 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Guided Exploratory Trajectory Optimization for Sampling-Based Model Predictive Control
Apr 13, 2026Trajectory optimization depends heavily on initialization. In particular, sampling-based approaches are highly sensitive to initial solutions, and limited exploration frequently leads them to converge to local minima in complex environments. We present Uncertainty Guided Exploratory Trajectory Optimization (UGE-TO), a trajectory optimization algorithm that generates well-separated samples to achieve a better coverage of the configuration space. UGE-TO represents trajectories as probability distributions induced by uncertainty ellipsoids. Unlike sampling-based approaches that explore only in the action space, this representation captures the effects of both system dynamics and action selection. By incorporating the impact of dynamics, in addition to the action space, into our distributions, our method enhances trajectory diversity by enforcing distributional separation via the Hellinger distance between them. It enables a systematic exploration of the configuration space and improves robustness against local minima. Further, we present UGE-MPC, which integrates UGE-TO into sampling-based model predictive controller methods. Experiments demonstrate that UGE-MPC achieves higher exploration and faster convergence in trajectory optimization compared to baselines under the same sampling budget, achieving 72.1% faster convergence in obstacle-free environments and 66% faster convergence with a 6.7% higher success rate in the cluttered environment compared to the best-performing baseline. Additionally, we validate the approach through a range of simulation scenarios and real-world experiments. Our results indicate that UGE-MPC has higher success rates and faster convergence, especially in environments that demand significant deviations from nominal trajectories to avoid failures. The project and code are available at https://ogpoyrazoglu.github.io/cuniform_sampling/.
HSImul3R: Physics-in-the-Loop Reconstruction of Simulation-Ready Human-Scene Interactions
Mar 16, 2026We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos. Existing methods suffer from a perception-simulation gap: visually plausible reconstructions often violate physical constraints, leading to instability in physics engines and failure in embodied AI applications. To bridge this gap, we introduce a physically-grounded bi-directional optimization pipeline that treats the physics simulator as an active supervisor to jointly refine human dynamics and scene geometry. In the forward direction, we employ Scene-targeted Reinforcement Learning to optimize human motion under dual supervision of motion fidelity and contact stability. In the reverse direction, we propose Direct Simulation Reward Optimization, which leverages simulation feedback on gravitational stability and interaction success to refine scene geometry. We further present HSIBench, a new benchmark with diverse objects and interaction scenarios. Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots.
Fast Navigation Through Occluded Spaces via Language-Conditioned Map Prediction
Dec 24, 2025In cluttered environments, motion planners often face a trade-off between safety and speed due to uncertainty caused by occlusions and limited sensor range. In this work, we investigate whether co-pilot instructions can help robots plan more decisively while remaining safe. We introduce PaceForecaster, as an approach that incorporates such co-pilot instructions into local planners. PaceForecaster takes the robot's local sensor footprint (Level-1) and the provided co-pilot instructions as input and predicts (i) a forecasted map with all regions visible from Level-1 (Level-2) and (ii) an instruction-conditioned subgoal within Level-2. The subgoal provides the planner with explicit guidance to exploit the forecasted environment in a goal-directed manner. We integrate PaceForecaster with a Log-MPPI controller and demonstrate that using language-conditioned forecasts and goals improves navigation performance by 36% over a local-map-only baseline while in polygonal environments.
IGGT: Instance-Grounded Geometry Transformer for Semantic 3D Reconstruction
Oct 26, 2025Humans naturally perceive the geometric structure and semantic content of a 3D world as intertwined dimensions, enabling coherent and accurate understanding of complex scenes. However, most prior approaches prioritize training large geometry models for low-level 3D reconstruction and treat high-level spatial understanding in isolation, overlooking the crucial interplay between these two fundamental aspects of 3D-scene analysis, thereby limiting generalization and leading to poor performance in downstream 3D understanding tasks. Recent attempts have mitigated this issue by simply aligning 3D models with specific language models, thus restricting perception to the aligned model's capacity and limiting adaptability to downstream tasks. In this paper, we propose InstanceGrounded Geometry Transformer (IGGT), an end-to-end large unified transformer to unify the knowledge for both spatial reconstruction and instance-level contextual understanding. Specifically, we design a 3D-Consistent Contrastive Learning strategy that guides IGGT to encode a unified representation with geometric structures and instance-grounded clustering through only 2D visual inputs. This representation supports consistent lifting of 2D visual inputs into a coherent 3D scene with explicitly distinct object instances. To facilitate this task, we further construct InsScene-15K, a large-scale dataset with high-quality RGB images, poses, depth maps, and 3D-consistent instance-level mask annotations with a novel data curation pipeline.
Splat4D: Diffusion-Enhanced 4D Gaussian Splatting for Temporally and Spatially Consistent Content Creation
Aug 11, 2025Generating high-quality 4D content from monocular videos for applications such as digital humans and AR/VR poses challenges in ensuring temporal and spatial consistency, preserving intricate details, and incorporating user guidance effectively. To overcome these challenges, we introduce Splat4D, a novel framework enabling high-fidelity 4D content generation from a monocular video. Splat4D achieves superior performance while maintaining faithful spatial-temporal coherence by leveraging multi-view rendering, inconsistency identification, a video diffusion model, and an asymmetric U-Net for refinement. Through extensive evaluations on public benchmarks, Splat4D consistently demonstrates state-of-the-art performance across various metrics, underscoring the efficacy of our approach. Additionally, the versatility of Splat4D is validated in various applications such as text/image conditioned 4D generation, 4D human generation, and text-guided content editing, producing coherent outcomes following user instructions.
Reconstructing 4D Spatial Intelligence: A Survey
Jul 28, 2025



Reconstructing 4D spatial intelligence from visual observations has long been a central yet challenging task in computer vision, with broad real-world applications. These range from entertainment domains like movies, where the focus is often on reconstructing fundamental visual elements, to embodied AI, which emphasizes interaction modeling and physical realism. Fueled by rapid advances in 3D representations and deep learning architectures, the field has evolved quickly, outpacing the scope of previous surveys. Additionally, existing surveys rarely offer a comprehensive analysis of the hierarchical structure of 4D scene reconstruction. To address this gap, we present a new perspective that organizes existing methods into five progressive levels of 4D spatial intelligence: (1) Level 1 -- reconstruction of low-level 3D attributes (e.g., depth, pose, and point maps); (2) Level 2 -- reconstruction of 3D scene components (e.g., objects, humans, structures); (3) Level 3 -- reconstruction of 4D dynamic scenes; (4) Level 4 -- modeling of interactions among scene components; and (5) Level 5 -- incorporation of physical laws and constraints. We conclude the survey by discussing the key challenges at each level and highlighting promising directions for advancing toward even richer levels of 4D spatial intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/yukangcao/Awesome-4D-Spatial-Intelligence.
FreeMorph: Tuning-Free Generalized Image Morphing with Diffusion Model
Jul 02, 2025



We present FreeMorph, the first tuning-free method for image morphing that accommodates inputs with different semantics or layouts. Unlike existing methods that rely on finetuning pre-trained diffusion models and are limited by time constraints and semantic/layout discrepancies, FreeMorph delivers high-fidelity image morphing without requiring per-instance training. Despite their efficiency and potential, tuning-free methods face challenges in maintaining high-quality results due to the non-linear nature of the multi-step denoising process and biases inherited from the pre-trained diffusion model. In this paper, we introduce FreeMorph to address these challenges by integrating two key innovations. 1) We first propose a guidance-aware spherical interpolation design that incorporates explicit guidance from the input images by modifying the self-attention modules, thereby addressing identity loss and ensuring directional transitions throughout the generated sequence. 2) We further introduce a step-oriented variation trend that blends self-attention modules derived from each input image to achieve controlled and consistent transitions that respect both inputs. Our extensive evaluations demonstrate that FreeMorph outperforms existing methods, being 10x ~ 50x faster and establishing a new state-of-the-art for image morphing.
AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Mar 25, 2025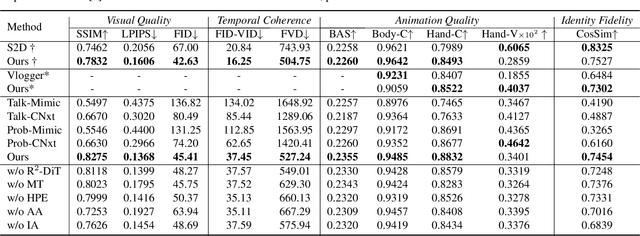
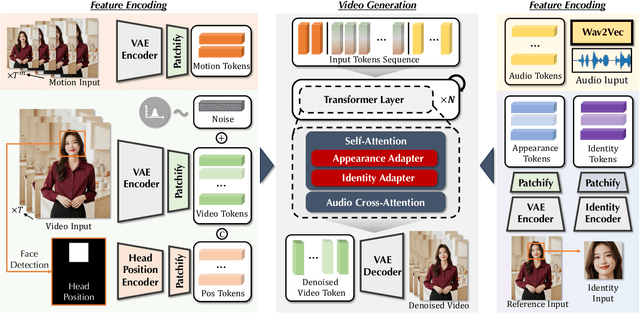
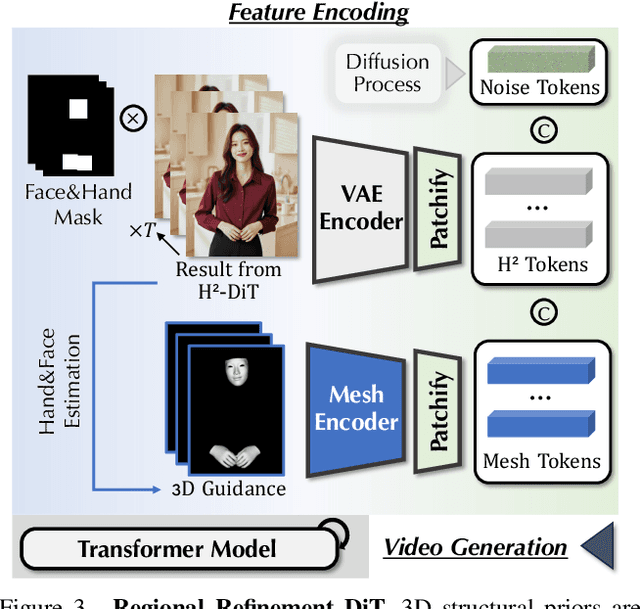

Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
AvatarGO: Zero-shot 4D Human-Object Interaction Generation and Animation
Oct 09, 2024



Recent advancements in diffusion models have led to significant improvements in the generation and animation of 4D full-body human-object interactions (HOI). Nevertheless, existing methods primarily focus on SMPL-based motion generation, which is limited by the scarcity of realistic large-scale interaction data. This constraint affects their ability to create everyday HOI scenes. This paper addresses this challenge using a zero-shot approach with a pre-trained diffusion model. Despite this potential, achieving our goals is difficult due to the diffusion model's lack of understanding of ''where'' and ''how'' objects interact with the human body. To tackle these issues, we introduce AvatarGO, a novel framework designed to generate animatable 4D HOI scenes directly from textual inputs. Specifically, 1) for the ''where'' challenge, we propose LLM-guided contact retargeting, which employs Lang-SAM to identify the contact body part from text prompts, ensuring precise representation of human-object spatial relations. 2) For the ''how'' challenge, we introduce correspondence-aware motion optimization that constructs motion fields for both human and object models using the linear blend skinning function from SMPL-X. Our framework not only generates coherent compositional motions, but also exhibits greater robustness in handling penetration issues. Extensive experiments with existing methods validate AvatarGO's superior generation and animation capabilities on a variety of human-object pairs and diverse poses. As the first attempt to synthesize 4D avatars with object interactions, we hope AvatarGO could open new doors for human-centric 4D content creation.
GS-VTON: Controllable 3D Virtual Try-on with Gaussian Splatting
Oct 07, 2024
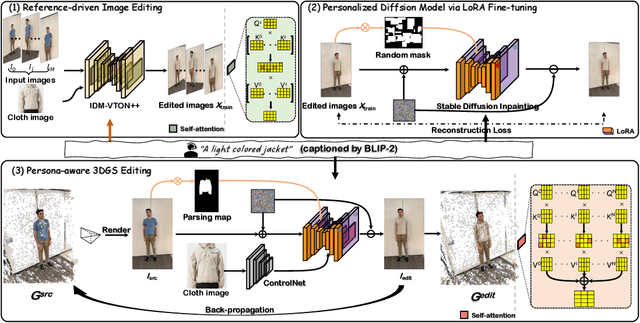


Diffusion-based 2D virtual try-on (VTON) techniques have recently demonstrated strong performance, while the development of 3D VTON has largely lagged behind. Despite recent advances in text-guided 3D scene editing, integrating 2D VTON into these pipelines to achieve vivid 3D VTON remains challenging. The reasons are twofold. First, text prompts cannot provide sufficient details in describing clothing. Second, 2D VTON results generated from different viewpoints of the same 3D scene lack coherence and spatial relationships, hence frequently leading to appearance inconsistencies and geometric distortions. To resolve these problems, we introduce an image-prompted 3D VTON method (dubbed GS-VTON) which, by leveraging 3D Gaussian Splatting (3DGS) as the 3D representation, enables the transfer of pre-trained knowledge from 2D VTON models to 3D while improving cross-view consistency. (1) Specifically, we propose a personalized diffusion model that utilizes low-rank adaptation (LoRA) fine-tuning to incorporate personalized information into pre-trained 2D VTON models. To achieve effective LoRA training, we introduce a reference-driven image editing approach that enables the simultaneous editing of multi-view images while ensuring consistency. (2) Furthermore, we propose a persona-aware 3DGS editing framework to facilitate effective editing while maintaining consistent cross-view appearance and high-quality 3D geometry. (3) Additionally, we have established a new 3D VTON benchmark, 3D-VTONBench, which facilitates comprehensive qualitative and quantitative 3D VTON evaluations. Through extensive experiments and comparative analyses with existing methods, the proposed \OM has demonstrated superior fidelity and advanced editing capabilities, affirming its effectiveness for 3D VTON.