 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgSora: Decoupled RGBD-Flow Diffusion Model for Controllable Surgical Video Generation
Dec 18, 2024Medical video generation has transformative potential for enhancing surgical understanding and pathology insights through precise and controllable visual representations. However, current models face limitations in controllability and authenticity. To bridge this gap, we propose SurgSora, a motion-controllable surgical video generation framework that uses a single input frame and user-controllable motion cues. SurgSora consists of three key modules: the Dual Semantic Injector (DSI), which extracts object-relevant RGB and depth features from the input frame and integrates them with segmentation cues to capture detailed spatial features of complex anatomical structures; the Decoupled Flow Mapper (DFM), which fuses optical flow with semantic-RGB-D features at multiple scales to enhance temporal understanding and object spatial dynamics; and the Trajectory Controller (TC), which allows users to specify motion directions and estimates sparse optical flow, guiding the video generation process. The fused features are used as conditions for a frozen Stable Diffusion model to produce realistic, temporally coherent surgical videos. Extensive evaluations demonstrate that SurgSora outperforms state-of-the-art methods in controllability and authenticity, showing its potential to advance surgical video generation for medical education, training, and research.
ArtiFade: Learning to Generate High-quality Subject from Blemished Images
Sep 05, 2024

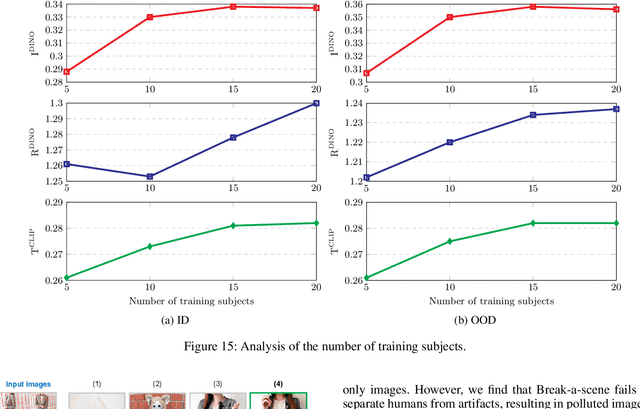
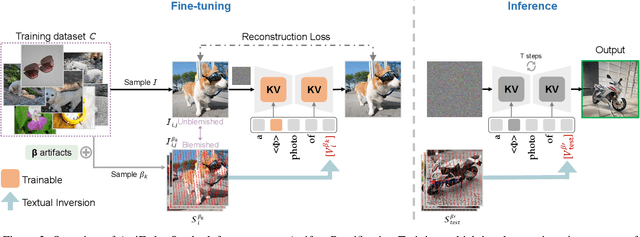
Subject-driven text-to-image generation has witnessed remarkable advancements in its ability to learn and capture characteristics of a subject using only a limited number of images. However, existing methods commonly rely on high-quality images for training and may struggle to generate reasonable images when the input images are blemished by artifacts. This is primarily attributed to the inadequate capability of current techniques in distinguishing subject-related features from disruptive artifacts. In this paper, we introduce ArtiFade to tackle this issue and successfully generate high-quality artifact-free images from blemished datasets. Specifically, ArtiFade exploits fine-tuning of a pre-trained text-to-image model, aiming to remove artifacts. The elimination of artifacts is achieved by utilizing a specialized dataset that encompasses both unblemished images and their corresponding blemished counterparts during fine-tuning. ArtiFade also ensures the preservation of the original generative capabilities inherent within the diffusion model, thereby enhancing the overall performance of subject-driven methods in generating high-quality and artifact-free images. We further devise evaluation benchmarks tailored for this task. Through extensive qualitative and quantitative experiments, we demonstrate the generalizability of ArtiFade in effective artifact removal under both in-distribution and out-of-distribution scenarios.