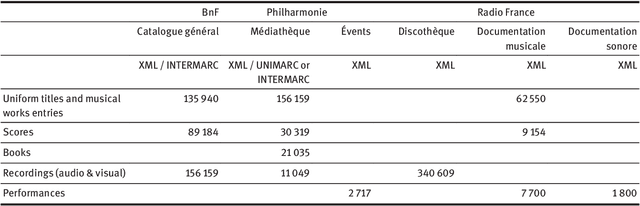
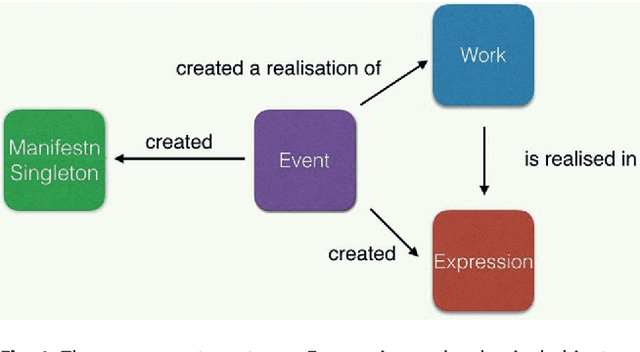
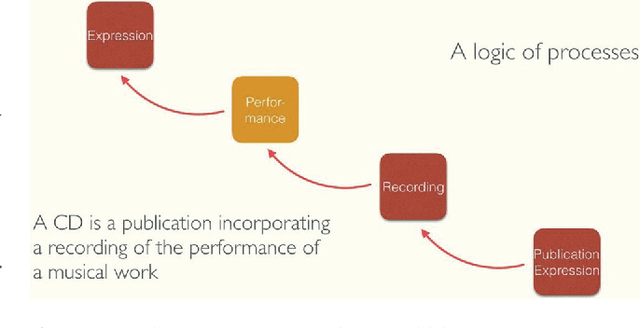
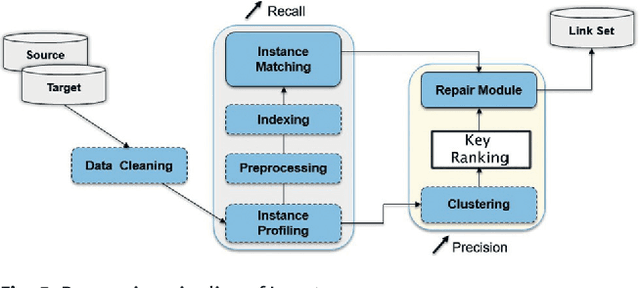
DOREMUS works on a better description of music by building new tools to link and explore the data of three French institutions. This paper gives an overview of the data model based on FRBRoo, explains the conversion and linking processes using linked data technologies and presents the prototypes created to consume the data according to the web users' needs.
SciTweets -- A Dataset and Annotation Framework for Detecting Scientific Online Discourse
Jun 15, 2022
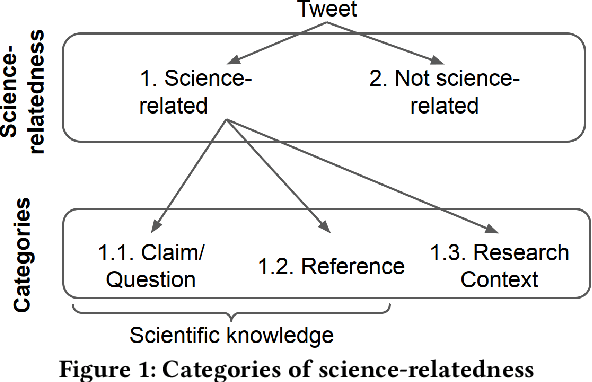
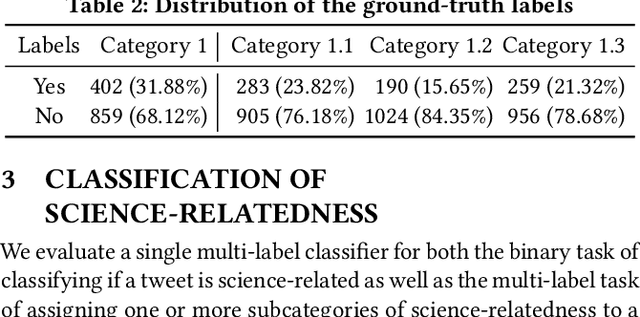
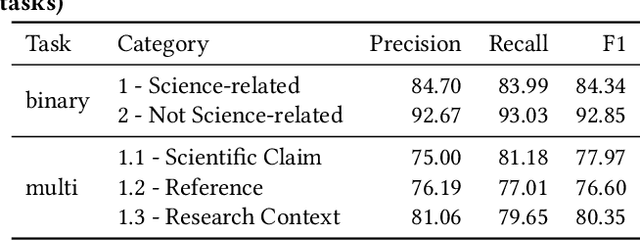
Scientific topics, claims and resources are increasingly debated as part of online discourse, where prominent examples include discourse related to COVID-19 or climate change. This has led to both significant societal impact and increased interest in scientific online discourse from various disciplines. For instance, communication studies aim at a deeper understanding of biases, quality or spreading pattern of scientific information whereas computational methods have been proposed to extract, classify or verify scientific claims using NLP and IR techniques. However, research across disciplines currently suffers from both a lack of robust definitions of the various forms of science-relatedness as well as appropriate ground truth data for distinguishing them. In this work, we contribute (a) an annotation framework and corresponding definitions for different forms of scientific relatedness of online discourse in Tweets, (b) an expert-annotated dataset of 1261 tweets obtained through our labeling framework reaching an average Fleiss Kappa $\kappa$ of 0.63, (c) a multi-label classifier trained on our data able to detect science-relatedness with 89% F1 and also able to detect distinct forms of scientific knowledge (claims, references). With this work we aim to lay the foundation for developing and evaluating robust methods for analysing science as part of large-scale online discourse.
An Assessment of the Impact of OCR Noise on Language Models
Jan 26, 2022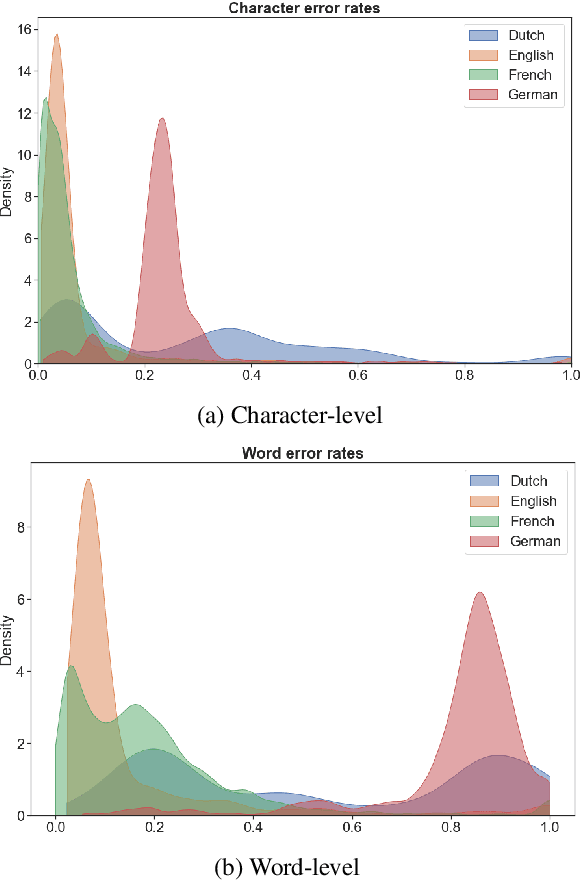
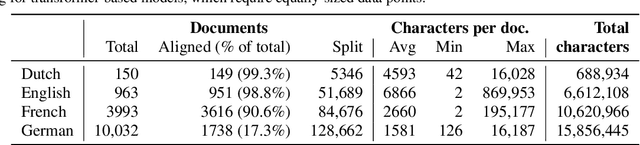
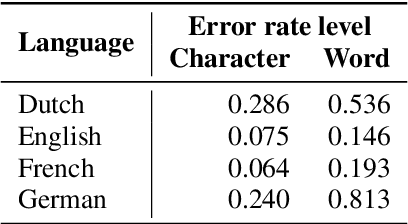
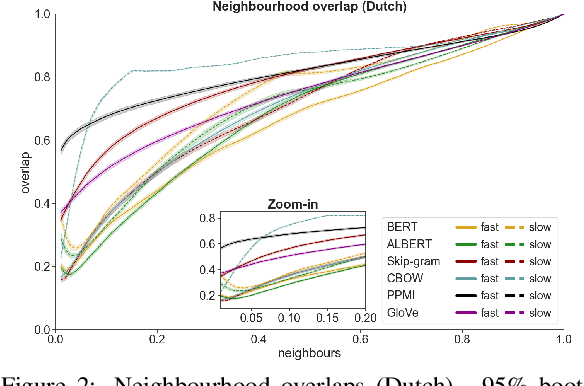
Neural language models are the backbone of modern-day natural language processing applications. Their use on textual heritage collections which have undergone Optical Character Recognition (OCR) is therefore also increasing. Nevertheless, our understanding of the impact OCR noise could have on language models is still limited. We perform an assessment of the impact OCR noise has on a variety of language models, using data in Dutch, English, French and German. We find that OCR noise poses a significant obstacle to language modelling, with language models increasingly diverging from their noiseless targets as OCR quality lowers. In the presence of small corpora, simpler models including PPMI and Word2Vec consistently outperform transformer-based models in this respect.