 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Mar 25, 2025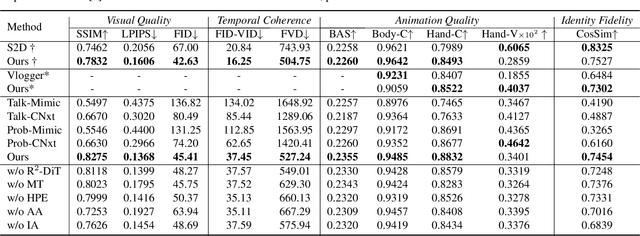
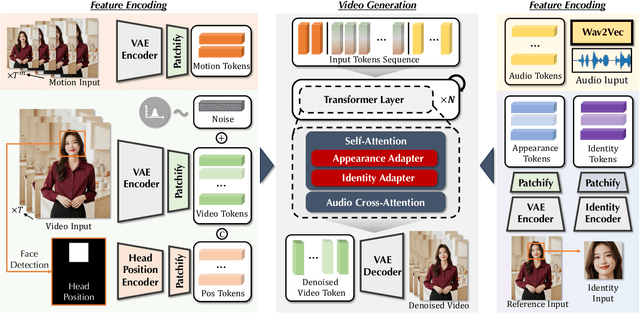
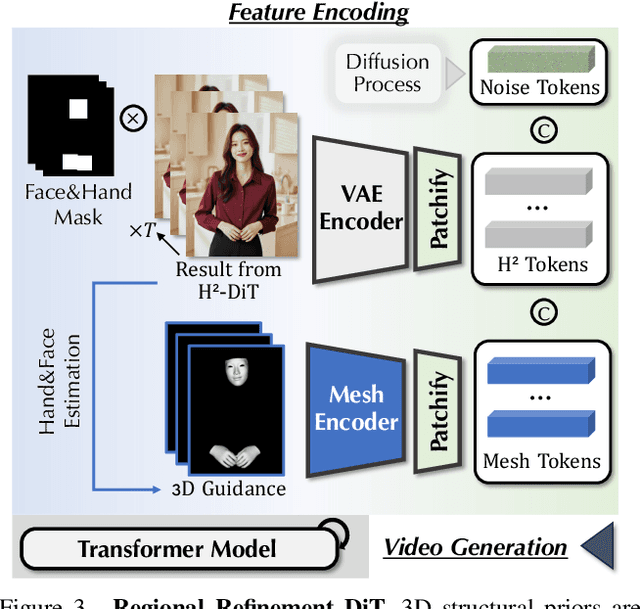

Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
Interpretable Face Anti-Spoofing: Enhancing Generalization with Multimodal Large Language Models
Jan 03, 2025



Face Anti-Spoofing (FAS) is essential for ensuring the security and reliability of facial recognition systems. Most existing FAS methods are formulated as binary classification tasks, providing confidence scores without interpretation. They exhibit limited generalization in out-of-domain scenarios, such as new environments or unseen spoofing types. In this work, we introduce a multimodal large language model (MLLM) framework for FAS, termed Interpretable Face Anti-Spoofing (I-FAS), which transforms the FAS task into an interpretable visual question answering (VQA) paradigm. Specifically, we propose a Spoof-aware Captioning and Filtering (SCF) strategy to generate high-quality captions for FAS images, enriching the model's supervision with natural language interpretations. To mitigate the impact of noisy captions during training, we develop a Lopsided Language Model (L-LM) loss function that separates loss calculations for judgment and interpretation, prioritizing the optimization of the former. Furthermore, to enhance the model's perception of global visual features, we design a Globally Aware Connector (GAC) to align multi-level visual representations with the language model. Extensive experiments on standard and newly devised One to Eleven cross-domain benchmarks, comprising 12 public datasets, demonstrate that our method significantly outperforms state-of-the-art methods.
Explanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization
Dec 25, 2024


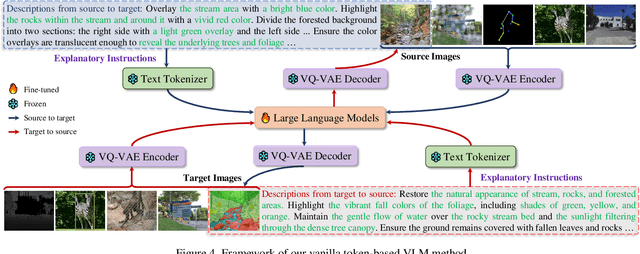
Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
The Key of Understanding Vision Tasks: Explanatory Instructions
Dec 24, 2024Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
ALoRE: Efficient Visual Adaptation via Aggregating Low Rank Experts
Dec 11, 2024



Parameter-efficient transfer learning (PETL) has become a promising paradigm for adapting large-scale vision foundation models to downstream tasks. Typical methods primarily leverage the intrinsic low rank property to make decomposition, learning task-specific weights while compressing parameter size. However, such approaches predominantly manipulate within the original feature space utilizing a single-branch structure, which might be suboptimal for decoupling the learned representations and patterns. In this paper, we propose ALoRE, a novel PETL method that reuses the hypercomplex parameterized space constructed by Kronecker product to Aggregate Low Rank Experts using a multi-branch paradigm, disentangling the learned cognitive patterns during training. Thanks to the artful design, ALoRE maintains negligible extra parameters and can be effortlessly merged into the frozen backbone via re-parameterization in a sequential manner, avoiding additional inference latency. We conduct extensive experiments on 24 image classification tasks using various backbone variants. Experimental results demonstrate that ALoRE outperforms the full fine-tuning strategy and other state-of-the-art PETL methods in terms of performance and parameter efficiency. For instance, ALoRE obtains 3.06% and 9.97% Top-1 accuracy improvement on average compared to full fine-tuning on the FGVC datasets and VTAB-1k benchmark by only updating 0.15M parameters.
Splatter-360: Generalizable 360$^{\circ}$ Gaussian Splatting for Wide-baseline Panoramic Images
Dec 09, 2024Wide-baseline panoramic images are frequently used in applications like VR and simulations to minimize capturing labor costs and storage needs. However, synthesizing novel views from these panoramic images in real time remains a significant challenge, especially due to panoramic imagery's high resolution and inherent distortions. Although existing 3D Gaussian splatting (3DGS) methods can produce photo-realistic views under narrow baselines, they often overfit the training views when dealing with wide-baseline panoramic images due to the difficulty in learning precise geometry from sparse 360$^{\circ}$ views. This paper presents \textit{Splatter-360}, a novel end-to-end generalizable 3DGS framework designed to handle wide-baseline panoramic images. Unlike previous approaches, \textit{Splatter-360} performs multi-view matching directly in the spherical domain by constructing a spherical cost volume through a spherical sweep algorithm, enhancing the network's depth perception and geometry estimation. Additionally, we introduce a 3D-aware bi-projection encoder to mitigate the distortions inherent in panoramic images and integrate cross-view attention to improve feature interactions across multiple viewpoints. This enables robust 3D-aware feature representations and real-time rendering capabilities. Experimental results on the HM3D~\cite{hm3d} and Replica~\cite{replica} demonstrate that \textit{Splatter-360} significantly outperforms state-of-the-art NeRF and 3DGS methods (e.g., PanoGRF, MVSplat, DepthSplat, and HiSplat) in both synthesis quality and generalization performance for wide-baseline panoramic images. Code and trained models are available at \url{https://3d-aigc.github.io/Splatter-360/}.
TexGaussian: Generating High-quality PBR Material via Octree-based 3D Gaussian Splatting
Nov 29, 2024
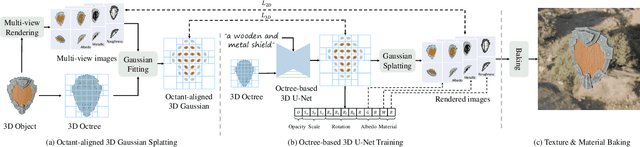


Physically Based Rendering (PBR) materials play a crucial role in modern graphics, enabling photorealistic rendering across diverse environment maps. Developing an effective and efficient algorithm that is capable of automatically generating high-quality PBR materials rather than RGB texture for 3D meshes can significantly streamline the 3D content creation. Most existing methods leverage pre-trained 2D diffusion models for multi-view image synthesis, which often leads to severe inconsistency between the generated textures and input 3D meshes. This paper presents TexGaussian, a novel method that uses octant-aligned 3D Gaussian Splatting for rapid PBR material generation. Specifically, we place each 3D Gaussian on the finest leaf node of the octree built from the input 3D mesh to render the multiview images not only for the albedo map but also for roughness and metallic. Moreover, our model is trained in a regression manner instead of diffusion denoising, capable of generating the PBR material for a 3D mesh in a single feed-forward process. Extensive experiments on publicly available benchmarks demonstrate that our method synthesizes more visually pleasing PBR materials and runs faster than previous methods in both unconditional and text-conditional scenarios, which exhibit better consistency with the given geometry. Our code and trained models are available at https://3d-aigc.github.io/TexGaussian.
TopoSD: Topology-Enhanced Lane Segment Perception with SDMap Prior
Nov 22, 2024



Recent advances in autonomous driving systems have shifted towards reducing reliance on high-definition maps (HDMaps) due to the huge costs of annotation and maintenance. Instead, researchers are focusing on online vectorized HDMap construction using on-board sensors. However, sensor-only approaches still face challenges in long-range perception due to the restricted views imposed by the mounting angles of onboard cameras, just as human drivers also rely on bird's-eye-view navigation maps for a comprehensive understanding of road structures. To address these issues, we propose to train the perception model to "see" standard definition maps (SDMaps). We encode SDMap elements into neural spatial map representations and instance tokens, and then incorporate such complementary features as prior information to improve the bird's eye view (BEV) feature for lane geometry and topology decoding. Based on the lane segment representation framework, the model simultaneously predicts lanes, centrelines and their topology. To further enhance the ability of geometry prediction and topology reasoning, we also use a topology-guided decoder to refine the predictions by exploiting the mutual relationships between topological and geometric features. We perform extensive experiments on OpenLane-V2 datasets to validate the proposed method. The results show that our model outperforms state-of-the-art methods by a large margin, with gains of +6.7 and +9.1 on the mAP and topology metrics. Our analysis also reveals that models trained with SDMap noise augmentation exhibit enhanced robustness.
R-CoT: Reverse Chain-of-Thought Problem Generation for Geometric Reasoning in Large Multimodal Models
Oct 23, 2024



Existing Large Multimodal Models (LMMs) struggle with mathematical geometric reasoning due to a lack of high-quality image-text paired data. Current geometric data generation approaches, which apply preset templates to generate geometric data or use Large Language Models (LLMs) to rephrase questions and answers (Q&A), unavoidably limit data accuracy and diversity. To synthesize higher-quality data, we propose a two-stage Reverse Chain-of-Thought (R-CoT) geometry problem generation pipeline. First, we introduce GeoChain to produce high-fidelity geometric images and corresponding descriptions highlighting relations among geometric elements. We then design a Reverse A&Q method that reasons step-by-step based on the descriptions and generates questions in reverse from the reasoning results. Experiments demonstrate that the proposed method brings significant and consistent improvements on multiple LMM baselines, achieving new performance records in the 2B, 7B, and 8B settings. Notably, R-CoT-8B significantly outperforms previous state-of-the-art open-source mathematical models by 16.6% on MathVista and 9.2% on GeoQA, while also surpassing the closed-source model GPT-4o by an average of 13% across both datasets. The code is available at https://github.com/dle666/R-CoT.
TALK-Act: Enhance Textural-Awareness for 2D Speaking Avatar Reenactment with Diffusion Model
Oct 14, 2024

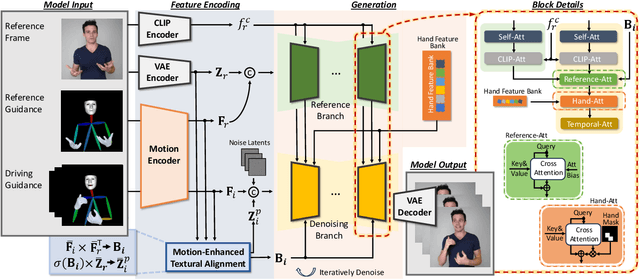

Recently, 2D speaking avatars have increasingly participated in everyday scenarios due to the fast development of facial animation techniques. However, most existing works neglect the explicit control of human bodies. In this paper, we propose to drive not only the faces but also the torso and gesture movements of a speaking figure. Inspired by recent advances in diffusion models, we propose the Motion-Enhanced Textural-Aware ModeLing for SpeaKing Avatar Reenactment (TALK-Act) framework, which enables high-fidelity avatar reenactment from only short footage of monocular video. Our key idea is to enhance the textural awareness with explicit motion guidance in diffusion modeling. Specifically, we carefully construct 2D and 3D structural information as intermediate guidance. While recent diffusion models adopt a side network for control information injection, they fail to synthesize temporally stable results even with person-specific fine-tuning. We propose a Motion-Enhanced Textural Alignment module to enhance the bond between driving and target signals. Moreover, we build a Memory-based Hand-Recovering module to help with the difficulties in hand-shape preserving. After pre-training, our model can achieve high-fidelity 2D avatar reenactment with only 30 seconds of person-specific data. Extensive experiments demonstrate the effectiveness and superiority of our proposed framework. Resources can be found at https://guanjz20.github.io/projects/TALK-Act.