 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-knowledge LLM hallucination detection and mitigation through fine-grained cross-model consistency
Aug 19, 2025Large language models (LLMs) have demonstrated impressive capabilities across diverse tasks, but they remain susceptible to hallucinations--generating content that appears plausible but contains factual inaccuracies. We present Finch-Zk, a black-box framework that leverages FINe-grained Cross-model consistency to detect and mitigate Hallucinations in LLM outputs without requiring external knowledge sources. Finch-Zk introduces two key innovations: 1) a cross-model consistency checking strategy that reveals fine-grained inaccuracies by comparing responses generated by diverse models from semantically-equivalent prompts, and 2) a targeted mitigation technique that applies precise corrections to problematic segments while preserving accurate content. Experiments on the FELM dataset show Finch-Zk improves hallucination detection F1 scores by 6-39\% compared to existing approaches. For mitigation, Finch-Zk achieves 7-8 absolute percentage points improvement in answer accuracy on the GPQA-diamond dataset when applied to state-of-the-art models like Llama 4 Maverick and Claude 4 Sonnet. Extensive evaluation across multiple models demonstrates that Finch-Zk provides a practical, deployment-ready safeguard for enhancing factual reliability in production LLM systems.
Augmented Adversarial Trigger Learning
Mar 16, 2025Gradient optimization-based adversarial attack methods automate the learning of adversarial triggers to generate jailbreak prompts or leak system prompts. In this work, we take a closer look at the optimization objective of adversarial trigger learning and propose ATLA: Adversarial Trigger Learning with Augmented objectives. ATLA improves the negative log-likelihood loss used by previous studies into a weighted loss formulation that encourages the learned adversarial triggers to optimize more towards response format tokens. This enables ATLA to learn an adversarial trigger from just one query-response pair and the learned trigger generalizes well to other similar queries. We further design a variation to augment trigger optimization with an auxiliary loss that suppresses evasive responses. We showcase how to use ATLA to learn adversarial suffixes jailbreaking LLMs and to extract hidden system prompts. Empirically we demonstrate that ATLA consistently outperforms current state-of-the-art techniques, achieving nearly 100% success in attacking while requiring 80% fewer queries. ATLA learned jailbreak suffixes demonstrate high generalization to unseen queries and transfer well to new LLMs.
TurboFuzzLLM: Turbocharging Mutation-based Fuzzing for Effectively Jailbreaking Large Language Models in Practice
Feb 21, 2025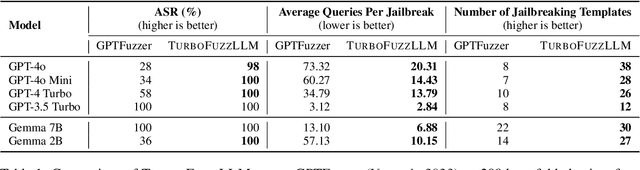
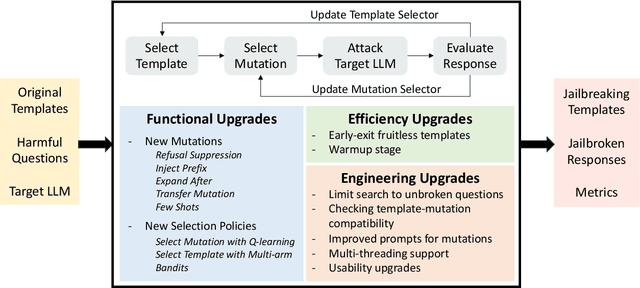


Jailbreaking large-language models (LLMs) involves testing their robustness against adversarial prompts and evaluating their ability to withstand prompt attacks that could elicit unauthorized or malicious responses. In this paper, we present TurboFuzzLLM, a mutation-based fuzzing technique for efficiently finding a collection of effective jailbreaking templates that, when combined with harmful questions, can lead a target LLM to produce harmful responses through black-box access via user prompts. We describe the limitations of directly applying existing template-based attacking techniques in practice, and present functional and efficiency-focused upgrades we added to mutation-based fuzzing to generate effective jailbreaking templates automatically. TurboFuzzLLM achieves $\geq$ 95\% attack success rates (ASR) on public datasets for leading LLMs (including GPT-4o \& GPT-4 Turbo), shows impressive generalizability to unseen harmful questions, and helps in improving model defenses to prompt attacks.
Preference Optimization via Contrastive Divergence: Your Reward Model is Secretly an NLL Estimator
Feb 06, 2025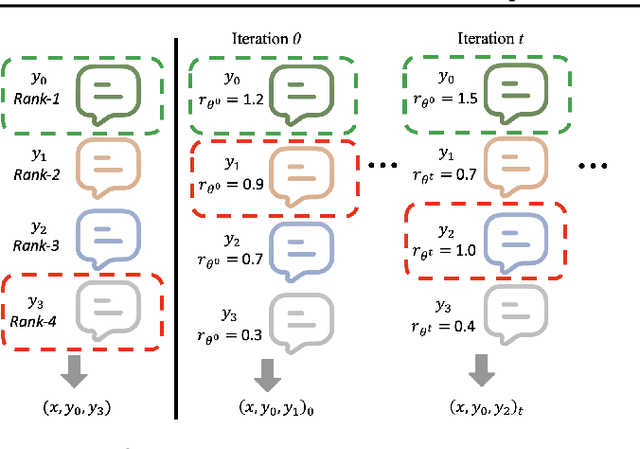
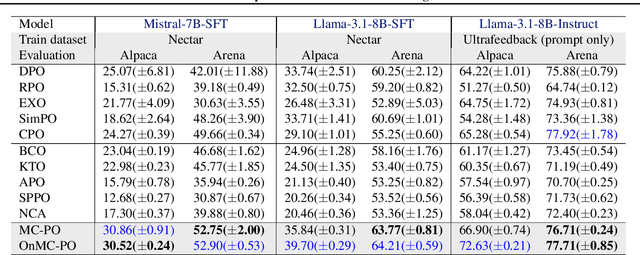
Existing studies on preference optimization (PO) have centered on constructing pairwise preference data following simple heuristics, such as maximizing the margin between preferred and dispreferred completions based on human (or AI) ranked scores. However, none of these heuristics has a full theoretical justification. In this work, we develop a novel PO framework that provides theoretical guidance to effectively sample dispreferred completions. To achieve this, we formulate PO as minimizing the negative log-likelihood (NLL) of a probability model and propose to estimate its normalization constant via a sampling strategy. As we will demonstrate, these estimative samples can act as dispreferred completions in PO. We then select contrastive divergence (CD) as the sampling strategy, and propose a novel MC-PO algorithm that applies the Monte Carlo (MC) kernel from CD to sample hard negatives w.r.t. the parameterized reward model. Finally, we propose the OnMC-PO algorithm, an extension of MC-PO to the online setting. On popular alignment benchmarks, MC-PO outperforms existing SOTA baselines, and OnMC-PO leads to further improvement.
Graph of Attacks with Pruning: Optimizing Stealthy Jailbreak Prompt Generation for Enhanced LLM Content Moderation
Jan 28, 2025We present a modular pipeline that automates the generation of stealthy jailbreak prompts derived from high-level content policies, enhancing LLM content moderation. First, we address query inefficiency and jailbreak strength by developing Graph of Attacks with Pruning (GAP), a method that utilizes strategies from prior jailbreaks, resulting in 92% attack success rate on GPT-3.5 using only 54% of the queries of the prior algorithm. Second, we address the cold-start issue by automatically generating seed prompts from the high-level policy using LLMs. Finally, we demonstrate the utility of these generated jailbreak prompts of improving content moderation by fine-tuning PromptGuard, a model trained to detect jailbreaks, increasing its accuracy on the Toxic-Chat dataset from 5.1% to 93.89%.
AIDE: Task-Specific Fine Tuning with Attribute Guided Multi-Hop Data Expansion
Dec 09, 2024



Fine-tuning large language models (LLMs) for specific tasks requires high-quality, diverse training data relevant to the task. Recent research has leveraged LLMs to synthesize training data, but existing approaches either depend on large seed datasets or struggle to ensure both task relevance and data diversity in the generated outputs. To address these challenges, we propose AIDE, a novel data synthesis framework that uses a multi-hop process to expand 10 seed data points while ensuring diversity and task relevance. AIDE extracts the main topic and key knowledge attributes from the seed data to guide the synthesis process. In each subsequent hop, it extracts the topic and attributes from the newly generated data and continues guided synthesis. This process repeats for a total of K hops. To prevent irrelevant data generation as the hop depth increases, AIDE incorporates a residual connection mechanism and uses self-reflection to improve data quality. Our empirical results demonstrate that fine-tuning Mistral-7B, Llama-3.1-8B and Llama-3.2-3B with AIDE achieves more than 10% accuracy improvements over the base models across 13 tasks from 5 different benchmarks, while outperforming the models fine-tuned with state-of-the-art data synthesis methods like Evol-Instruct, DataTune and Prompt2Model.
Hierarchical Prompt Decision Transformer: Improving Few-Shot Policy Generalization with Global and Adaptive
Dec 01, 2024



Decision transformers recast reinforcement learning as a conditional sequence generation problem, offering a simple but effective alternative to traditional value or policy-based methods. A recent key development in this area is the integration of prompting in decision transformers to facilitate few-shot policy generalization. However, current methods mainly use static prompt segments to guide rollouts, limiting their ability to provide context-specific guidance. Addressing this, we introduce a hierarchical prompting approach enabled by retrieval augmentation. Our method learns two layers of soft tokens as guiding prompts: (1) global tokens encapsulating task-level information about trajectories, and (2) adaptive tokens that deliver focused, timestep-specific instructions. The adaptive tokens are dynamically retrieved from a curated set of demonstration segments, ensuring context-aware guidance. Experiments across seven benchmark tasks in the MuJoCo and MetaWorld environments demonstrate the proposed approach consistently outperforms all baseline methods, suggesting that hierarchical prompting for decision transformers is an effective strategy to enable few-shot policy generalization.
Towards Improved Preference Optimization Pipeline: from Data Generation to Budget-Controlled Regularization
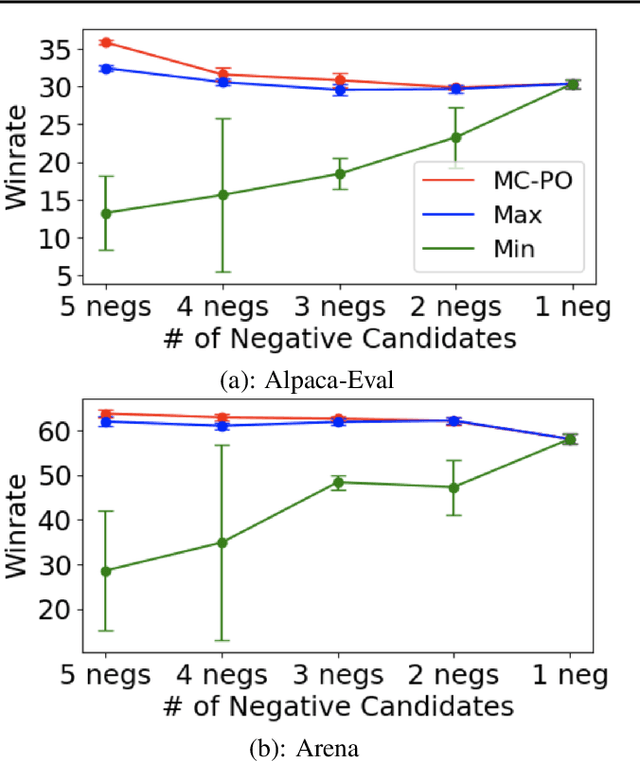
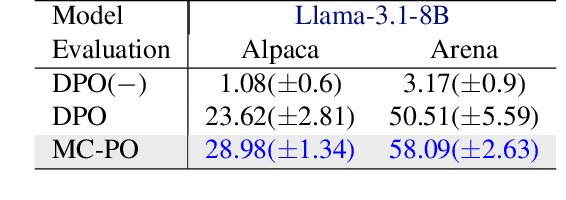
Nov 07, 2024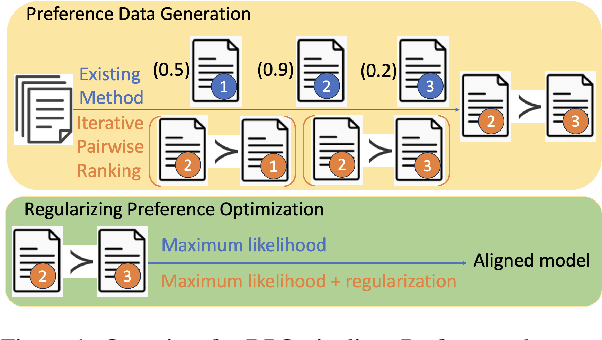

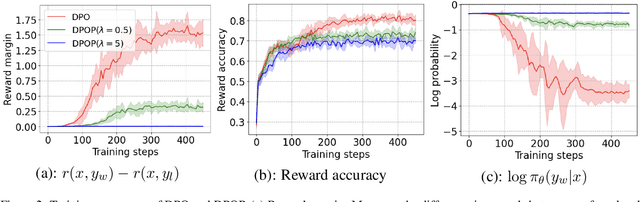
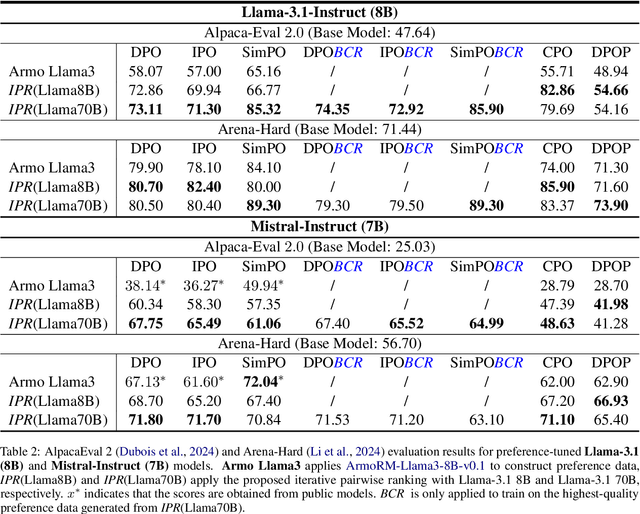
Direct Preference Optimization (DPO) and its variants have become the de facto standards for aligning large language models (LLMs) with human preferences or specific goals. However, DPO requires high-quality preference data and suffers from unstable preference optimization. In this work, we aim to improve the preference optimization pipeline by taking a closer look at preference data generation and training regularization techniques. For preference data generation, we demonstrate that existing scoring-based reward models produce unsatisfactory preference data and perform poorly on out-of-distribution tasks. This significantly impacts the LLM alignment performance when using these data for preference tuning. To ensure high-quality preference data generation, we propose an iterative pairwise ranking mechanism that derives preference ranking of completions using pairwise comparison signals. For training regularization, we observe that preference optimization tends to achieve better convergence when the LLM predicted likelihood of preferred samples gets slightly reduced. However, the widely used supervised next-word prediction regularization strictly prevents any likelihood reduction of preferred samples. This observation motivates our design of a budget-controlled regularization formulation. Empirically we show that combining the two designs leads to aligned models that surpass existing SOTA across two popular benchmarks.
DFlow: Diverse Dialogue Flow Simulation with Large Language Models
Oct 18, 2024Developing language model-based dialogue agents requires effective data to train models that can follow specific task logic. However, most existing data augmentation methods focus on increasing diversity in language, topics, or dialogue acts at the utterance level, largely neglecting a critical aspect of task logic diversity at the dialogue level. This paper proposes a novel data augmentation method designed to enhance the diversity of synthetic dialogues by focusing on task execution logic. Our method uses LLMs to generate decision tree-structured task plans, which enables the derivation of diverse dialogue trajectories for a given task. Each trajectory, referred to as a "dialog flow", guides the generation of a multi-turn dialogue that follows a unique trajectory. We apply this method to generate a task-oriented dialogue dataset comprising 3,886 dialogue flows across 15 different domains. We validate the effectiveness of this dataset using the next action prediction task, where models fine-tuned on our dataset outperform strong baselines, including GPT-4. Upon acceptance of this paper, we plan to release the code and data publicly.
TaeBench: Improving Quality of Toxic Adversarial Examples
Oct 08, 2024Toxicity text detectors can be vulnerable to adversarial examples - small perturbations to input text that fool the systems into wrong detection. Existing attack algorithms are time-consuming and often produce invalid or ambiguous adversarial examples, making them less useful for evaluating or improving real-world toxicity content moderators. This paper proposes an annotation pipeline for quality control of generated toxic adversarial examples (TAE). We design model-based automated annotation and human-based quality verification to assess the quality requirements of TAE. Successful TAE should fool a target toxicity model into making benign predictions, be grammatically reasonable, appear natural like human-generated text, and exhibit semantic toxicity. When applying these requirements to more than 20 state-of-the-art (SOTA) TAE attack recipes, we find many invalid samples from a total of 940k raw TAE attack generations. We then utilize the proposed pipeline to filter and curate a high-quality TAE dataset we call TaeBench (of size 264k). Empirically, we demonstrate that TaeBench can effectively transfer-attack SOTA toxicity content moderation models and services. Our experiments also show that TaeBench with adversarial training achieve significant improvements of the robustness of two toxicity detectors.