 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnison: A Fully Automatic, Task-Universal, and Low-Cost Framework for Unified Understanding and Generation
Dec 08, 2025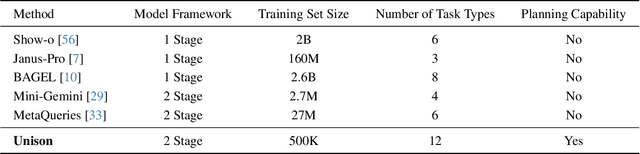
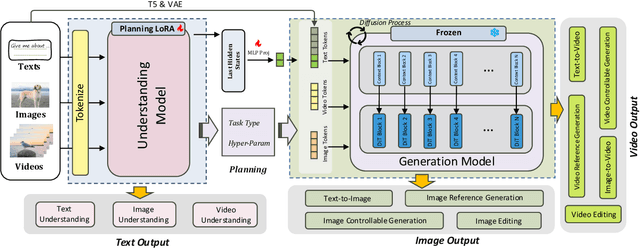


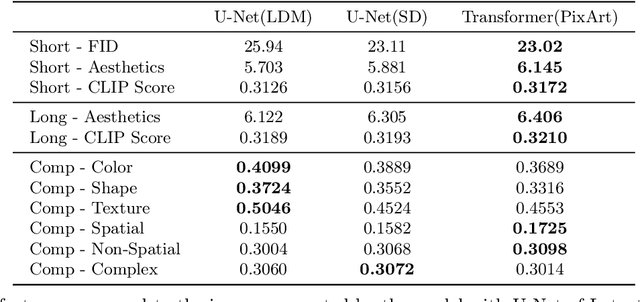
Unified understanding and generation is a highly appealing research direction in multimodal learning. There exist two approaches: one trains a transformer via an auto-regressive paradigm, and the other adopts a two-stage scheme connecting pre-trained understanding and generative models for alignment fine-tuning. The former demands massive data and computing resources unaffordable for ordinary researchers. Though the latter requires a lower training cost, existing works often suffer from limited task coverage or poor generation quality. Both approaches lack the ability to parse input meta-information (such as task type, image resolution, video duration, etc.) and require manual parameter configuration that is tedious and non-intelligent. In this paper, we propose Unison which adopts the two-stage scheme while preserving the capabilities of the pre-trained models well. With an extremely low training cost, we cover a variety of multimodal understanding tasks, including text, image, and video understanding, as well as diverse generation tasks, such as text-to-visual content generation, editing, controllable generation, and IP-based reference generation. We also equip our model with the ability to automatically parse user intentions, determine the target task type, and accurately extract the meta-information required for the corresponding task. This enables full automation of various multimodal tasks without human intervention. Experiments demonstrate that, under a low-cost setting of only 500k training samples and 50 GPU hours, our model can accurately and automatically identify tasks and extract relevant parameters, and achieve superior performance across a variety of understanding and generation tasks.
NTIRE 2025 Challenge on UGC Video Enhancement: Methods and Results
May 05, 2025This paper presents an overview of the NTIRE 2025 Challenge on UGC Video Enhancement. The challenge constructed a set of 150 user-generated content videos without reference ground truth, which suffer from real-world degradations such as noise, blur, faded colors, compression artifacts, etc. The goal of the participants was to develop an algorithm capable of improving the visual quality of such videos. Given the widespread use of UGC on short-form video platforms, this task holds substantial practical importance. The evaluation was based on subjective quality assessment in crowdsourcing, obtaining votes from over 8000 assessors. The challenge attracted more than 25 teams submitting solutions, 7 of which passed the final phase with source code verification. The outcomes may provide insights into the state-of-the-art in UGC video enhancement and highlight emerging trends and effective strategies in this evolving research area. All data, including the processed videos and subjective comparison votes and scores, is made publicly available at https://github.com/msu-video-group/NTIRE25_UGC_Video_Enhancement.
Señorita-2M: A High-Quality Instruction-based Dataset for General Video Editing by Video Specialists
Feb 10, 2025



Recent advancements in video generation have spurred the development of video editing techniques, which can be divided into inversion-based and end-to-end methods. However, current video editing methods still suffer from several challenges. Inversion-based methods, though training-free and flexible, are time-consuming during inference, struggle with fine-grained editing instructions, and produce artifacts and jitter. On the other hand, end-to-end methods, which rely on edited video pairs for training, offer faster inference speeds but often produce poor editing results due to a lack of high-quality training video pairs. In this paper, to close the gap in end-to-end methods, we introduce Se\~norita-2M, a high-quality video editing dataset. Se\~norita-2M consists of approximately 2 millions of video editing pairs. It is built by crafting four high-quality, specialized video editing models, each crafted and trained by our team to achieve state-of-the-art editing results. We also propose a filtering pipeline to eliminate poorly edited video pairs. Furthermore, we explore common video editing architectures to identify the most effective structure based on current pre-trained generative model. Extensive experiments show that our dataset can help to yield remarkably high-quality video editing results. More details are available at https://senorita.github.io.
Elucidating the design space of language models for image generation
Oct 21, 2024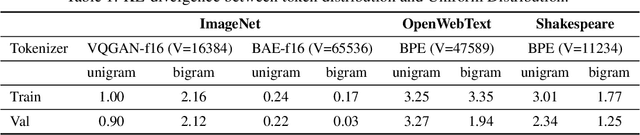
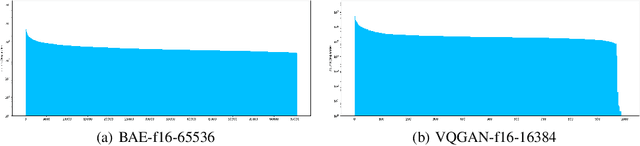
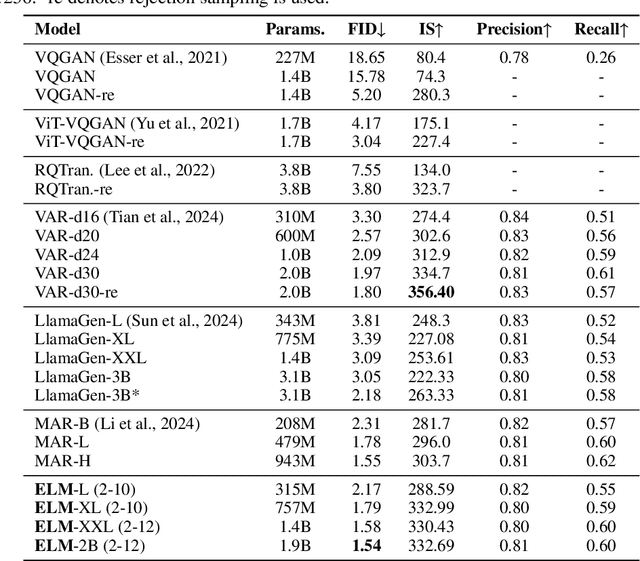
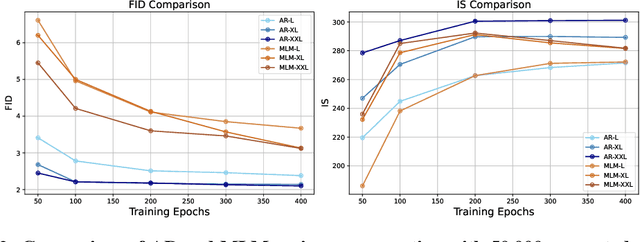
The success of autoregressive (AR) language models in text generation has inspired the computer vision community to adopt Large Language Models (LLMs) for image generation. However, considering the essential differences between text and image modalities, the design space of language models for image generation remains underexplored. We observe that image tokens exhibit greater randomness compared to text tokens, which presents challenges when training with token prediction. Nevertheless, AR models demonstrate their potential by effectively learning patterns even from a seemingly suboptimal optimization problem. Our analysis also reveals that while all models successfully grasp the importance of local information in image generation, smaller models struggle to capture the global context. In contrast, larger models showcase improved capabilities in this area, helping to explain the performance gains achieved when scaling up model size. We further elucidate the design space of language models for vision generation, including tokenizer choice, model choice, model scalability, vocabulary design, and sampling strategy through extensive comparative experiments. Our work is the first to analyze the optimization behavior of language models in vision generation, and we believe it can inspire more effective designs when applying LMs to other domains. Finally, our elucidated language model for image generation, termed as ELM, achieves state-of-the-art performance on the ImageNet 256*256 benchmark. The code is available at https://github.com/Pepperlll/LMforImageGeneration.git.
BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities
Oct 18, 2024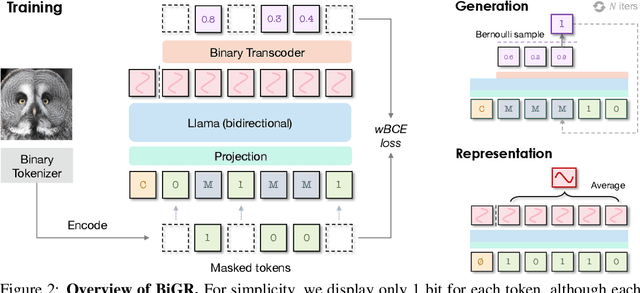
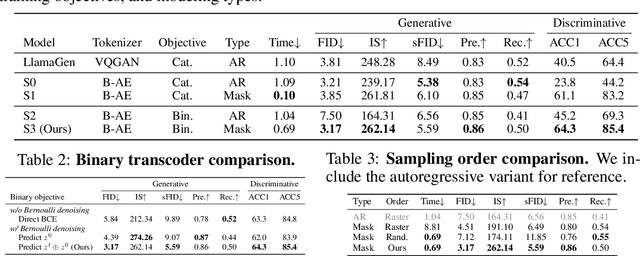
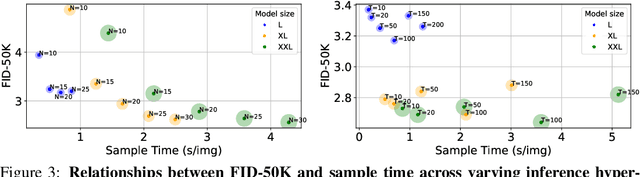
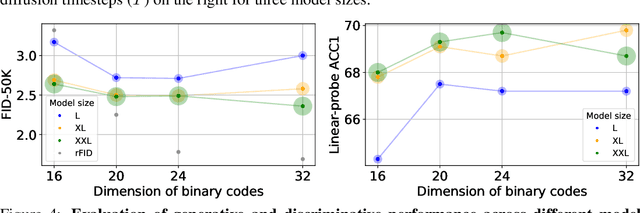
We introduce BiGR, a novel conditional image generation model using compact binary latent codes for generative training, focusing on enhancing both generation and representation capabilities. BiGR is the first conditional generative model that unifies generation and discrimination within the same framework. BiGR features a binary tokenizer, a masked modeling mechanism, and a binary transcoder for binary code prediction. Additionally, we introduce a novel entropy-ordered sampling method to enable efficient image generation. Extensive experiments validate BiGR's superior performance in generation quality, as measured by FID-50k, and representation capabilities, as evidenced by linear-probe accuracy. Moreover, BiGR showcases zero-shot generalization across various vision tasks, enabling applications such as image inpainting, outpainting, editing, interpolation, and enrichment, without the need for structural modifications. Our findings suggest that BiGR unifies generative and discriminative tasks effectively, paving the way for further advancements in the field.
CusConcept: Customized Visual Concept Decomposition with Diffusion Models
Oct 01, 2024


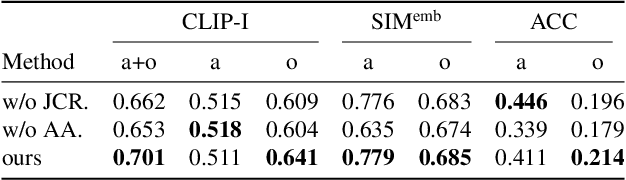
Enabling generative models to decompose visual concepts from a single image is a complex and challenging problem. In this paper, we study a new and challenging task, customized concept decomposition, wherein the objective is to leverage diffusion models to decompose a single image and generate visual concepts from various perspectives. To address this challenge, we propose a two-stage framework, CusConcept (short for Customized Visual Concept Decomposition), to extract customized visual concept embedding vectors that can be embedded into prompts for text-to-image generation. In the first stage, CusConcept employs a vocabulary-guided concept decomposition mechanism to build vocabularies along human-specified conceptual axes. The decomposed concepts are obtained by retrieving corresponding vocabularies and learning anchor weights. In the second stage, joint concept refinement is performed to enhance the fidelity and quality of generated images. We further curate an evaluation benchmark for assessing the performance of the open-world concept decomposition task. Our approach can effectively generate high-quality images of the decomposed concepts and produce related lexical predictions as secondary outcomes. Extensive qualitative and quantitative experiments demonstrate the effectiveness of CusConcept.
ArtiFade: Learning to Generate High-quality Subject from Blemished Images
Sep 05, 2024

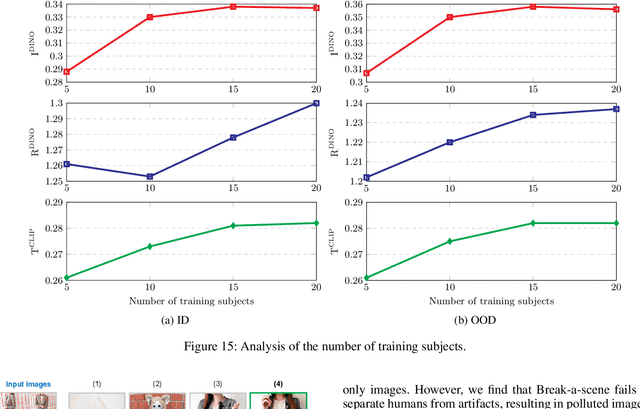
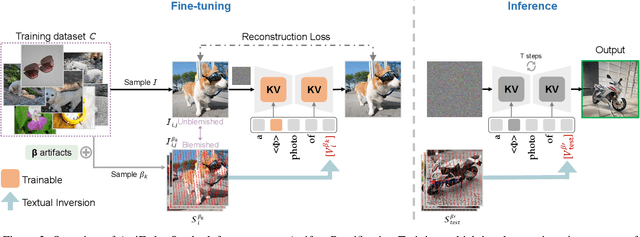
Subject-driven text-to-image generation has witnessed remarkable advancements in its ability to learn and capture characteristics of a subject using only a limited number of images. However, existing methods commonly rely on high-quality images for training and may struggle to generate reasonable images when the input images are blemished by artifacts. This is primarily attributed to the inadequate capability of current techniques in distinguishing subject-related features from disruptive artifacts. In this paper, we introduce ArtiFade to tackle this issue and successfully generate high-quality artifact-free images from blemished datasets. Specifically, ArtiFade exploits fine-tuning of a pre-trained text-to-image model, aiming to remove artifacts. The elimination of artifacts is achieved by utilizing a specialized dataset that encompasses both unblemished images and their corresponding blemished counterparts during fine-tuning. ArtiFade also ensures the preservation of the original generative capabilities inherent within the diffusion model, thereby enhancing the overall performance of subject-driven methods in generating high-quality and artifact-free images. We further devise evaluation benchmarks tailored for this task. Through extensive qualitative and quantitative experiments, we demonstrate the generalizability of ArtiFade in effective artifact removal under both in-distribution and out-of-distribution scenarios.
ConceptExpress: Harnessing Diffusion Models for Single-image Unsupervised Concept Extraction
Jul 09, 2024



While personalized text-to-image generation has enabled the learning of a single concept from multiple images, a more practical yet challenging scenario involves learning multiple concepts within a single image. However, existing works tackling this scenario heavily rely on extensive human annotations. In this paper, we introduce a novel task named Unsupervised Concept Extraction (UCE) that considers an unsupervised setting without any human knowledge of the concepts. Given an image that contains multiple concepts, the task aims to extract and recreate individual concepts solely relying on the existing knowledge from pretrained diffusion models. To achieve this, we present ConceptExpress that tackles UCE by unleashing the inherent capabilities of pretrained diffusion models in two aspects. Specifically, a concept localization approach automatically locates and disentangles salient concepts by leveraging spatial correspondence from diffusion self-attention; and based on the lookup association between a concept and a conceptual token, a concept-wise optimization process learns discriminative tokens that represent each individual concept. Finally, we establish an evaluation protocol tailored for the UCE task. Extensive experiments demonstrate that ConceptExpress is a promising solution to the UCE task. Our code and data are available at: https://github.com/haoosz/ConceptExpress
Bridging Different Language Models and Generative Vision Models for Text-to-Image Generation
Mar 12, 2024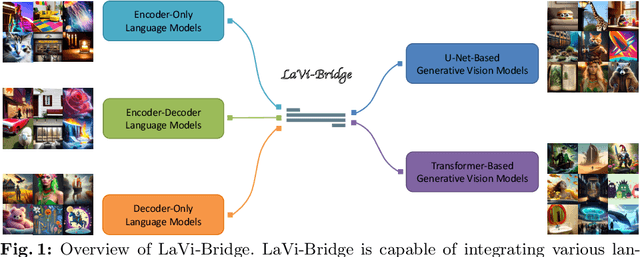
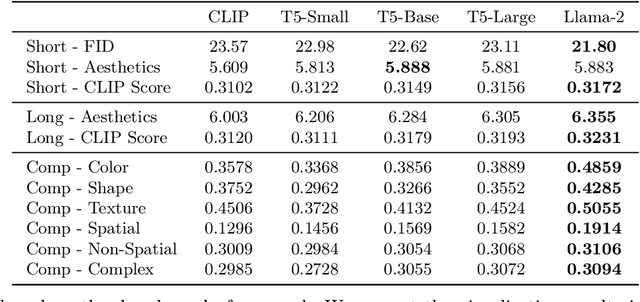
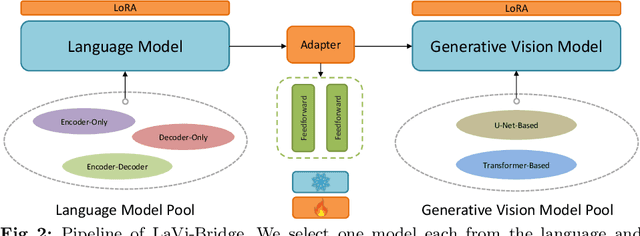
Text-to-image generation has made significant advancements with the introduction of text-to-image diffusion models. These models typically consist of a language model that interprets user prompts and a vision model that generates corresponding images. As language and vision models continue to progress in their respective domains, there is a great potential in exploring the replacement of components in text-to-image diffusion models with more advanced counterparts. A broader research objective would therefore be to investigate the integration of any two unrelated language and generative vision models for text-to-image generation. In this paper, we explore this objective and propose LaVi-Bridge, a pipeline that enables the integration of diverse pre-trained language models and generative vision models for text-to-image generation. By leveraging LoRA and adapters, LaVi-Bridge offers a flexible and plug-and-play approach without requiring modifications to the original weights of the language and vision models. Our pipeline is compatible with various language models and generative vision models, accommodating different structures. Within this framework, we demonstrate that incorporating superior modules, such as more advanced language models or generative vision models, results in notable improvements in capabilities like text alignment or image quality. Extensive evaluations have been conducted to verify the effectiveness of LaVi-Bridge. Code is available at https://github.com/ShihaoZhaoZSH/LaVi-Bridge.
ViCo: Detail-Preserving Visual Condition for Personalized Text-to-Image Generation
Jun 01, 2023

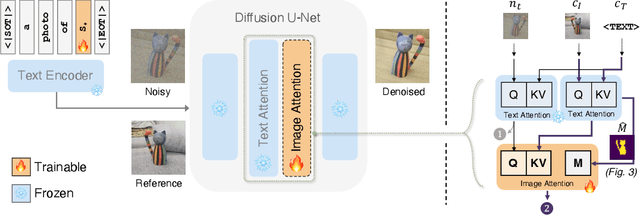

Personalized text-to-image generation using diffusion models has recently been proposed and attracted lots of attention. Given a handful of images containing a novel concept (e.g., a unique toy), we aim to tune the generative model to capture fine visual details of the novel concept and generate photorealistic images following a text condition. We present a plug-in method, named ViCo, for fast and lightweight personalized generation. Specifically, we propose an image attention module to condition the diffusion process on the patch-wise visual semantics. We introduce an attention-based object mask that comes almost at no cost from the attention module. In addition, we design a simple regularization based on the intrinsic properties of text-image attention maps to alleviate the common overfitting degradation. Unlike many existing models, our method does not finetune any parameters of the original diffusion model. This allows more flexible and transferable model deployment. With only light parameter training (~6% of the diffusion U-Net), our method achieves comparable or even better performance than all state-of-the-art models both qualitatively and quantitatively.