 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikibio: a Semantic Resource for the Intersectional Analysis of Biographical Events
Jun 15, 2023Biographical event detection is a relevant task for the exploration and comparison of the ways in which people's lives are told and represented. In this sense, it may support several applications in digital humanities and in works aimed at exploring bias about minoritized groups. Despite that, there are no corpora and models specifically designed for this task. In this paper we fill this gap by presenting a new corpus annotated for biographical event detection. The corpus, which includes 20 Wikipedia biographies, was compared with five existing corpora to train a model for the biographical event detection task. The model was able to detect all mentions of the target-entity in a biography with an F-score of 0.808 and the entity-related events with an F-score of 0.859. Finally, the model was used for performing an analysis of biases about women and non-Western people in Wikipedia biographies.
Guidelines and a Corpus for Extracting Biographical Events
Jun 07, 2022
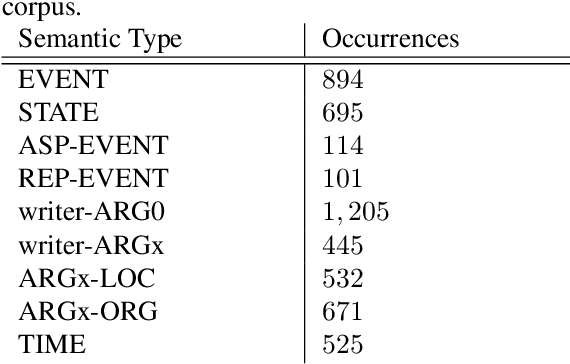
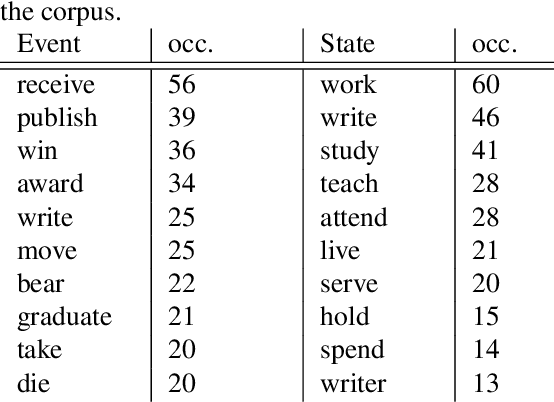
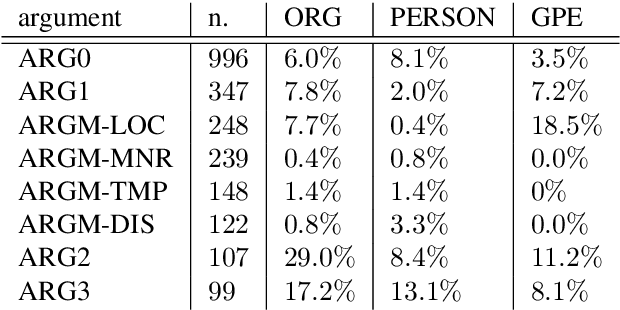
Despite biographies are widely spread within the Semantic Web, resources and approaches to automatically extract biographical events are limited. Such limitation reduces the amount of structured, machine-readable biographical information, especially about people belonging to underrepresented groups. Our work challenges this limitation by providing a set of guidelines for the semantic annotation of life events. The guidelines are designed to be interoperable with existing ISO-standards for semantic annotation: ISO-TimeML (ISO-24617-1), and SemAF (ISO-24617-4). Guidelines were tested through an annotation task of Wikipedia biographies of underrepresented writers, namely authors born in non-Western countries, migrants, or belonging to ethnic minorities. 1,000 sentences were annotated by 4 annotators with an average Inter-Annotator Agreement of 0.825. The resulting corpus was mapped on OntoNotes. Such mapping allowed to to expand our corpus, showing that already existing resources may be exploited for the biographical event extraction task.