 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-Dimension Novelty: How Combinations of Theory, Method, and Results-based Novelty Shape Scientific Impact
Apr 14, 2026Scientific novelty drives advances at the research frontier, yet it is also associated with heightened uncertainty and potential resistance from incumbent paradigms, leading to complex patterns of scientific impact. Prior studies have primarily ex-amined the relationship between a single dimension of novelty -- such as theoreti-cal, methodological, or results-based novelty -- and scientific impact. However, because scientific novelty is inherently multidimensional, focusing on isolated dimensions may obscure how different types of novelty jointly shape impact. Consequently, we know little about how combinations of novelty types influence scientific impact. To this end, we draw on a dataset of 15,322 articles published in Nature Communications. Using the DeepSeek-V3 model, we classify articles into three novelty dimensions based on the content of their Introduction sections: theoretical novelty, methodological novelty, and results-based novelty. These dimensions may coexist within the same article, forming distinct novelty configura-tions. Scientific impact is measured using five-year citation counts and indicators of whether an article belongs to the top 1% or top 10% highly cited papers. Descriptive results indicate that results-based novelty alone and the simultaneous presence of all three novelty types are the dominant configurations in the sample. Regression results further show that articles with results-based novelty only re-ceive significantly more citations and are more likely to rank among the top 1% and top 10% highly cited papers than articles exhibiting all three novelty types. These findings advance our understanding of how multidimensional novelty configurations shape knowledge diffusion.
NovBench: Evaluating Large Language Models on Academic Paper Novelty Assessment
Apr 13, 2026Novelty is a core requirement in academic publishing and a central focus of peer review, yet the growing volume of submissions has placed increasing pressure on human reviewers. While large language models (LLMs), including those fine-tuned on peer review data, have shown promise in generating review comments, the absence of a dedicated benchmark has limited systematic evaluation of their ability to assess research novelty. To address this gap, we introduce NovBench, the first large-scale benchmark designed to evaluate LLMs' capability to generate novelty evaluations in support of human peer review. NovBench comprises 1,684 paper-review pairs from a leading NLP conference, including novelty descriptions extracted from paper introductions and corresponding expert-written novelty evaluations. We focus on both sources because the introduction provides a standardized and explicit articulation of novelty claims, while expert-written novelty evaluations constitute one of the current gold standards of human judgment. Furthermore, we propose a four-dimensional evaluation framework (including Relevance, Correctness, Coverage, and Clarity) to assess the quality of LLM-generated novelty evaluations. Extensive experiments on both general and specialized LLMs under different prompting strategies reveal that current models exhibit limited understanding of scientific novelty, and that fine--tuned models often suffer from instruction-following deficiencies. These findings underscore the need for targeted fine-tuning strategies that jointly improve novelty comprehension and instruction adherence.
The Effect of Gender Diversity on Scientific Team Impact: A Team Roles Perspective
Dec 29, 2025The influence of gender diversity on the success of scientific teams is of great interest to academia. However, prior findings remain inconsistent, and most studies operationalize diversity in aggregate terms, overlooking internal role differentiation. This limitation obscures a more nuanced understanding of how gender diversity shapes team impact. In particular, the effect of gender diversity across different team roles remains poorly understood. To this end, we define a scientific team as all coauthors of a paper and measure team impact through five-year citation counts. Using author contribution statements, we classified members into leadership and support roles. Drawing on more than 130,000 papers from PLOS journals, most of which are in biomedical-related disciplines, we employed multivariable regression to examine the association between gender diversity in these roles and team impact. Furthermore, we apply a threshold regression model to investigate how team size moderates this relationship. The results show that (1) the relationship between gender diversity and team impact follows an inverted U-shape for both leadership and support groups; (2) teams with an all-female leadership group and an all-male support group achieve higher impact than other team types. Interestingly, (3) the effect of leadership-group gender diversity is significantly negative for small teams but becomes positive and statistically insignificant in large teams. In contrast, the estimates for support-group gender diversity remain significant and positive, regardless of team size.
How do software citation formats evolve over time? A longitudinal analysis of R programming language packages
Jul 17, 2023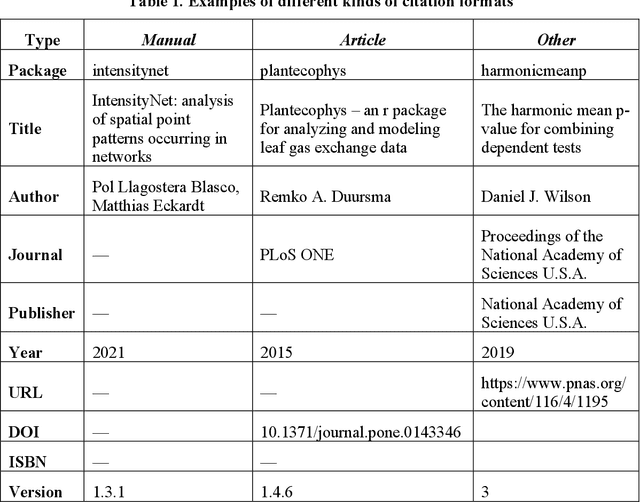
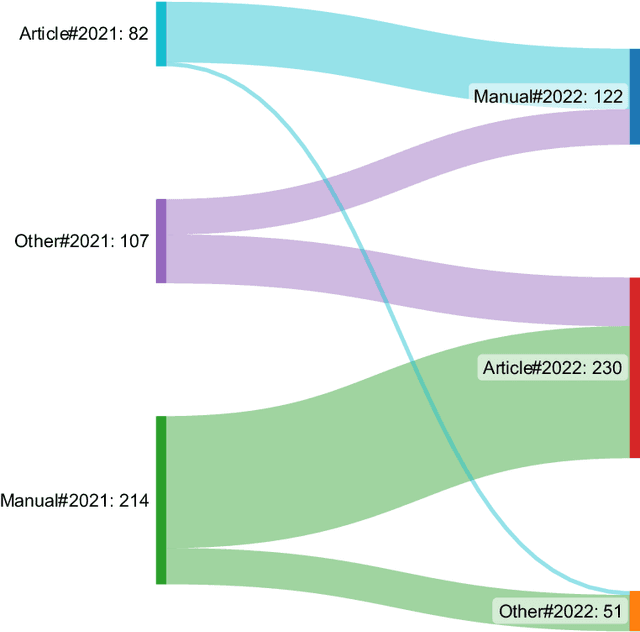
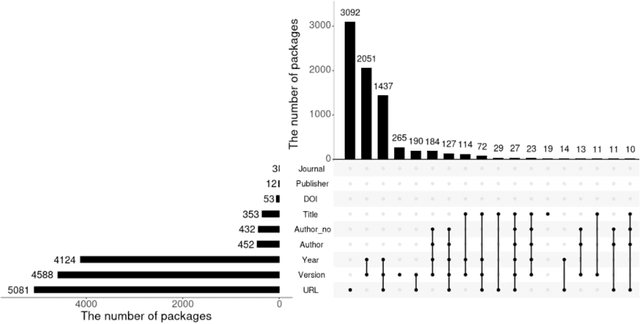
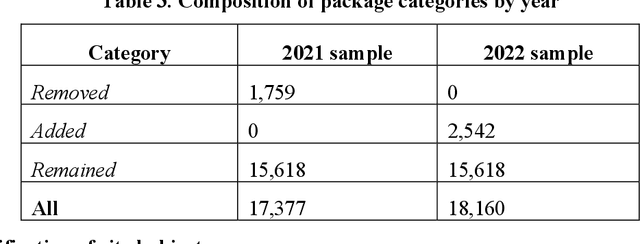
Under the data-driven research paradigm, research software has come to play crucial roles in nearly every stage of scientific inquiry. Scholars are advocating for the formal citation of software in academic publications, treating it on par with traditional research outputs. However, software is hardly consistently cited: one software entity can be cited as different objects, and the citations can change over time. These issues, however, are largely overlooked in existing empirical research on software citation. To fill the above gaps, the present study compares and analyzes a longitudinal dataset of citation formats of all R packages collected in 2021 and 2022, in order to understand the citation formats of R-language packages, important members in the open-source software family, and how the citations evolve over time. In particular, we investigate the different document types underlying the citations and what metadata elements in the citation formats changed over time. Furthermore, we offer an in-depth analysis of the disciplinarity of journal articles cited as software (software papers). By undertaking this research, we aim to contribute to a better understanding of the complexities associated with software citation, shedding light on future software citation policies and infrastructure.
Automatic Recognition and Classification of Future Work Sentences from Academic Articles in a Specific Domain
Dec 28, 2022



Future work sentences (FWS) are the particular sentences in academic papers that contain the author's description of their proposed follow-up research direction. This paper presents methods to automatically extract FWS from academic papers and classify them according to the different future directions embodied in the paper's content. FWS recognition methods will enable subsequent researchers to locate future work sentences more accurately and quickly and reduce the time and cost of acquiring the corpus. The current work on automatic identification of future work sentences is relatively small, and the existing research cannot accurately identify FWS from academic papers, and thus cannot conduct data mining on a large scale. Furthermore, there are many aspects to the content of future work, and the subdivision of the content is conducive to the analysis of specific development directions. In this paper, Nature Language Processing (NLP) is used as a case study, and FWS are extracted from academic papers and classified into different types. We manually build an annotated corpus with six different types of FWS. Then, automatic recognition and classification of FWS are implemented using machine learning models, and the performance of these models is compared based on the evaluation metrics. The results show that the Bernoulli Bayesian model has the best performance in the automatic recognition task, with the Macro F1 reaching 90.73%, and the SCIBERT model has the best performance in the automatic classification task, with the weighted average F1 reaching 72.63%. Finally, we extract keywords from FWS and gain a deep understanding of the key content described in FWS, and we also demonstrate that content determination in FWS will be reflected in the subsequent research work by measuring the similarity between future work sentences and the abstracts.
A Review on Method Entities in the Academic Literature: Extraction, Evaluation, and Application
Sep 08, 2022In scientific research, the method is an indispensable means to solve scientific problems and a critical research object. With the advancement of sciences, many scientific methods are being proposed, modified, and used in academic literature. The authors describe details of the method in the abstract and body text, and key entities in academic literature reflecting names of the method are called method entities. Exploring diverse method entities in a tremendous amount of academic literature helps scholars understand existing methods, select the appropriate method for research tasks, and propose new methods. Furthermore, the evolution of method entities can reveal the development of a discipline and facilitate knowledge discovery. Therefore, this article offers a systematic review of methodological and empirical works focusing on extracting method entities from full-text academic literature and efforts to build knowledge services using these extracted method entities. Definitions of key concepts involved in this review were first proposed. Based on these definitions, we systematically reviewed the approaches and indicators to extract and evaluate method entities, with a strong focus on the pros and cons of each approach. We also surveyed how extracted method entities are used to build new applications. Finally, limitations in existing works as well as potential next steps were discussed.
Enhancing Identification of Structure Function of Academic Articles Using Contextual Information
Dec 02, 2021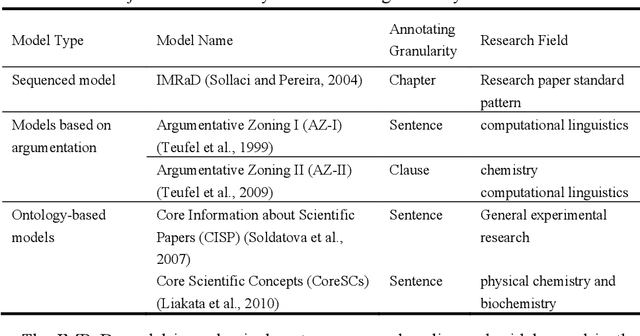
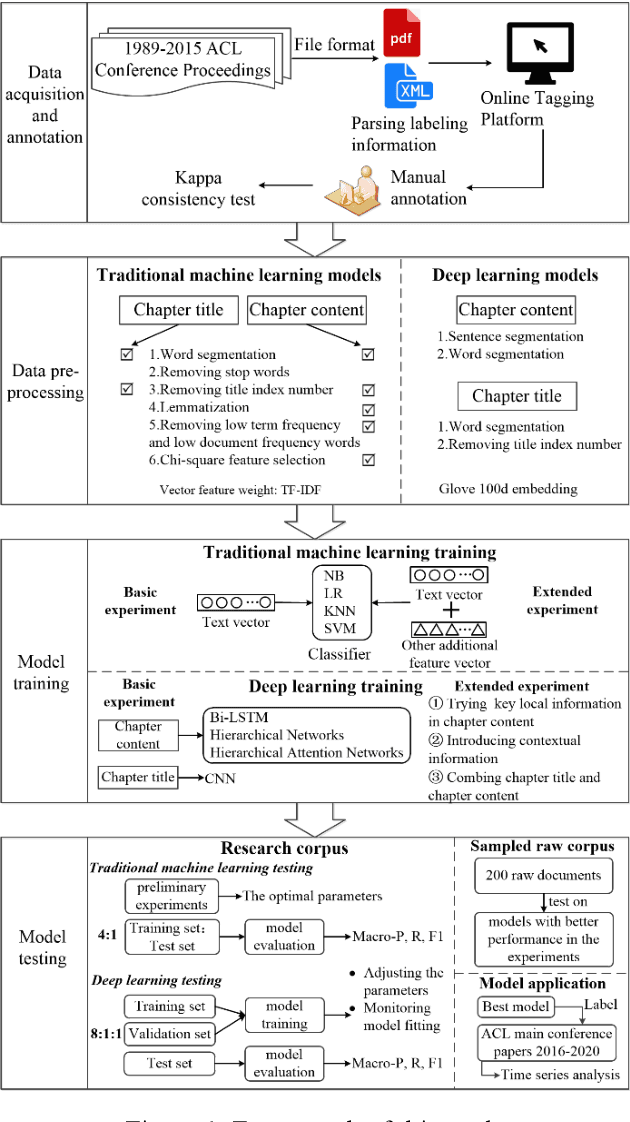
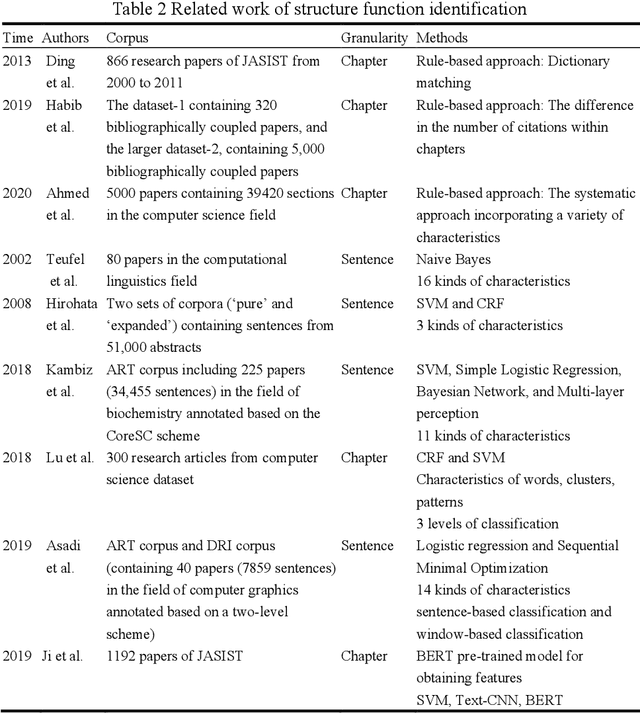
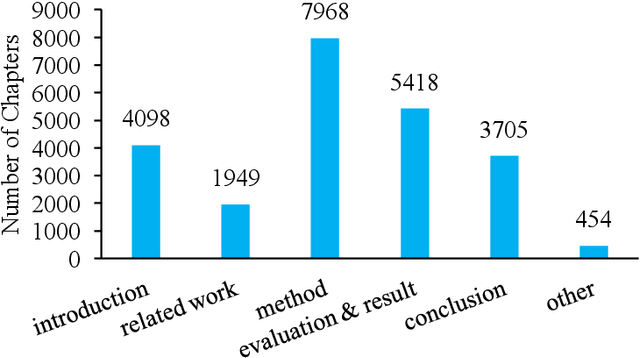
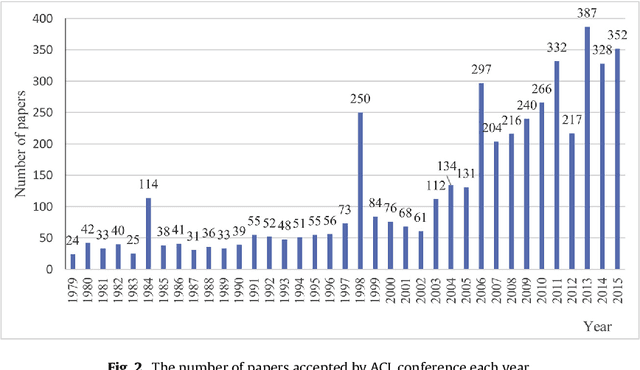
With the enrichment of literature resources, researchers are facing the growing problem of information explosion and knowledge overload. To help scholars retrieve literature and acquire knowledge successfully, clarifying the semantic structure of the content in academic literature has become the essential research question. In the research on identifying the structure function of chapters in academic articles, only a few studies used the deep learning model and explored the optimization for feature input. This limits the application, optimization potential of deep learning models for the research task. This paper took articles of the ACL conference as the corpus. We employ the traditional machine learning models and deep learning models to construct the classifiers based on various feature input. Experimental results show that (1) Compared with the chapter content, the chapter title is more conducive to identifying the structure function of academic articles. (2) Relative position is a valuable feature for building traditional models. (3) Inspired by (2), this paper further introduces contextual information into the deep learning models and achieved significant results. Meanwhile, our models show good migration ability in the open test containing 200 sampled non-training samples. We also annotated the ACL main conference papers in recent five years based on the best practice performing models and performed a time series analysis of the overall corpus. This work explores and summarizes the practical features and models for this task through multiple comparative experiments and provides a reference for related text classification tasks. Finally, we indicate the limitations and shortcomings of the current model and the direction of further optimization.
Characterizing References from Different Disciplines: A Perspective of Citation Content Analysis
Jan 19, 2021
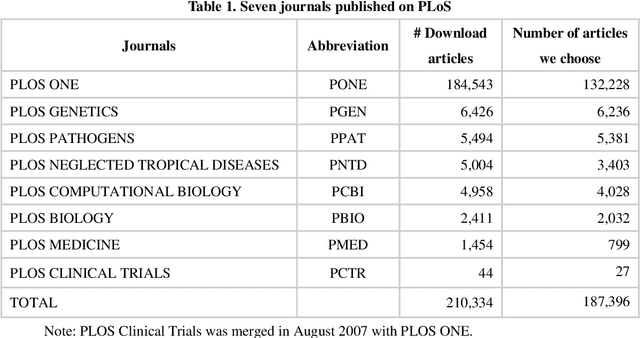
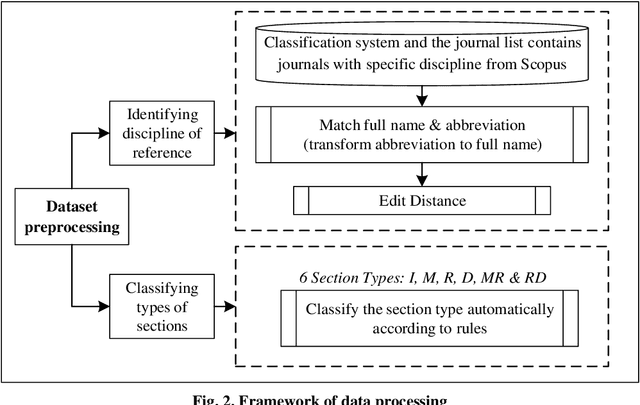
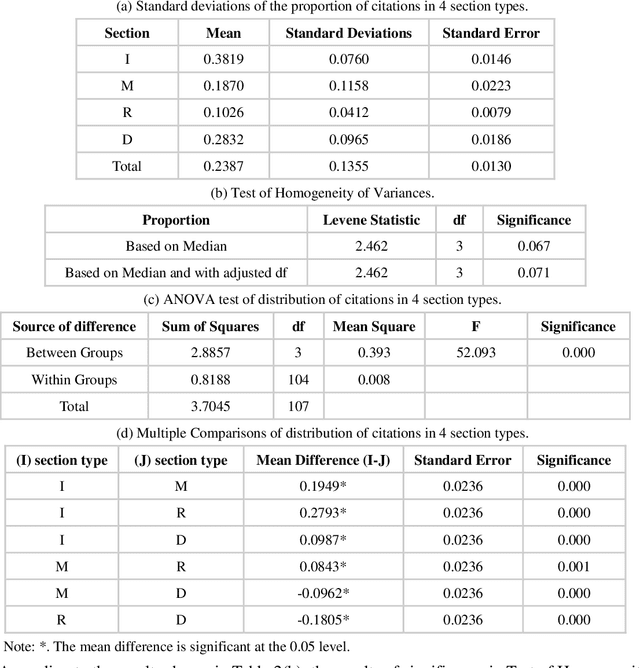
Multidisciplinary cooperation is now common in research since social issues inevitably involve multiple disciplines. In research articles, reference information, especially citation content, is an important representation of communication among different disciplines. Analyzing the distribution characteristics of references from different disciplines in research articles is basic to detecting the sources of referred information and identifying contributions of different disciplines. This work takes articles in PLoS as the data and characterizes the references from different disciplines based on Citation Content Analysis (CCA). First, we download 210,334 full-text articles from PLoS and collect the information of the in-text citations. Then, we identify the discipline of each reference in these academic articles. To characterize the distribution of these references, we analyze three characteristics, namely, the number of citations, the average cited intensity and the average citation length. Finally, we conclude that the distributions of references from different disciplines are significantly different. Although most references come from Natural Science, Humanities and Social Sciences play important roles in the Introduction and Background sections of the articles. Basic disciplines, such as Mathematics, mainly provide research methods in the articles in PLoS. Citations mentioned in the Results and Discussion sections of articles are mainly in-discipline citations, such as citations from Nursing and Medicine in PLoS.
Using the Full-text Content of Academic Articles to Identify and Evaluate Algorithm Entities in the Domain of Natural Language Processing
Oct 21, 2020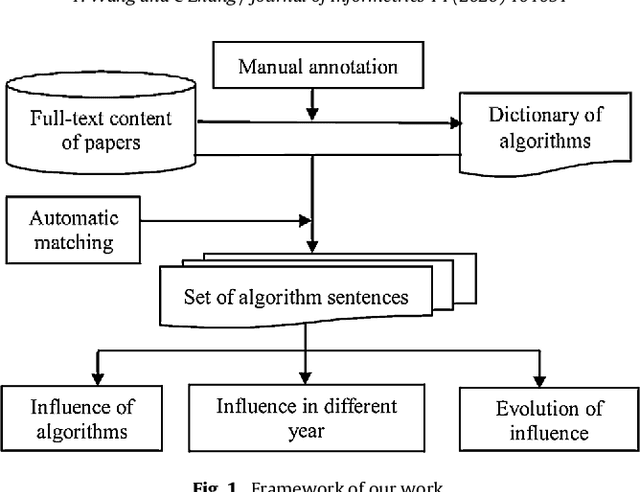
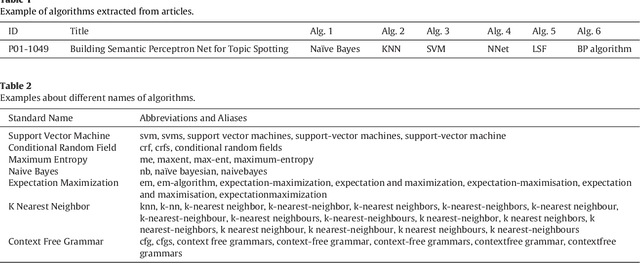
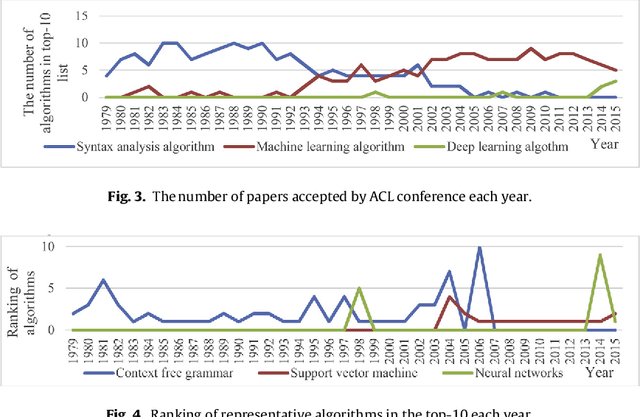
In the era of big data, the advancement, improvement, and application of algorithms in academic research have played an important role in promoting the development of different disciplines. Academic papers in various disciplines, especially computer science, contain a large number of algorithms. Identifying the algorithms from the full-text content of papers can determine popular or classical algorithms in a specific field and help scholars gain a comprehensive understanding of the algorithms and even the field. To this end, this article takes the field of natural language processing (NLP) as an example and identifies algorithms from academic papers in the field. A dictionary of algorithms is constructed by manually annotating the contents of papers, and sentences containing algorithms in the dictionary are extracted through dictionary-based matching. The number of articles mentioning an algorithm is used as an indicator to analyze the influence of that algorithm. Our results reveal the algorithm with the highest influence in NLP papers and show that classification algorithms represent the largest proportion among the high-impact algorithms. In addition, the evolution of the influence of algorithms reflects the changes in research tasks and topics in the field, and the changes in the influence of different algorithms show different trends. As a preliminary exploration, this paper conducts an analysis of the impact of algorithms mentioned in the academic text, and the results can be used as training data for the automatic extraction of large-scale algorithms in the future. The methodology in this paper is domain-independent and can be applied to other domains.
WordSup: Exploiting Word Annotations for Character based Text Detection
Aug 22, 2017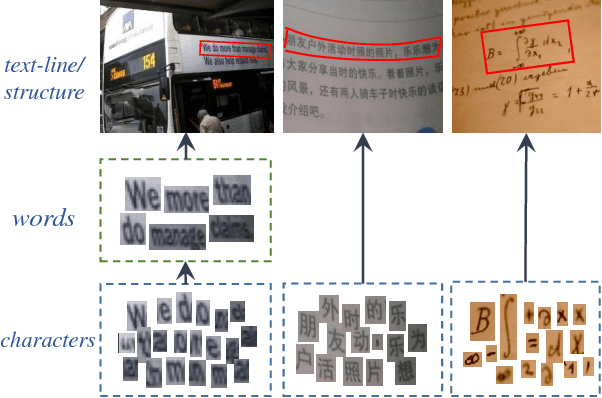
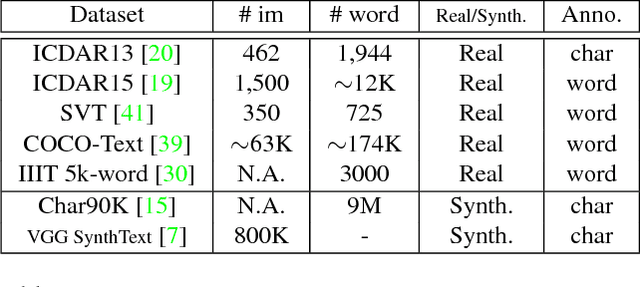
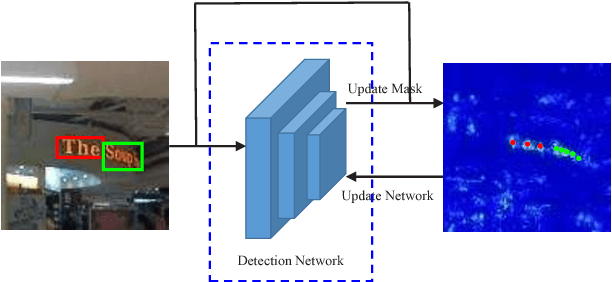
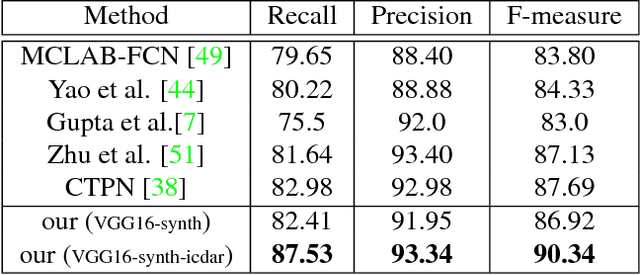
Imagery texts are usually organized as a hierarchy of several visual elements, i.e. characters, words, text lines and text blocks. Among these elements, character is the most basic one for various languages such as Western, Chinese, Japanese, mathematical expression and etc. It is natural and convenient to construct a common text detection engine based on character detectors. However, training character detectors requires a vast of location annotated characters, which are expensive to obtain. Actually, the existing real text datasets are mostly annotated in word or line level. To remedy this dilemma, we propose a weakly supervised framework that can utilize word annotations, either in tight quadrangles or the more loose bounding boxes, for character detector training. When applied in scene text detection, we are thus able to train a robust character detector by exploiting word annotations in the rich large-scale real scene text datasets, e.g. ICDAR15 and COCO-text. The character detector acts as a key role in the pipeline of our text detection engine. It achieves the state-of-the-art performance on several challenging scene text detection benchmarks. We also demonstrate the flexibility of our pipeline by various scenarios, including deformed text detection and math expression recognition.