 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Different Language Models and Generative Vision Models for Text-to-Image Generation
Mar 12, 2024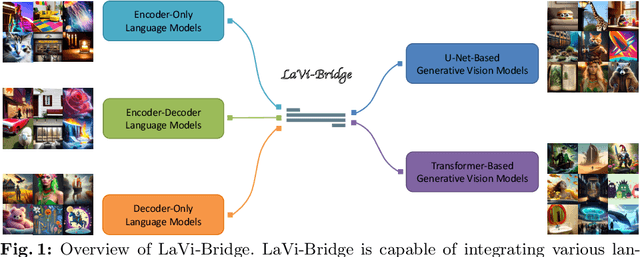
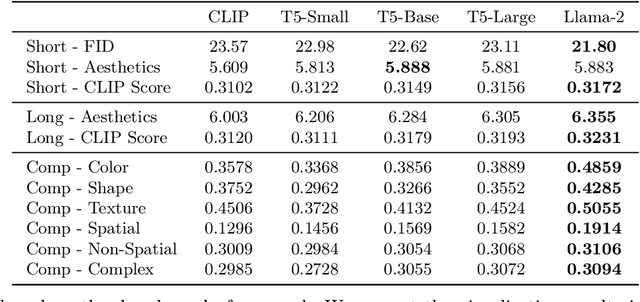
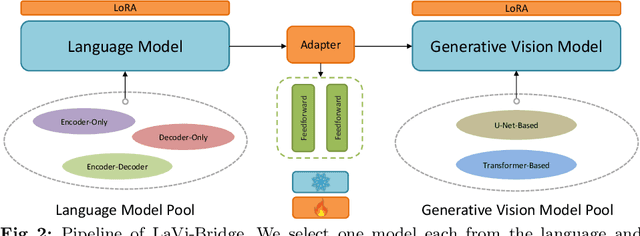
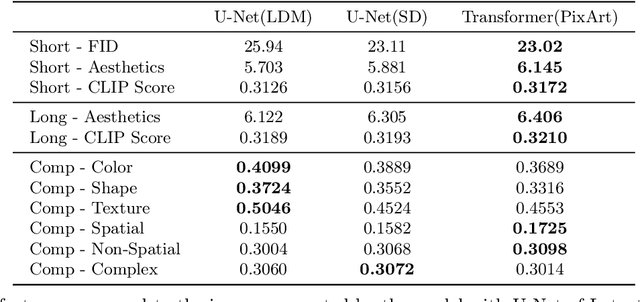
Text-to-image generation has made significant advancements with the introduction of text-to-image diffusion models. These models typically consist of a language model that interprets user prompts and a vision model that generates corresponding images. As language and vision models continue to progress in their respective domains, there is a great potential in exploring the replacement of components in text-to-image diffusion models with more advanced counterparts. A broader research objective would therefore be to investigate the integration of any two unrelated language and generative vision models for text-to-image generation. In this paper, we explore this objective and propose LaVi-Bridge, a pipeline that enables the integration of diverse pre-trained language models and generative vision models for text-to-image generation. By leveraging LoRA and adapters, LaVi-Bridge offers a flexible and plug-and-play approach without requiring modifications to the original weights of the language and vision models. Our pipeline is compatible with various language models and generative vision models, accommodating different structures. Within this framework, we demonstrate that incorporating superior modules, such as more advanced language models or generative vision models, results in notable improvements in capabilities like text alignment or image quality. Extensive evaluations have been conducted to verify the effectiveness of LaVi-Bridge. Code is available at https://github.com/ShihaoZhaoZSH/LaVi-Bridge.
Visual In-Context Prompting
Nov 22, 2023In-context prompting in large language models (LLMs) has become a prevalent approach to improve zero-shot capabilities, but this idea is less explored in the vision domain. Existing visual prompting methods focus on referring segmentation to segment the most relevant object, falling short of addressing many generic vision tasks like open-set segmentation and detection. In this paper, we introduce a universal visual in-context prompting framework for both tasks. In particular, we build on top of an encoder-decoder architecture, and develop a versatile prompt encoder to support a variety of prompts like strokes, boxes, and points. We further enhance it to take an arbitrary number of reference image segments as the context. Our extensive explorations show that the proposed visual in-context prompting elicits extraordinary referring and generic segmentation capabilities to refer and detect, yielding competitive performance to close-set in-domain datasets and showing promising results on many open-set segmentation datasets. By joint training on COCO and SA-1B, our model achieves $57.7$ PQ on COCO and $23.2$ PQ on ADE20K. Code will be available at https://github.com/UX-Decoder/DINOv.
MP-Former: Mask-Piloted Transformer for Image Segmentation
Mar 15, 2023We present a mask-piloted Transformer which improves masked-attention in Mask2Former for image segmentation. The improvement is based on our observation that Mask2Former suffers from inconsistent mask predictions between consecutive decoder layers, which leads to inconsistent optimization goals and low utilization of decoder queries. To address this problem, we propose a mask-piloted training approach, which additionally feeds noised ground-truth masks in masked-attention and trains the model to reconstruct the original ones. Compared with the predicted masks used in mask-attention, the ground-truth masks serve as a pilot and effectively alleviate the negative impact of inaccurate mask predictions in Mask2Former. Based on this technique, our \M achieves a remarkable performance improvement on all three image segmentation tasks (instance, panoptic, and semantic), yielding $+2.3$AP and $+1.6$mIoU on the Cityscapes instance and semantic segmentation tasks with a ResNet-50 backbone. Our method also significantly speeds up the training, outperforming Mask2Former with half of the number of training epochs on ADE20K with both a ResNet-50 and a Swin-L backbones. Moreover, our method only introduces little computation during training and no extra computation during inference. Our code will be released at \url{https://github.com/IDEA-Research/MP-Former}.