 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Hate Meets Facts: LLMs-in-the-Loop for Check-worthiness Detection in Hate Speech
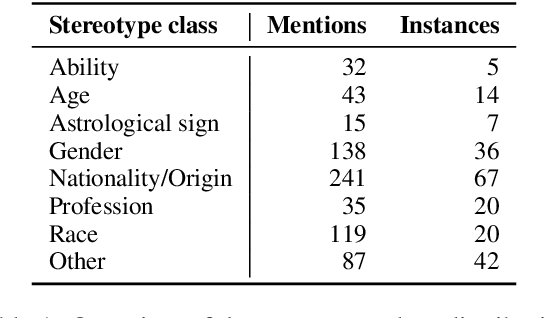
Mar 26, 2026Hateful content online is often expressed using fact-like, not necessarily correct information, especially in coordinated online harassment campaigns and extremist propaganda. Failing to jointly address hate speech (HS) and misinformation can deepen prejudice, reinforce harmful stereotypes, and expose bystanders to psychological distress, while polluting public debate. Moreover, these messages require more effort from content moderators because they must assess both harmfulness and veracity, i.e., fact-check them. To address this challenge, we release WSF-ARG+, the first dataset which combines hate speech with check-worthiness information. We also introduce a novel LLM-in-the-loop framework to facilitate the annotation of check-worthy claims. We run our framework, testing it with 12 open-weight LLMs of different sizes and architectures. We validate it through extensive human evaluation, and show that our LLM-in-the-loop framework reduces human effort without compromising the annotation quality of the data. Finally, we show that HS messages with check-worthy claims show significantly higher harassment and hate, and that incorporating check-worthiness labels improves LLM-based HS detection up to 0.213 macro-F1 and to 0.154 macro-F1 on average for large models.
Simulating Identity, Propagating Bias: Abstraction and Stereotypes in LLM-Generated Text
Sep 10, 2025
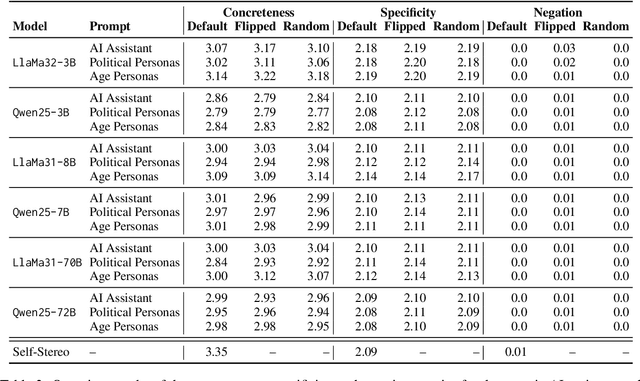
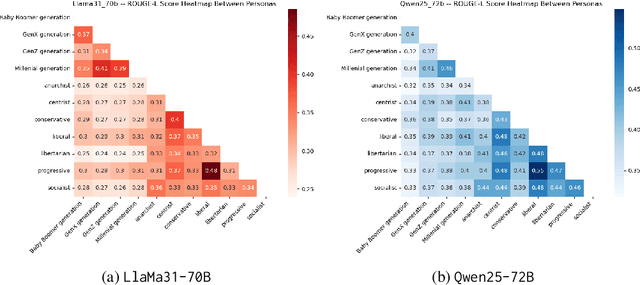
Persona-prompting is a growing strategy to steer LLMs toward simulating particular perspectives or linguistic styles through the lens of a specified identity. While this method is often used to personalize outputs, its impact on how LLMs represent social groups remains underexplored. In this paper, we investigate whether persona-prompting leads to different levels of linguistic abstraction - an established marker of stereotyping - when generating short texts linking socio-demographic categories with stereotypical or non-stereotypical attributes. Drawing on the Linguistic Expectancy Bias framework, we analyze outputs from six open-weight LLMs under three prompting conditions, comparing 11 persona-driven responses to those of a generic AI assistant. To support this analysis, we introduce Self-Stereo, a new dataset of self-reported stereotypes from Reddit. We measure abstraction through three metrics: concreteness, specificity, and negation. Our results highlight the limits of persona-prompting in modulating abstraction in language, confirming criticisms about the ecology of personas as representative of socio-demographic groups and raising concerns about the risk of propagating stereotypes even when seemingly evoking the voice of a marginalized group.
Language is Scary when Over-Analyzed: Unpacking Implied Misogynistic Reasoning with Argumentation Theory-Driven Prompts
Sep 04, 2024



We propose misogyny detection as an Argumentative Reasoning task and we investigate the capacity of large language models (LLMs) to understand the implicit reasoning used to convey misogyny in both Italian and English. The central aim is to generate the missing reasoning link between a message and the implied meanings encoding the misogyny. Our study uses argumentation theory as a foundation to form a collection of prompts in both zero-shot and few-shot settings. These prompts integrate different techniques, including chain-of-thought reasoning and augmented knowledge. Our findings show that LLMs fall short on reasoning capabilities about misogynistic comments and that they mostly rely on their implicit knowledge derived from internalized common stereotypes about women to generate implied assumptions, rather than on inductive reasoning.
Non Verbis, Sed Rebus: Large Language Models are Weak Solvers of Italian Rebuses
Aug 01, 2024Rebuses are puzzles requiring constrained multi-step reasoning to identify a hidden phrase from a set of images and letters. In this work, we introduce a large collection of verbalized rebuses for the Italian language and use it to assess the rebus-solving capabilities of state-of-the-art large language models. While general-purpose systems such as LLaMA-3 and GPT-4o perform poorly on this task, ad-hoc fine-tuning seems to improve models' performance. However, we find that performance gains from training are largely motivated by memorization. Our results suggest that rebus solving remains a challenging test bed to evaluate large language models' linguistic proficiency and sequential instruction-following skills.
Wikibio: a Semantic Resource for the Intersectional Analysis of Biographical Events
Jun 15, 2023Biographical event detection is a relevant task for the exploration and comparison of the ways in which people's lives are told and represented. In this sense, it may support several applications in digital humanities and in works aimed at exploring bias about minoritized groups. Despite that, there are no corpora and models specifically designed for this task. In this paper we fill this gap by presenting a new corpus annotated for biographical event detection. The corpus, which includes 20 Wikipedia biographies, was compared with five existing corpora to train a model for the biographical event detection task. The model was able to detect all mentions of the target-entity in a biography with an F-score of 0.808 and the entity-related events with an F-score of 0.859. Finally, the model was used for performing an analysis of biases about women and non-Western people in Wikipedia biographies.
Event Causality Identification with Causal News Corpus -- Shared Task 3, CASE 2022
Nov 22, 2022



The Event Causality Identification Shared Task of CASE 2022 involved two subtasks working on the Causal News Corpus. Subtask 1 required participants to predict if a sentence contains a causal relation or not. This is a supervised binary classification task. Subtask 2 required participants to identify the Cause, Effect and Signal spans per causal sentence. This could be seen as a supervised sequence labeling task. For both subtasks, participants uploaded their predictions for a held-out test set, and ranking was done based on binary F1 and macro F1 scores for Subtask 1 and 2, respectively. This paper summarizes the work of the 17 teams that submitted their results to our competition and 12 system description papers that were received. The best F1 scores achieved for Subtask 1 and 2 were 86.19% and 54.15%, respectively. All the top-performing approaches involved pre-trained language models fine-tuned to the targeted task. We further discuss these approaches and analyze errors across participants' systems in this paper.
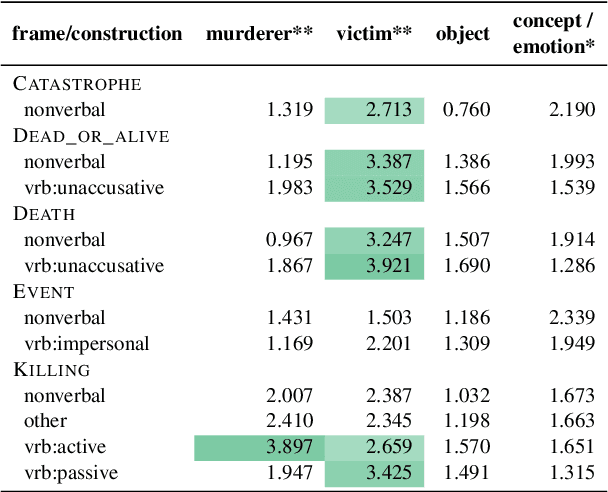
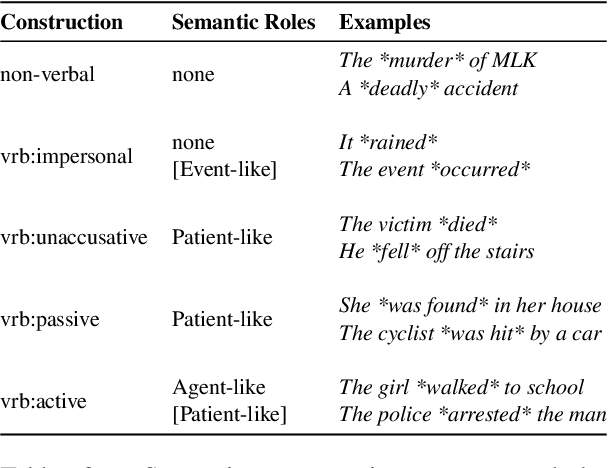
Dead or Murdered? Predicting Responsibility Perception in Femicide News Reports
Sep 24, 2022


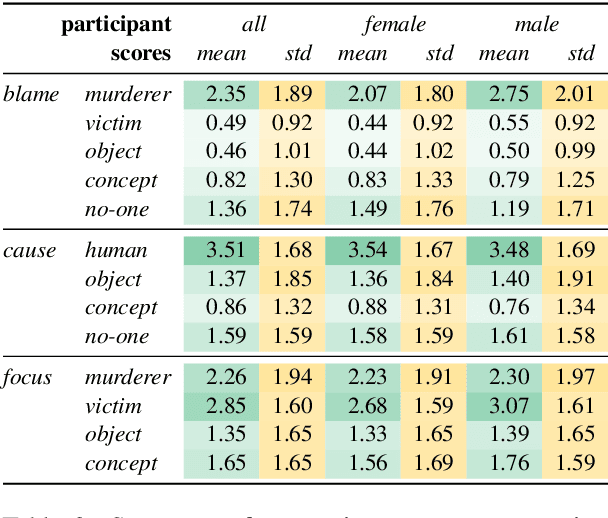
Different linguistic expressions can conceptualize the same event from different viewpoints by emphasizing certain participants over others. Here, we investigate a case where this has social consequences: how do linguistic expressions of gender-based violence (GBV) influence who we perceive as responsible? We build on previous psycholinguistic research in this area and conduct a large-scale perception survey of GBV descriptions automatically extracted from a corpus of Italian newspapers. We then train regression models that predict the salience of GBV participants with respect to different dimensions of perceived responsibility. Our best model (fine-tuned BERT) shows solid overall performance, with large differences between dimensions and participants: salient _focus_ is more predictable than salient _blame_, and perpetrators' salience is more predictable than victims' salience. Experiments with ridge regression models using different representations show that features based on linguistic theory similarly to word-based features. Overall, we show that different linguistic choices do trigger different perceptions of responsibility, and that such perceptions can be modelled automatically. This work can be a core instrument to raise awareness of the consequences of different perspectivizations in the general public and in news producers alike.
The Causal News Corpus: Annotating Causal Relations in Event Sentences from News
Apr 25, 2022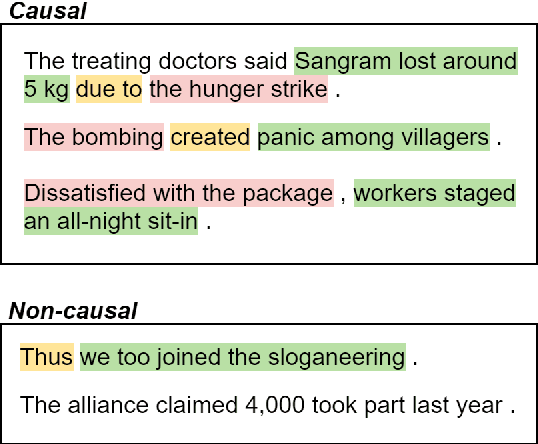
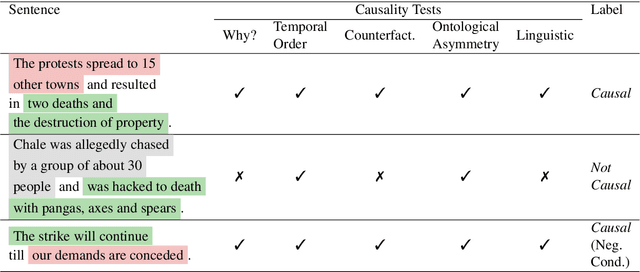
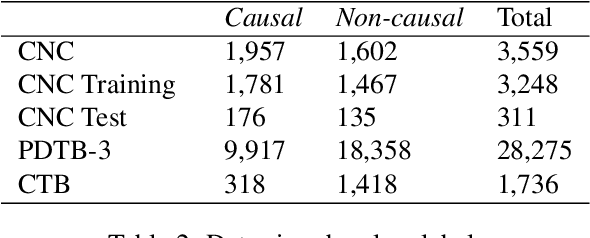
Despite the importance of understanding causality, corpora addressing causal relations are limited. There is a discrepancy between existing annotation guidelines of event causality and conventional causality corpora that focus more on linguistics. Many guidelines restrict themselves to include only explicit relations or clause-based arguments. Therefore, we propose an annotation schema for event causality that addresses these concerns. We annotated 3,559 event sentences from protest event news with labels on whether it contains causal relations or not. Our corpus is known as the Causal News Corpus (CNC). A neural network built upon a state-of-the-art pre-trained language model performed well with 81.20% F1 score on test set, and 83.46% in 5-folds cross-validation. CNC is transferable across two external corpora: CausalTimeBank (CTB) and Penn Discourse Treebank (PDTB). Leveraging each of these external datasets for training, we achieved up to approximately 64% F1 on the CNC test set without additional fine-tuning. CNC also served as an effective training and pre-training dataset for the two external corpora. Lastly, we demonstrate the difficulty of our task to the layman in a crowd-sourced annotation exercise. Our annotated corpus is publicly available, providing a valuable resource for causal text mining researchers.
SOCIOFILLMORE: A Tool for Discovering Perspectives
Mar 07, 2022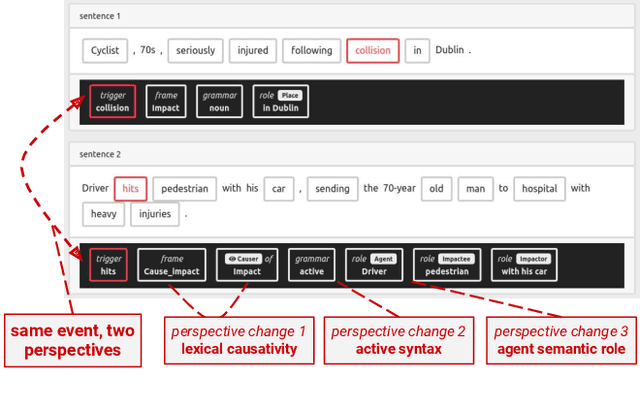
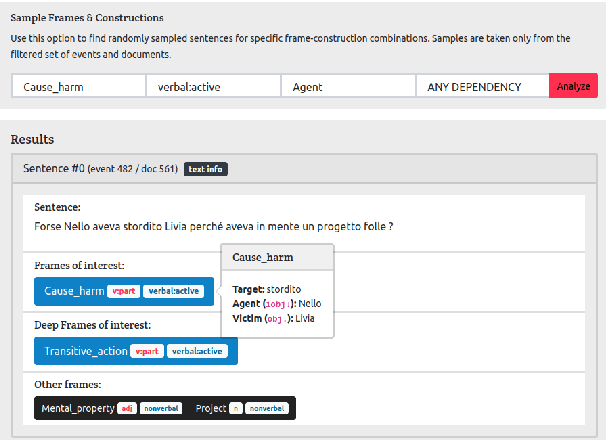
SOCIOFILLMORE is a multilingual tool which helps to bring to the fore the focus or the perspective that a text expresses in depicting an event. Our tool, whose rationale we also support through a large collection of human judgements, is theoretically grounded on frame semantics and cognitive linguistics, and implemented using the LOME frame semantic parser. We describe SOCIOFILLMORE's development and functionalities, show how non-NLP researchers can easily interact with the tool, and present some example case studies which are already incorporated in the system, together with the kind of analysis that can be visualised.
Fighting the COVID-19 Infodemic with a Holistic BERT Ensemble
Apr 12, 2021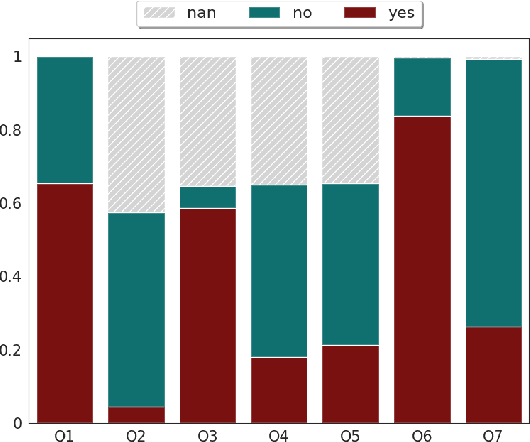
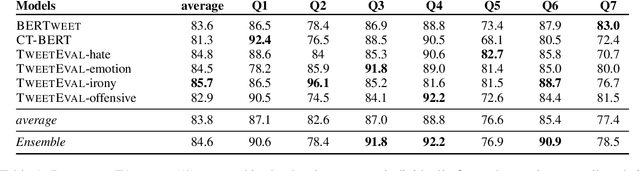
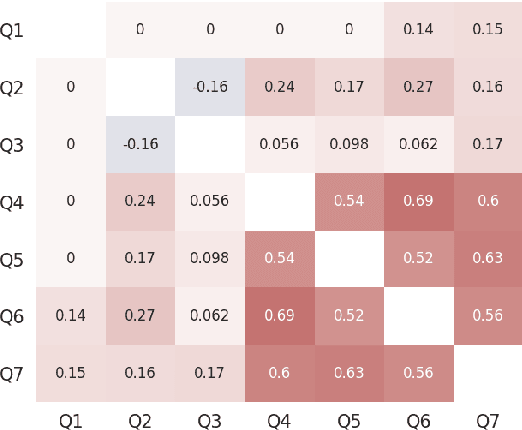
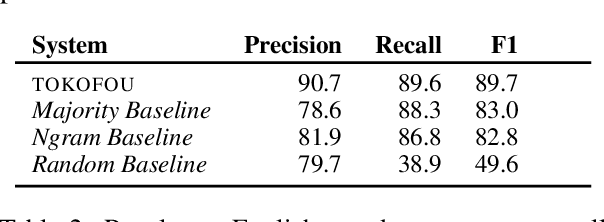
This paper describes the TOKOFOU system, an ensemble model for misinformation detection tasks based on six different transformer-based pre-trained encoders, implemented in the context of the COVID-19 Infodemic Shared Task for English. We fine tune each model on each of the task's questions and aggregate their prediction scores using a majority voting approach. TOKOFOU obtains an overall F1 score of 89.7%, ranking first.