 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIBER: A Multilingual Evaluation Resource for Factual Inference Bias
Dec 11, 2025Large language models are widely used across domains, yet there are concerns about their factual reliability and biases. Factual knowledge probing offers a systematic means to evaluate these aspects. Most existing benchmarks focus on single-entity facts and monolingual data. We therefore present FIBER, a multilingual benchmark for evaluating factual knowledge in single- and multi-entity settings. The dataset includes sentence completion, question-answering, and object-count prediction tasks in English, Italian, and Turkish. Using FIBER, we examine whether the prompt language induces inference bias in entity selection and how large language models perform on multi-entity versus single-entity questions. The results indicate that the language of the prompt can influence the model's generated output, particularly for entities associated with the country corresponding to that language. However, this effect varies across different topics such that 31% of the topics exhibit factual inference bias score greater than 0.5. Moreover, the level of bias differs across languages such that Turkish prompts show higher bias compared to Italian in 83% of the topics, suggesting a language-dependent pattern. Our findings also show that models face greater difficulty when handling multi-entity questions than the single-entity questions. Model performance differs across both languages and model sizes. The highest mean average precision is achieved in English, while Turkish and Italian lead to noticeably lower scores. Larger models, including Llama-3.1-8B and Qwen-2.5-7B, show consistently better performance than smaller 3B-4B models.
The CLEF-2025 CheckThat! Lab: Subjectivity, Fact-Checking, Claim Normalization, and Retrieval
Mar 19, 2025The CheckThat! lab aims to advance the development of innovative technologies designed to identify and counteract online disinformation and manipulation efforts across various languages and platforms. The first five editions focused on key tasks in the information verification pipeline, including check-worthiness, evidence retrieval and pairing, and verification. Since the 2023 edition, the lab has expanded its scope to address auxiliary tasks that support research and decision-making in verification. In the 2025 edition, the lab revisits core verification tasks while also considering auxiliary challenges. Task 1 focuses on the identification of subjectivity (a follow-up from CheckThat! 2024), Task 2 addresses claim normalization, Task 3 targets fact-checking numerical claims, and Task 4 explores scientific web discourse processing. These tasks present challenging classification and retrieval problems at both the document and span levels, including multilingual settings.
Untangling Hate Speech Definitions: A Semantic Componential Analysis Across Cultures and Domains
Nov 11, 2024
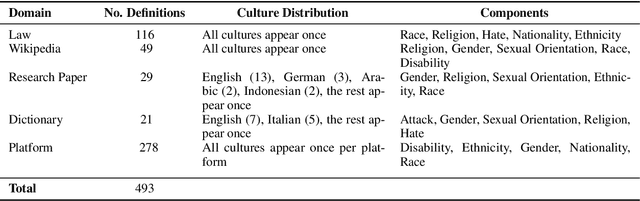

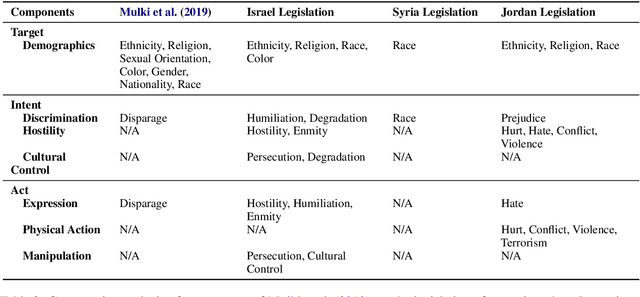
Hate speech relies heavily on cultural influences, leading to varying individual interpretations. For that reason, we propose a Semantic Componential Analysis (SCA) framework for a cross-cultural and cross-domain analysis of hate speech definitions. We create the first dataset of definitions derived from five domains: online dictionaries, research papers, Wikipedia articles, legislation, and online platforms, which are later analyzed into semantic components. Our analysis reveals that the components differ from definition to definition, yet many domains borrow definitions from one another without taking into account the target culture. We conduct zero-shot model experiments using our proposed dataset, employing three popular open-sourced LLMs to understand the impact of different definitions on hate speech detection. Our findings indicate that LLMs are sensitive to definitions: responses for hate speech detection change according to the complexity of definitions used in the prompt.
Language is Scary when Over-Analyzed: Unpacking Implied Misogynistic Reasoning with Argumentation Theory-Driven Prompts
Sep 04, 2024



We propose misogyny detection as an Argumentative Reasoning task and we investigate the capacity of large language models (LLMs) to understand the implicit reasoning used to convey misogyny in both Italian and English. The central aim is to generate the missing reasoning link between a message and the implied meanings encoding the misogyny. Our study uses argumentation theory as a foundation to form a collection of prompts in both zero-shot and few-shot settings. These prompts integrate different techniques, including chain-of-thought reasoning and augmented knowledge. Our findings show that LLMs fall short on reasoning capabilities about misogynistic comments and that they mostly rely on their implicit knowledge derived from internalized common stereotypes about women to generate implied assumptions, rather than on inductive reasoning.
Let Guidelines Guide You: A Prescriptive Guideline-Centered Data Annotation Methodology
Jun 20, 2024


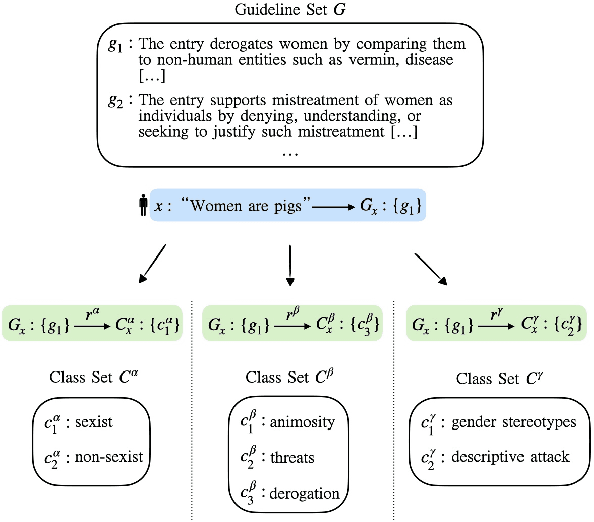
We introduce the Guideline-Centered annotation process, a novel data annotation methodology focused on reporting the annotation guidelines associated with each data sample. We identify three main limitations of the standard prescriptive annotation process and describe how the Guideline-Centered methodology overcomes them by reducing the loss of information in the annotation process and ensuring adherence to guidelines. Additionally, we discuss how the Guideline-Centered enables the reuse of annotated data across multiple tasks at the cost of a single human-annotation process.
PejorativITy: Disambiguating Pejorative Epithets to Improve Misogyny Detection in Italian Tweets
Apr 03, 2024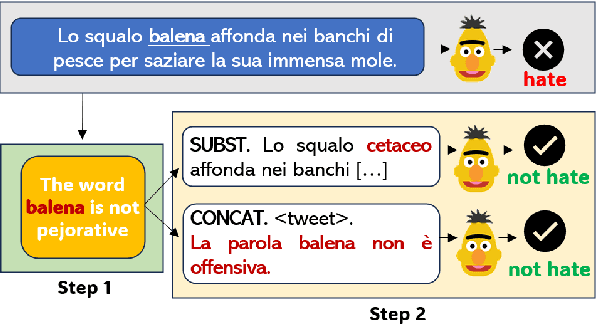
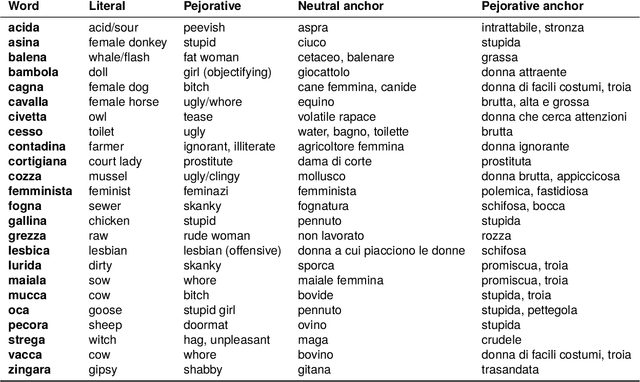
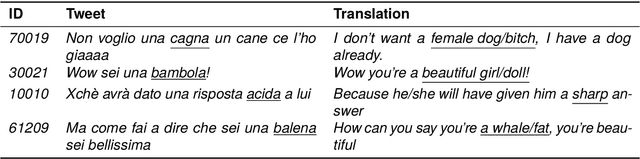
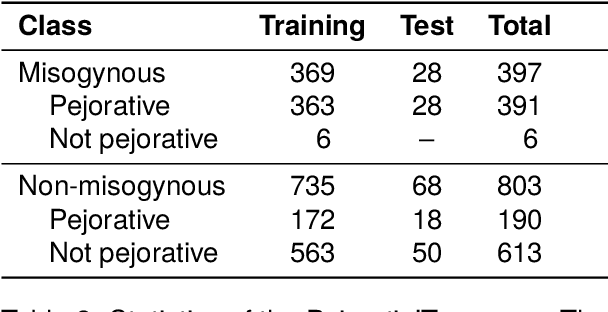
Misogyny is often expressed through figurative language. Some neutral words can assume a negative connotation when functioning as pejorative epithets. Disambiguating the meaning of such terms might help the detection of misogyny. In order to address such task, we present PejorativITy, a novel corpus of 1,200 manually annotated Italian tweets for pejorative language at the word level and misogyny at the sentence level. We evaluate the impact of injecting information about disambiguated words into a model targeting misogyny detection. In particular, we explore two different approaches for injection: concatenation of pejorative information and substitution of ambiguous words with univocal terms. Our experimental results, both on our corpus and on two popular benchmarks on Italian tweets, show that both approaches lead to a major classification improvement, indicating that word sense disambiguation is a promising preliminary step for misogyny detection. Furthermore, we investigate LLMs' understanding of pejorative epithets by means of contextual word embeddings analysis and prompting.
A Corpus for Sentence-level Subjectivity Detection on English News Articles
May 29, 2023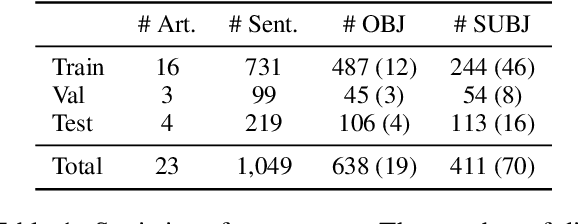

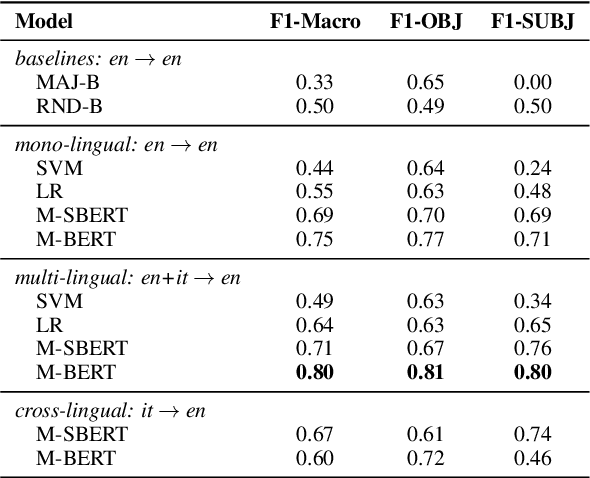
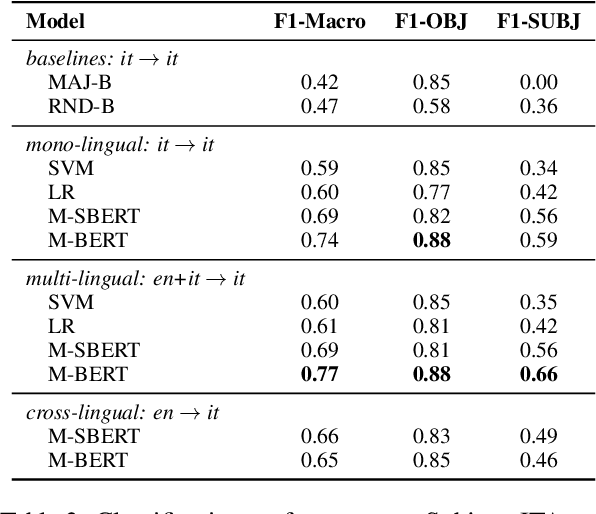
We present a novel corpus for subjectivity detection at the sentence level. We develop new annotation guidelines for the task, which are not limited to language-specific cues, and apply them to produce a new corpus in English. The corpus consists of 411 subjective and 638 objective sentences extracted from ongoing coverage of political affairs from online news outlets. This new resource paves the way for the development of models for subjectivity detection in English and across other languages, without relying on language-specific tools like lexicons or machine translation. We evaluate state-of-the-art multilingual transformer-based models on the task, both in mono- and cross-lingual settings, the latter with a similar existing corpus in Italian language. We observe that enriching our corpus with resources in other languages improves the results on the task.