 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Building a Robust Toxicity Predictor
Paper and Code


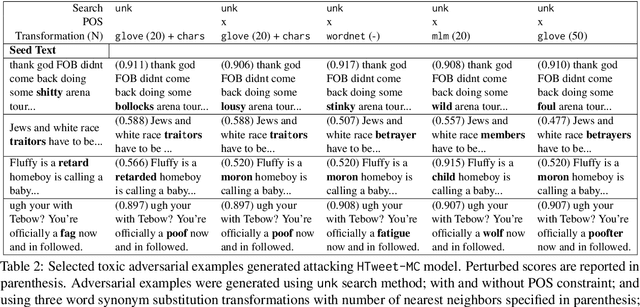

Recent NLP literature pays little attention to the robustness of toxicity language predictors, while these systems are most likely to be used in adversarial contexts. This paper presents a novel adversarial attack, \texttt{ToxicTrap}, introducing small word-level perturbations to fool SOTA text classifiers to predict toxic text samples as benign. ToxicTrap exploits greedy based search strategies to enable fast and effective generation of toxic adversarial examples. Two novel goal function designs allow ToxicTrap to identify weaknesses in both multiclass and multilabel toxic language detectors. Our empirical results show that SOTA toxicity text classifiers are indeed vulnerable to the proposed attacks, attaining over 98\% attack success rates in multilabel cases. We also show how a vanilla adversarial training and its improved version can help increase robustness of a toxicity detector even against unseen attacks.