 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Unsupervised Keyword Extraction in Academic Papers through Integrating Highlights with Abstract
Apr 21, 2026Automatic keyword extraction from academic papers is a key area of interest in natural language processing and information retrieval. Although previous research has mainly focused on utilizing abstract and references for keyword extraction, this paper focuses on the highlights section - a summary describing the key findings and contributions, offering readers a quick overview of the research. Our observations indicate that highlights contain valuable keyword information that can effectively complement the abstract. To investigate the impact of incorporating highlights into unsupervised keyword extraction, we evaluate three input scenarios: using only the abstract, the highlights, and a combination of both. Experiments conducted with four unsupervised models on Computer Science (CS), Library and Information Science (LIS) datasets reveal that integrating the abstract with highlights significantly improves extraction performance. Furthermore, we examine the differences in keyword coverage and content between abstract and highlights, exploring how these variations influence extraction outcomes. The data and code are available at https://github.com/xiangyi-njust/Highlight-KPE.
PromptCL: Improving Event Representation via Prompt Template and Contrastive Learning
Apr 27, 2024The representation of events in text plays a significant role in various NLP tasks. Recent research demonstrates that contrastive learning has the ability to improve event comprehension capabilities of Pre-trained Language Models (PLMs) and enhance the performance of event representation learning. However, the efficacy of event representation learning based on contrastive learning and PLMs is limited by the short length of event texts. The length of event texts differs significantly from the text length used in the pre-training of PLMs. As a result, there is inconsistency in the distribution of text length between pre-training and event representation learning, which may undermine the learning process of event representation based on PLMs. In this study, we present PromptCL, a novel framework for event representation learning that effectively elicits the capabilities of PLMs to comprehensively capture the semantics of short event texts. PromptCL utilizes a Prompt template borrowed from prompt learning to expand the input text during Contrastive Learning. This helps in enhancing the event representation learning by providing a structured outline of the event components. Moreover, we propose Subject-Predicate-Object (SPO) word order and Event-oriented Masked Language Modeling (EventMLM) to train PLMs to understand the relationships between event components. Our experimental results demonstrate that PromptCL outperforms state-of-the-art baselines on event related tasks. Additionally, we conduct a thorough analysis and demonstrate that using a prompt results in improved generalization capabilities for event representations. Our code will be available at https://github.com/YuboFeng2023/PromptCL.
* NLPCC 2023 Best Student Paper
Towards Building a Robust Toxicity Predictor
Apr 09, 2024

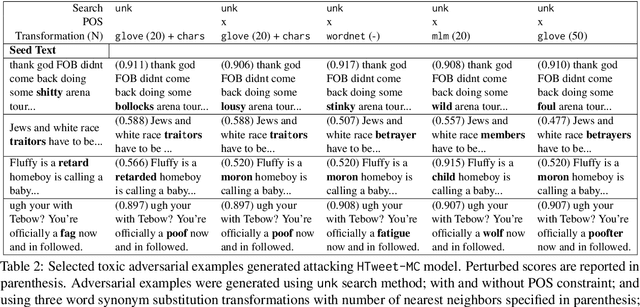

Recent NLP literature pays little attention to the robustness of toxicity language predictors, while these systems are most likely to be used in adversarial contexts. This paper presents a novel adversarial attack, \texttt{ToxicTrap}, introducing small word-level perturbations to fool SOTA text classifiers to predict toxic text samples as benign. ToxicTrap exploits greedy based search strategies to enable fast and effective generation of toxic adversarial examples. Two novel goal function designs allow ToxicTrap to identify weaknesses in both multiclass and multilabel toxic language detectors. Our empirical results show that SOTA toxicity text classifiers are indeed vulnerable to the proposed attacks, attaining over 98\% attack success rates in multilabel cases. We also show how a vanilla adversarial training and its improved version can help increase robustness of a toxicity detector even against unseen attacks.
Automatic Recognition and Classification of Future Work Sentences from Academic Articles in a Specific Domain
Dec 28, 2022



Future work sentences (FWS) are the particular sentences in academic papers that contain the author's description of their proposed follow-up research direction. This paper presents methods to automatically extract FWS from academic papers and classify them according to the different future directions embodied in the paper's content. FWS recognition methods will enable subsequent researchers to locate future work sentences more accurately and quickly and reduce the time and cost of acquiring the corpus. The current work on automatic identification of future work sentences is relatively small, and the existing research cannot accurately identify FWS from academic papers, and thus cannot conduct data mining on a large scale. Furthermore, there are many aspects to the content of future work, and the subdivision of the content is conducive to the analysis of specific development directions. In this paper, Nature Language Processing (NLP) is used as a case study, and FWS are extracted from academic papers and classified into different types. We manually build an annotated corpus with six different types of FWS. Then, automatic recognition and classification of FWS are implemented using machine learning models, and the performance of these models is compared based on the evaluation metrics. The results show that the Bernoulli Bayesian model has the best performance in the automatic recognition task, with the Macro F1 reaching 90.73%, and the SCIBERT model has the best performance in the automatic classification task, with the weighted average F1 reaching 72.63%. Finally, we extract keywords from FWS and gain a deep understanding of the key content described in FWS, and we also demonstrate that content determination in FWS will be reflected in the subsequent research work by measuring the similarity between future work sentences and the abstracts.
Imitate then Transcend: Multi-Agent Optimal Execution with Dual-Window Denoise PPO
Jun 21, 2022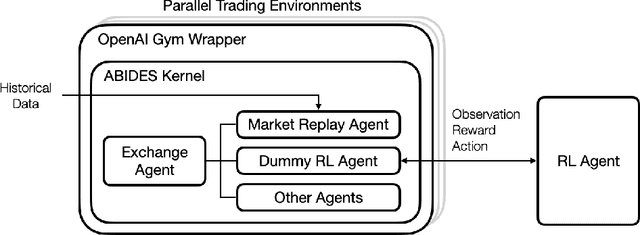
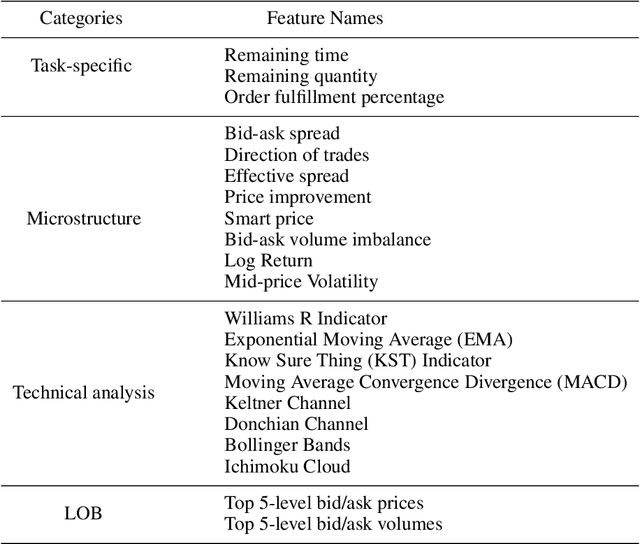
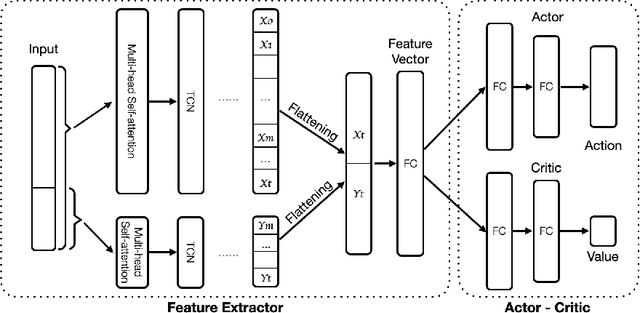
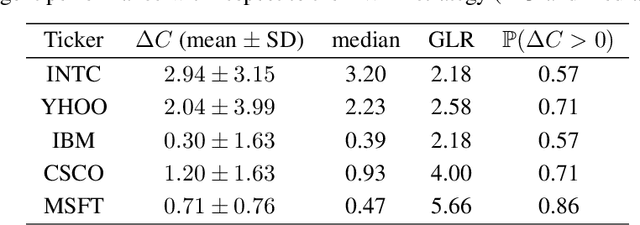
A novel framework for solving the optimal execution and placement problems using reinforcement learning (RL) with imitation was proposed. The RL agents trained from the proposed framework consistently outperformed the industry benchmark time-weighted average price (TWAP) strategy in execution cost and showed great generalization across out-of-sample trading dates and tickers. The impressive performance was achieved from three aspects. First, our RL network architecture called Dual-window Denoise PPO enabled efficient learning in a noisy market environment. Second, a reward scheme with imitation learning was designed, and a comprehensive set of market features was studied. Third, our flexible action formulation allowed the RL agent to tackle optimal execution and placement collectively resulting in better performance than solving individual problems separately. The RL agent's performance was evaluated in our multi-agent realistic historical limit order book simulator in which price impact was accurately assessed. In addition, ablation studies were also performed, confirming the superiority of our framework.