 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaSynth: Meta-Prompting-Driven Agentic Scaffolds for Diverse Synthetic Data Generation
Apr 17, 2025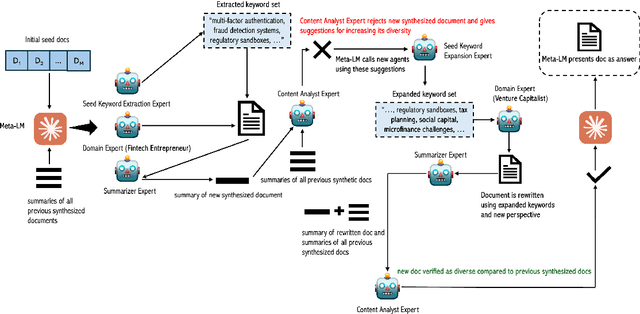



Recent smaller language models such Phi-3.5 and Phi-4 rely on synthetic data generated using larger Language models. Questions remain about leveraging synthetic data for other use cases, such as adapting LLMs to specific domains. A key limitation of synthetic data is low diversity, which negatively impacts its downstream applicability for improving other models. To address this, we propose MetaSynth, a method for generating synthetic data that enhances diversity through meta-prompting, where a language model orchestrates multiple "expert" LLM agents to collaboratively generate data. Using only 25 million tokens of synthetic data generated with MetaSynth, we successfully adapt a well-trained LLM (Mistral-7B-v0.3) to two specialized domains-Finance and Biomedicine-without compromising the capabilities of the resulting model in general tasks. In addition, we evaluate the diversity of our synthetic data using seven automated metrics, and find that it approaches the diversity of LLM pre-training corpora. Continually pre-training Mistral-7B-v0.3 with MetaSynth notably outperforms the base LLM, showing improvements of up to 4.08% in Finance and 13.75% in Biomedicine. The same model shows degraded performance when trained on data generated using a template prompt, even when the template includes prior generations and varying In-Context exemplars of real data. Our findings suggest that a few million tokens of diverse synthetic data without mixing any real data, is sufficient for effective domain adaptation when using MetaSynth.
Towards Building a Robust Toxicity Predictor
Apr 09, 2024

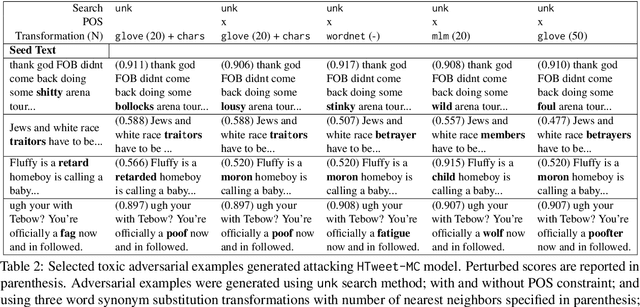

Recent NLP literature pays little attention to the robustness of toxicity language predictors, while these systems are most likely to be used in adversarial contexts. This paper presents a novel adversarial attack, \texttt{ToxicTrap}, introducing small word-level perturbations to fool SOTA text classifiers to predict toxic text samples as benign. ToxicTrap exploits greedy based search strategies to enable fast and effective generation of toxic adversarial examples. Two novel goal function designs allow ToxicTrap to identify weaknesses in both multiclass and multilabel toxic language detectors. Our empirical results show that SOTA toxicity text classifiers are indeed vulnerable to the proposed attacks, attaining over 98\% attack success rates in multilabel cases. We also show how a vanilla adversarial training and its improved version can help increase robustness of a toxicity detector even against unseen attacks.