 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the First Workshop on Language Models for Low-Resource Languages (LoResLM 2025)
Dec 20, 2024


The first Workshop on Language Models for Low-Resource Languages (LoResLM 2025) was held in conjunction with the 31st International Conference on Computational Linguistics (COLING 2025) in Abu Dhabi, United Arab Emirates. This workshop mainly aimed to provide a forum for researchers to share and discuss their ongoing work on language models (LMs) focusing on low-resource languages, following the recent advancements in neural language models and their linguistic biases towards high-resource languages. LoResLM 2025 attracted notable interest from the natural language processing (NLP) community, resulting in 35 accepted papers from 52 submissions. These contributions cover a broad range of low-resource languages from eight language families and 13 diverse research areas, paving the way for future possibilities and promoting linguistic inclusivity in NLP.
PHAnToM: Personality Has An Effect on Theory-of-Mind Reasoning in Large Language Models
Mar 04, 2024



Recent advances in large language models (LLMs) demonstrate that their capabilities are comparable, or even superior, to humans in many tasks in natural language processing. Despite this progress, LLMs are still inadequate at social-cognitive reasoning, which humans are naturally good at. Drawing inspiration from psychological research on the links between certain personality traits and Theory-of-Mind (ToM) reasoning, and from prompt engineering research on the hyper-sensitivity of prompts in affecting LLMs capabilities, this study investigates how inducing personalities in LLMs using prompts affects their ToM reasoning capabilities. Our findings show that certain induced personalities can significantly affect the LLMs' reasoning capabilities in three different ToM tasks. In particular, traits from the Dark Triad have a larger variable effect on LLMs like GPT-3.5, Llama 2, and Mistral across the different ToM tasks. We find that LLMs that exhibit a higher variance across personality prompts in ToM also tends to be more controllable in personality tests: personality traits in LLMs like GPT-3.5, Llama 2 and Mistral can be controllably adjusted through our personality prompts. In today's landscape where role-play is a common strategy when using LLMs, our research highlights the need for caution, as models that adopt specific personas with personalities potentially also alter their reasoning abilities in an unexpected manner.
Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
Mar 01, 2024Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2023): Workshop and Shared Task Report
Dec 02, 2023We provide a summary of the sixth edition of the CASE workshop that is held in the scope of RANLP 2023. The workshop consists of regular papers, three keynotes, working papers of shared task participants, and shared task overview papers. This workshop series has been bringing together all aspects of event information collection across technical and social science fields. In addition to contributing to the progress in text based event extraction, the workshop provides a space for the organization of a multimodal event information collection task.
Constructing and Interpreting Causal Knowledge Graphs from News
May 16, 2023Many jobs rely on news to learn about causal events in the past and present, to make informed decisions and predictions about the future. With the ever-increasing amount of news and text available on the internet, there is a need to automate the extraction of causal events from unstructured texts. In this work, we propose a methodology to construct causal knowledge graphs (KGs) from news using two steps: (1) Extraction of Causal Relations, and (2) Argument Clustering and Representation into KG. We aim to build graphs that emphasize on recall, precision and interpretability. For extraction, although many earlier works already construct causal KGs from text, most adopt rudimentary pattern-based methods. We close this gap by using the latest BERT-based extraction models alongside pattern-based ones. As a result, we achieved a high recall, while still maintaining a high precision. For clustering, we utilized a topic modelling approach to cluster our arguments, so as to increase the connectivity of our graph. As a result, instead of 15,686 disconnected subgraphs, we were able to obtain 1 connected graph that enables users to infer more causal relationships from. Our final KG effectively captures and conveys causal relationships, validated through multiple use cases and user feedback.
Event Causality Identification with Causal News Corpus -- Shared Task 3, CASE 2022
Nov 22, 2022



The Event Causality Identification Shared Task of CASE 2022 involved two subtasks working on the Causal News Corpus. Subtask 1 required participants to predict if a sentence contains a causal relation or not. This is a supervised binary classification task. Subtask 2 required participants to identify the Cause, Effect and Signal spans per causal sentence. This could be seen as a supervised sequence labeling task. For both subtasks, participants uploaded their predictions for a held-out test set, and ranking was done based on binary F1 and macro F1 scores for Subtask 1 and 2, respectively. This paper summarizes the work of the 17 teams that submitted their results to our competition and 12 system description papers that were received. The best F1 scores achieved for Subtask 1 and 2 were 86.19% and 54.15%, respectively. All the top-performing approaches involved pre-trained language models fine-tuned to the targeted task. We further discuss these approaches and analyze errors across participants' systems in this paper.
UniCausal: Unified Benchmark and Model for Causal Text Mining
Aug 19, 2022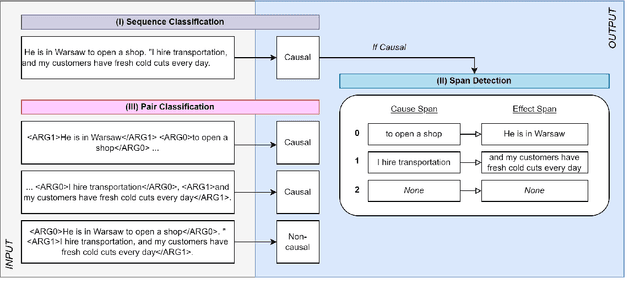

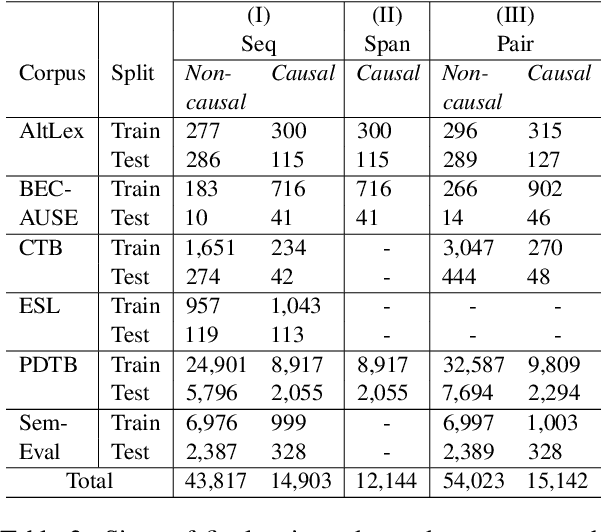
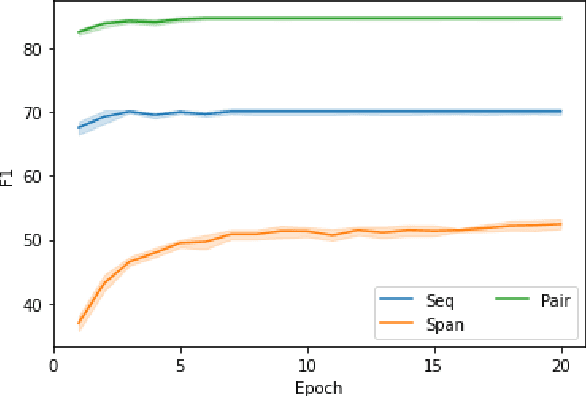
Current causal text mining datasets vary in objectives, data coverage, and annotation schemes. These inconsistent efforts prevented modeling capabilities and fair comparisons of model performance. Few datasets include cause-effect span annotations, which are needed for end-to-end causal extraction. Therefore, we proposed UniCausal, a unified benchmark for causal text mining across three tasks: Causal Sequence Classification, Cause-Effect Span Detection and Causal Pair Classification. We consolidated and aligned annotations of six high quality human-annotated corpus, resulting in a total of 58,720, 12,144 and 69,165 examples for each task respectively. Since the definition of causality can be subjective, our framework was designed to allow researchers to work on some or all datasets and tasks. As an initial benchmark, we adapted BERT pre-trained models to our task and generated baseline scores. We achieved 70.10% Binary F1 score for Sequence Classification, 52.42% Macro F1 score for Span Detection, and 84.68% Binary F1 score for Pair Classification.
The Causal News Corpus: Annotating Causal Relations in Event Sentences from News
Apr 25, 2022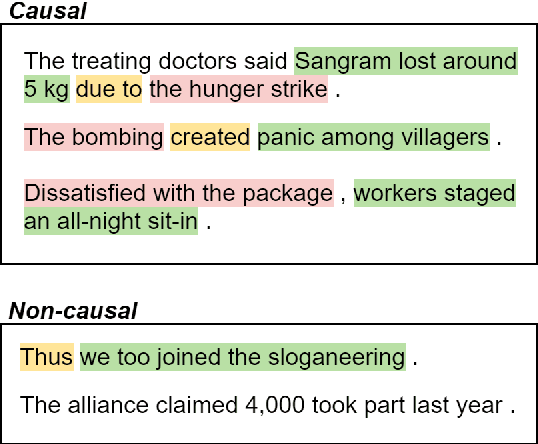
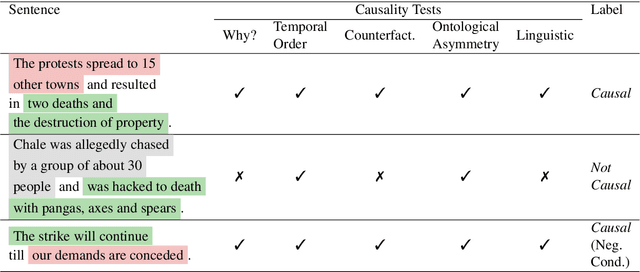
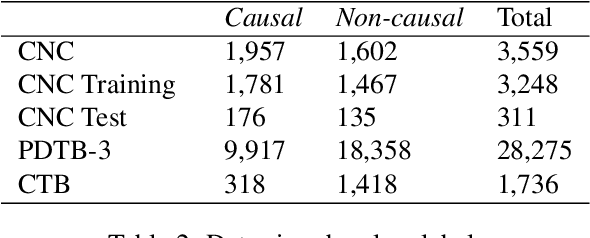
Despite the importance of understanding causality, corpora addressing causal relations are limited. There is a discrepancy between existing annotation guidelines of event causality and conventional causality corpora that focus more on linguistics. Many guidelines restrict themselves to include only explicit relations or clause-based arguments. Therefore, we propose an annotation schema for event causality that addresses these concerns. We annotated 3,559 event sentences from protest event news with labels on whether it contains causal relations or not. Our corpus is known as the Causal News Corpus (CNC). A neural network built upon a state-of-the-art pre-trained language model performed well with 81.20% F1 score on test set, and 83.46% in 5-folds cross-validation. CNC is transferable across two external corpora: CausalTimeBank (CTB) and Penn Discourse Treebank (PDTB). Leveraging each of these external datasets for training, we achieved up to approximately 64% F1 on the CNC test set without additional fine-tuning. CNC also served as an effective training and pre-training dataset for the two external corpora. Lastly, we demonstrate the difficulty of our task to the layman in a crowd-sourced annotation exercise. Our annotated corpus is publicly available, providing a valuable resource for causal text mining researchers.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
NUS-IDS at FinCausal 2021: Dependency Tree in Graph Neural Network for Better Cause-Effect Span Detection
Oct 06, 2021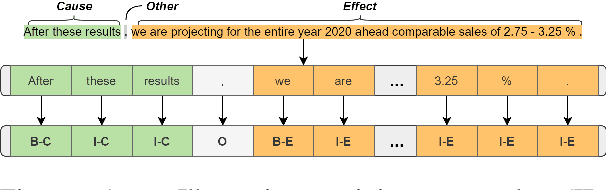
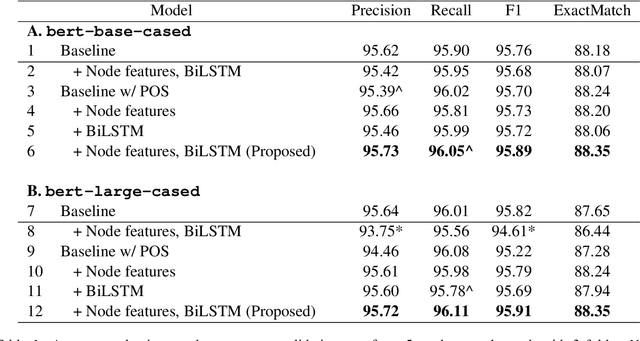
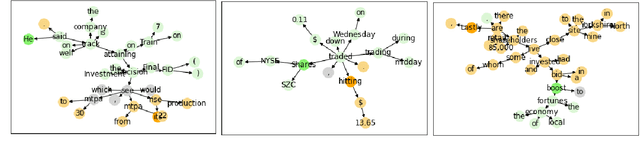
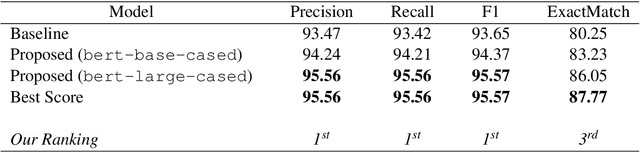
Automatic identification of cause-effect spans in financial documents is important for causality modelling and understanding reasons that lead to financial events. To exploit the observation that words are more connected to other words with the same cause-effect type in a dependency tree, we construct useful graph embeddings by incorporating dependency relation features through a graph neural network. Our model builds on a baseline BERT token classifier with Viterbi decoding, and outperforms this baseline in cross-validation and during the competition. In the official run of FinCausal 2021, we obtained Precision, Recall, and F1 scores of 95.56%, 95.56% and 95.57% that all ranked 1st place, and an Exact Match score of 86.05% which ranked 3rd place.